 3
3 2
2


- 性能测试必知必会
说到性能测试,我们到底是想谈论什么?
任何做产品的,都希望自己家的产品,品质优,性能好,服务海量用户,还不出问题。
任何使用产品的,都喜欢自己购买的产品功能全,性能优,不花一分冤枉钱。
不过理想很丰满,现实很骨感。实际产品的性能与开发周期,部署方式,软硬件性能等都息息相关。所以真正提到做性能测试的场景,多数是为满足特定需求而进行的度量或调优。
比如:
针对交付客户的软硬件环境,提供性能测试报告,证明对客户需求的满足
针对特定的性能瓶颈,进行针对性测试,为问题定位提供帮助
重大功能迭代,架构设计上线前的性能评估
所有的这些场景,都隐含着对性能测试目标的确认,这一点非常重要。因为如果没有明确的测试目标,为了做而做,多数情况是没有价值的,浪费精力。
而性能测试的目标一般是期望支持的目标用户数量,负载,QPS等等,这些信息一般可以从业务负责人或者产品经理处获得。当然如果有实际的业务数据支持,也可以据此分析得出。所以在开展性能测试之前,一定要先搞清楚测试目标。
目标明确之后,如何开展性能测试?
有了性能测试目标,之后还需要进一步拆解,做到具体可执行。根据经验,个人认为性能测试的执行,最终会落地到以下两个场景:
在特定硬件条件,特定部署架构下,测试系统的最大性能表现
在相同场景,相同硬件配置下,与竞品比较,与过往分析,总结出优劣
不同的目的,做事的方式也不一样。
第一类场景,因为结果的不确定性,测试时需要不断的探索测试矩阵,找出尽可能优的结果。
第二类场景,首先需要理清楚,业界同类产品,到底比的是什么,相应的测试工具是什么,测试方法是什么。总之要在公平公正的条件下,遵循业界标准,得出测试结果,给出结论。
所有的性能测试场景,都需要有明确的分析与结论,以支持上述两个场景下的目的达成。测试场景要贴近实际的目标场景,测试数据要贴近实际的业务数据,最好就用目标业务场景下的数据来进行性能测试。
服务端性能测试到底要看哪些指标?
不同的领域,业务形态,可能关注的性能指标是不一样的,所以为了表述精确,我们这里只谈服务端的性能测试指标。
一般我们会用以下指标来衡量被测业务: QPS, 响应时间(Latency), 成功率,吞吐率,以及服务端的资源利用率(CPU/Memory/IOPS/句柄等)。
不过,这里有一些常识需要明确:
响应时间不要用平均值,要用百分值。比如常见的,98值(98th percentile)表示。
成功率是性能数据采集标准的前提,在成功率不足的情况下,其他的性能数据是没意义的(当然这时候可以基于失败请求来分析性能瓶颈)。
单独说QPS不够精确,而应结合响应时间综合来看。比如 "在响应时间TP98都小于100ms情况下,系统可以达到10000qps" 这才有意义。
性能测试一定要持续一定时间,在确保被测业务稳定的情况下,测出的数据才有意义。
要多体会下这些常识,实战中很多新手对这块理解不深,导致有时出的性能数据基本是无效的。
为什么性能测试报告一定要给出明确的软硬件配置,以及部署方式?
前面说到,性能数据是与软件版本,硬件配置,部署方式等息息相关的。每一项指标的不同,得出的数据可能是天差万别。所以在做性能测试时,一定要明确这些基础前置条件,且在后期的性能测试报告中,清晰的说明。
jmeter, ab, wrk, lotust, k6 这么多性能测试工具,我应该选择哪个?
业界性能测试数据工具非常多,不过适用的场景,以及各自特点会有不同。所以针对不同的性能测试需求,应当选择合适的性能工具。比如:
jmeter: 主要提供图形化操作以及录制功能,入门简单,功能也较强大。缺点是需要额外安装。
ab(apech benchmark): 简单好用,且一般系统内置了,应对简单场景已足够
lotust:简单好用,支持python编写自定义脚本,支持多worker,图形化界面汇总性能数据。
这里不一一介绍工具,大家有兴趣的都可以自行去网上搜索。
其实笔者在实践过程中发现,其实绝大多数性能测试场景,都需要编码实现。所以如何优雅的结合现有的测试代码,环境,以及基础设施,来方便的进行性能测试反而是个可以考量的点。
笔者比较认可Go+Prometheus+Kubernetes的模式。首先go语言因其独有的并发模式,上手简单等特点,在云服务,服务端程序领域使用已经非常广了,采用其写脚本,也许与被测程序天然紧密结合。且服务端程序要想很好的运维,必然有一套完整的监控告警体系,而Prometheus基本是其中热度最高的,使用范围最广的,同时我们也可以将测试程序性能数据打点到Prometheus,这样在计算QPS,成功率等指标上,非常方便。
另外大家知道,在性能测试时,多数需要不断的调整metrix,比如并发数,worker数量等,来探测系统的性能表现,这时候如果将测试程序跑在Kubernetes上,就可以借助其能力,比如Deployment,灵活的部署和水平扩展,体验相当优雅。
单机10000并发为什么可能不靠谱?
我们知道使用goroutine,可以瞬间开很多并发,非常好用。于是可能就会有同学觉得用它做性能测试很方便,直接写个脚本,起超多的并发,去做性能测试。但这样真的靠谱吗?
虽然go语言的并发,通过P,G,M模型,在调度goroutine时,比较高效,但无论如何,任何的程序执行,最终消耗的都是系统资源,测试脚本也同样。所以单机上执行的并发效果,最终会受限于,你脚本的复杂程序,也就是对CPU,IO,网络等系统资源的消耗。所以,并不是并发越多越好,一定是基于实际环境,通过不断调节并发数量,worker数量等,来达到最佳姿势。
构建业务性能数据的持续可观测性对产品质量意义重大
一次专项性的性能分析,可以观察当前业务的性能表现,进一步的分析性能瓶颈,为之后的改进提供帮助,意义挺大。但只这样可能不够全面,因为指不定的某次迭代,句柄没关,goutinue泄露,就会造成性能问题,如果我们没有常态化的检测手段,等上线后才发现,很明显不是我们想看到的。
所以更优雅的做法是,将性能测试常态化的持续运营,甚至可以做到每次PR触发,都自动执行性能测试,检测性能问题。
作者:大卡尔
原文链接:https://www.cnblogs.com/jinsdu/p/10646278.html
- 0.00 查看剩余0%
- 【留下美好印记】赞赏支持

热门文章
最新讲堂
- 推荐阅读
- 换一换
- 11月2日晚,华为发布上下折的折叠手机新品,把价格下探到6000元以下。“符合之前判断,这是折叠手机价格下探的一个契机点。”群智咨询副总经理、首席分析师陈军向第一财经记者分析说,这意味着折叠手机普及上量的速度在加快。今年预计全球折叠手机的出货量将达1400万台,明年将进一步翻倍增至3000台,背后是价格持续下探。陈军说,折叠手机价格持续下探的背后,是铰链、盖板等配件的价格逐步走低,折叠手机整个供应链逐步走向成熟。从市场整体竞争格局看,陈军认为,明年初折叠手机仍在4000元档以上,仍以华为、三星为主要玩家,国内市场OPPO、vivo、小米的份额也会走高,这也是一个明显的趋势。“对显示面板行业来讲...
-
- 压力测试流程——软件测试圈08-03一、压测流程可参照上篇压测对抗流程二、压测需求需要明确需要压测的环境需要压测的接口,其中包含接口的入参需要明确接口的预计qps需要明确线上机器配置三、压测准备3.1、服务端开发准备:1.根据需要测试的接口,决定需要部署哪些相关依赖服务2.测试接口对应的服务、接口3.相关配置4.相关数据库5.需要的机器整理,其中包含机器的配置,需要几台机器3.2、前端开发准备:1.测试的接口和服务应用2.域名3.需要准备的机器4.根据需要测试的接口,决定要部署哪些相关依赖3.3、测试准备:1.准备压测的测试方案和测试计划2.通过接口确认压测的场景,其中包含每一个接口需要测试的场景,预计接口需要的压测线程。通过测...
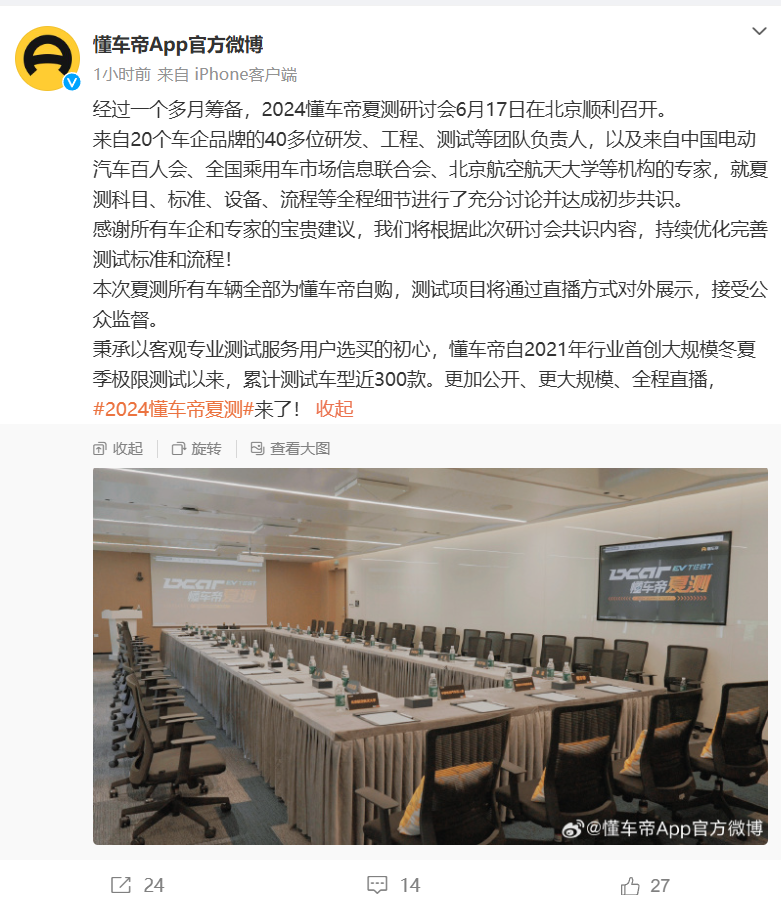
- 2023 年底,懂车帝“冬测”争议事件在全网引发热议,包括华为、长城汽车、吉利均对测试标准表示质疑。余承东还称“某些媒体的冬季测试非常具有随意性、创造性”,并称测试“不专业”。 时隔半年,懂车帝 App 官方微博今日宣布,经过一个多月筹备,2024 懂车帝夏测研讨会 6 月 17 日在北京顺利召开。“本次夏测所有车辆全部为懂车帝自购,测试项目将通过直播方式对外展示,接受公众监督。” 懂车帝还称:“来自 20 个车企品牌的 40 多位研发、工程、测试等团队负责人,以及来自中国电动汽车百人会、全国乘用车市场信息联合会、北京航空航天大学等机构的专家,就夏测科目、标准、设备、流程等全程细节进行...
-
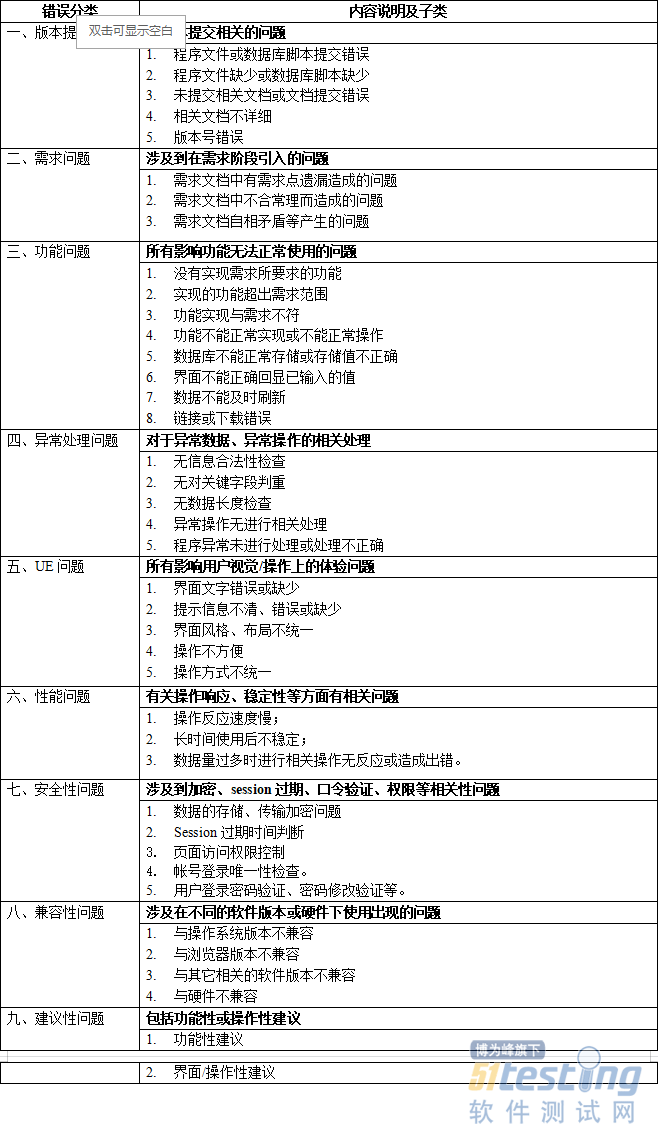
- 测试必会:BUG的分类及推进解决——软件测试圈09-16有一些初始的小测试团队,对BUG单可能会进行重要程度的划分,但并不会进行类型划分,其实,如果不对BUG进行错误类型定义,项目经理或测试经理并不好确认后续质量提升在哪方面进行改进,具体研发的哪个环节更需要进行改进。故此合理的对BUG单进行分类也是提交BUG的前提。以下是我整理的BUG类型分类情况: 进行BUG类型分类仅是第一步,作为WEB类的项目,一般情况下,明面上的二、三类问题,自测时容易发现且会完成修改,留到测试去提出的机率相对会少一点;而其它类问题常常因为开发时间不够或不重视等原因,大量的留给了测试阶段去提出;对于这类现象,负责的项目经理有时候是心有余而力不足;而不太负责的项目经理,...
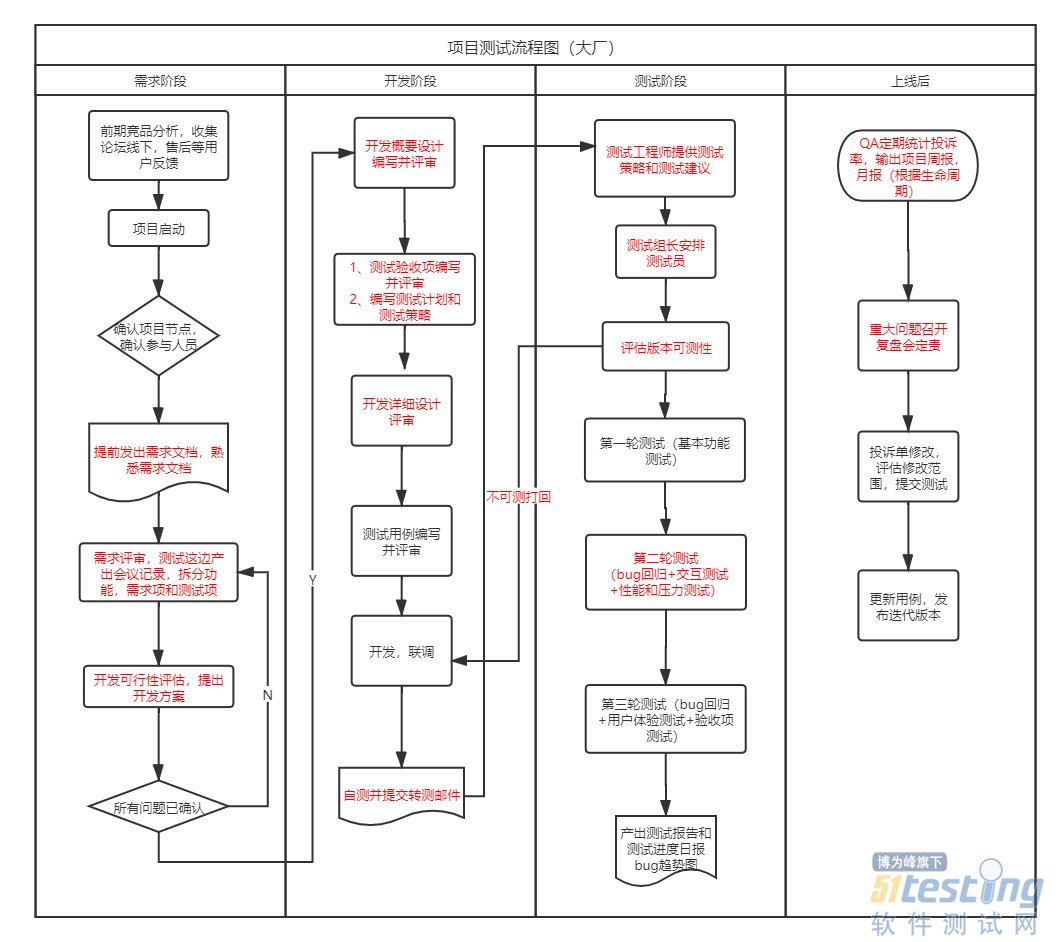
- 相信很多测试人员在进入职场时都面临过一个问题:大厂VS创业公司,到底该如何进行选择呢? 别着急,让我们先看看两者测试相关的区别。 大厂和创业公司,不管从测试流程、测试角色划分、测试用例设计还是使用的测试工具上,都是有比较明显的区别的。笔者在大厂和创业公司分别呆过三年,今天简单来总结下大厂和创业公司测试流程的区别。 大厂的测试流程 大厂的测试流程,每一步都有会议记录,需求变更严格走变更流程,会输出规格书、prd和原型图以及设计图。 创业公司的测试流程 创业公司的测试流程,一个会议会同时确认好几个事情,需求变更看大小,不麻烦就直接做上去了,基本只有原型图和设计图。 看完梳理的流程...
-


{kind=link}
{kind=link}
{kind=link}
- 关于我们 联系我们 版权声明 广告服务 站长统计
- 建议使用IE 11.0以上浏览器,800×600以上分辨率,法律顾问:上海兰迪律师事务所 项棋律师
- 版权所有 上海博为峰软件技术股份有限公司 Copyright©51testing.com 2003-2024, 沪ICP备05003035号
- 投诉及意见反馈:webmaster@51testing.com; 业务联系:service@51testing.com021-64471599-8017

- 51testing软件测试圈微信