 0
0 1
1


- 一文让你了解AI产品的测试
评价人工智能算法模型的几个重要指标
如何测试人工智能产品越来越受到广大测试工程师的关注,由于人工智能的测试预言(Test Oracle)不是像普通软件产品那么明确,到目前为止,基于大数据的第四代人工智能产品的测试,主要集中在“对大数据测试”“白盒测试”“基于样本分析算法的优劣”以及“对最终产品的验收测试”。“对大数据测试”主要针对数据阶段验证、对数据计算验证和对输出阶段验证;“白盒测试”主要考虑神经元覆盖(Neuron Coverage)、阈值覆盖率(Threshold Coverage)、符号变更率(Sign Change Coverage)、值变更覆盖率(Value Change Coverage)、符号-符号覆盖率(Sign-Sign Coverage)和层覆盖(Layer Coverage)这六个指标;“对最终产品的验收测试”可以采用对传统软件验收测试的方法,基于业务来进行测试,比如对于人脸识别系统,是否可以在各个人脸角度变化,光线等条件下正确识别人脸。本文重点讨论的是“基于样本分析算法的优劣”。
几个基本概念
大家都知道,人工智能通过训练样本来对系统通过深度学习的算法来进行训练,然后通过测试样本来对训练样本进行测试。“基于样本分析算法的优劣”中的样本仅对于测试样本而言。在这里样本的取样结果质量有几个关键的指标:正确率、精确度、召回率和F1分数。在介绍这些指标之前,我们先来看一下下面四个概念:
T(True):真样本;
F(False):假样本;
P(Positive):判断为真;
N(Negative):判断为假。
由此,我们又可以推断出如下四个概念:
TP True Positive:正确的判断为真(有病判断为有病,又称真阳性)
FN False Negative:错误的判断为假(有病判断为没病,又称假阴性,属于漏诊)
FP False Positive:错误的判断为真(没病判断为有病,又称假阳性,属于误诊)
TN True Negative:正确的判断为假(没病判断为没病,又称真阴性)
由此得到下面一个表:

精确度、召回率、准确性、Fn Score
这个表,成为混淆矩阵。下面把这张表再进行加工。

通过这张表,我们得到了所有的指标,在这些指标中,以下2个是特别有用的:
精确度(PPV)=TP/(TP+FP):真阳性在判断为真的比例数。是衡量所有判断为真的样例的质量;
召回率(TPR)= TP/(TP+FN):在所有的真样本中有多少被找出。
另外还有2项是此重要的,其中1项没有在上表中体现:
特异度(Specificity)= TN/( FP+FN):即真阴率,实际的假样本被正确地找出;
准确性= (TP + TN) / (TP + FP + TN + FN):所有的查出的真阳与真阴数所占所有样本的比率。
为了让大家更不好的理解这些指标,我们来看一个案例。某电子商务网站,根据Linda的历史购物框推选了15个商品,其中12个是推荐正确的,3个是推荐错误的,这个系统中有50个商品,其中符合推荐给Linda的应该为20个,其他30个为不符合的。下面让我们来看一下上面谈到的各个指标:
精确度(Precision)=12/15=80%;
召回率(Recall)=12/20=60%;
特异度(Specificity)=(30-(15-12))/30=27/30=90%;
准确性=(12+ Specificity)/50=(12+27)/50=78%。
那么是不是精确度或者召回率越高越好呢,那可不一定,要视具体的产品而定。比如新冠病毒的检测软件,我们宁可降低精确度,也要保证召回率,不放过一个病例。这种情况即所谓的“宁错杀一百,不放过一个”的策略。比如:样本中有50真样本,50假样本,判断得到95个,其中50个为真,45个为假。这样精度50/95=53%,召回率=50/50=100%,由此可见这种算法精确度并不高,只有53%,而召回率达到了100%。另外一种情况,是可以牺牲召回率,而保证精确度,比如精准扶贫,对于每一个扶贫农夫开销是很大的,所以不允许存在把钱花在假贫困户上。比如:同样样本中有50真样本,判断得到15个,其中15个为真,其中0个为假。这样精度15/15=100%,召回率=15/50=30%,由此可见这种算法精确度很高高,达到100%,而召回率不高,仅为30%。
一般而言精确度和召回率应该是负相关的,如果两个值都低说明算法有了问题了,这里提出了F0.5分数、F1分数、F2分数、F3分数等指标。用的最多的是F1分数。
Fn分数(F1 Score)=(1+n2)×精度×召回率×2 / (n2×精确度+召回率)
所以:
F0.5分数(F0.5 Score)=1.25×精度×召回率/ (0.25×精度+召回率);
F1分数(F1 Score)=2×精度×召回率/ (1×精度+召回率);
F2分数(F1 Score)=5×精度×召回率/ (4×精度+召回率)。
这样在上面的商品推荐案例中:
F0.5 Score=1.25×80%×60%/(0.25×80%+60%)=0.6/0.8=75%;
F1 Score=2×80%×60%/(1×80%+60%)=0.96/1.4=68%;
F2 Score=5×80%×60%/(4×80%+60%)=2.4/3.8=63%。
一般而言,如果Fn分数低于60%算法就有问题了,如果低于50%,就存在严重事故了。由此可见n值越大,要求越严格。
接下来介绍几个更高级的度量图
ROC 曲线(Receiver Operating Characteristic curve)
ROC曲线为接受者操作特性曲线是指在特定刺激条件下,以被试在不同判断标准下所得的假阳率为横坐标,真阳率为纵坐标,画得的各点的连线。

AUC(Area Under the Curve)为ROC下面的面积。
P-R(Recall-Precision)曲线
横坐标为,纵坐标为召回率,纵坐标为精确度。

如何选择ROC和P-R曲线
在很多实际问题中,正负样本数量往往很不均衡。比如,计算广告领域经常涉及转化率模型,正样本的数量往往是负样本数量的1/1000,甚至1/10000。若选择不同的测试集,P-R曲线的变化就会非常大,而ROC曲线则能够更加稳定地反映模型本身的好坏。所以,ROC曲线的适用场景更多,被广泛用于排序、推荐、广告等领域。
但需要注意的是,选择P-R曲线还是ROC曲线是因实际问题而异的,如果研究者希望更多地看到模型在特定数据集上的表现,P-R曲线则能够更直观地反映其性能。
PR曲线比ROC曲线更加关注正样本,而ROC则兼顾了两者。
AUC越大,反映出正样本的预测结果更加靠前(推荐的样本更能符合用户的喜好)。
当正负样本比例失调时,比如正样本1个,负样本100个,则ROC曲线变化不大,此时用PR曲线更加能反映出分类器性能的好坏。这个时候指的是两个分类器,因为只有一个正样本,所以在画auc的时候变化可能不太大;但是在画PR曲线的时候,因为要召回这一个正样本,看哪个分类器同时召回了更少的负样本,差的分类器就会召回更多的负样本,这样precision必然大幅下降,这样分类器性能对比就出来了。
Kappa系数
K=(P0-Pe)/(1-Pe)
P0是每一类正确分类的样本数量之和除以总样本数,也就是总体分类精度
假设每一类的真实样本个数分别为a1,a2,...,aC,而预测出来的每一类的样本个数分别为b1,b2,...,bC,总样本个数为n,则有Pe=( a1×b1+a2×b2+…+aC×bC)/(n×n)
让我们来看一个例子,比如有如下混淆矩阵:

所有案例数:239+21+16+16+73+4+6+9+28=664;
判断为A的案例数:239+16+6=261;
判断为B的案例数:21+73+9=103;
判断为C的案例数:16+4+280=300;
A的案例数:239+21+16=276;
B的案例数:16+73+4=93;
C的案例数:6+9+280=295。
这样:
P0=(239+73+280)/664=0.8916;
Pe=(261×276+103×93+300×295)/(64×64)=0.3883;
K=(0.8916-0.3883)/(1-0.3883)=0.8228。
通过K的值,可以判定模型的好坏:
0.0~0.20:极低的一致性(slight);
0.21~0.40:一般的一致性(fair);
0.41~0.60:中等的一致性(moderate);
0.61~0.80:高度的一致性(substantial);
0.81~1:几乎完全一致(almost perfect)。
程序的实现
前面讲课那么多指标,其实在Python里面可以利用sklearn这个插件快速的画出这些指标和算法。利用这个工具之前当然需要下载安装这个插件。
>pip3 install sklearn
下面来讲解一下这个代码。
# coding=UTF-8
from sklearn import metrics
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from sklearn.metrics import f1_score
import matplotlib.pylab as plt
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
from sklearn.metrics import precision_recall_curve
#真实值
GTlist = [1,1,0,1,1,0,1,0,0,1]
#模型预测值
Problist = [1,0,1,1,1,1,1,1,0,1]
y_true = np.array(GTlist)
y_pred = np.array(Problist)
#混淆矩阵
confusion_matrix = confusion_matrix(y_true, y_pred)
print("混淆矩阵:")
print(confusion_matrix)
#准确性
accuracy = '{:.1%}'.format(accuracy_score(y_true, y_pred))
print("准确性:",end='')
print(accuracy)
#精确性
precision = '{:.1%}'.format(precision_score(y_true, y_pred))
print("精确性:",end='')
print(precision)
#召回率
recall = '{:.1%}'.format(recall_score(y_true, y_pred))
print("召回率:",end='')
print(recall)
#F1值
f1score = '{:.1%}'.format(f1_score(y_true, y_pred))
print("F1值:",end='')
print(f1score)
#初始化画图数据
#真实值
GTlist = [1.0, 1.0, 0.0, 1.0, 0.0, 1.0, 0.0, 1.0, 0.0, 1.0,0.0, 1.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0]
#模型预测值
Problist = [0.99, 0.98, 0.97, 0.93, 0.85, 0.80, 0.79, 0.75, 0.70, 0.65,0.64, 0.63, 0.55, 0.54, 0.51, 0.49, 0.30, 0.2, 0.1, 0.09]
fpr, tpr, thresholds = metrics.roc_curve(GTlist, Problist, pos_label=1)
roc_auc = metrics.auc(fpr, tpr) #auc为Roc曲线下的面积
print("AUC值:",end='')
print('{:.1%}'.format(roc_auc))
#ROC曲线
plt.plot(fpr, tpr, 'b',label='AUC = %0.2f'% roc_auc)
plt.legend(loc='lower right')
# plt.plot([0, 1], [0, 1], 'r--')
plt.xlim([-0.1, 1.1])
plt.ylim([-0.1, 1.1])
plt.xlabel('False Positive Rate') #横坐标是fpr
plt.ylabel('True Positive Rate') #纵坐标是tpr
plt.title('Receiver operating characteristic example')
plt.show()
#P-R曲线
plt.figure("P-R Curve")
plt.title('Precision/Recall Curve')
plt.xlabel('Recall')
plt.ylabel('Precision')
#y_true为样本实际的类别,y_scores为样本为正例的概率
y_true = np.array(GTlist)
y_scores = np.array(Problist)
precision, recall, thresholds = precision_recall_curve(y_true, y_scores)
plt.plot(recall,precision)
plt.show()真实值GTlist = [1,1,0,1,1,0,1,0,0,1]
模型预测值Problist = [1,0,1,1,1,1,1,1,0,1]
现在有10位病人来看病,其中3号、6号、8号和9号病人是没有疾病的(绿色),其他剩余6位有疾病(红色)。

1号、4号、5号、7号和10号病人被查出来(真阳性,红色);2号病人没有被查出来(漏诊,橙色);3号、6号和8号被误诊(误诊,蓝色),另外9号(真隐性,绿色),通过运行这段代码,得到如下结果:
混淆矩阵:
[[1 3]
[1 5]]
准确性:60.0%
精确性:62.5%
召回率:83.3%
F1值:71.4%
我们来验证一下,真阳性:5、真阴性:1、假阳性:3、假阴性:1,所以混淆矩阵为:

由此,可以看出算出来的矩阵与正式的矩阵的对应关系。假在前,真在后,一行代表实际中的实际中的一行。
准确性:(1+5)/10=60%
精确性:5/8=62.5%
召回率:5/6=83.3%
F1 Score=62.5%×83.3%×2/(62.5%+83.3%)=1.04125/1.458=71%
可见这些值都是正确的。接下来再看下面的数据。
#真实值
GTlist = [1.0, 1.0, 0.0, 1.0, 0.0, 1.0, 0.0, 1.0, 0.0, 1.0,0.0, 1.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0]
#模型预测值
Problist = [0.99, 0.98, 0.97, 0.93, 0.85, 0.80, 0.79, 0.75, 0.70, 0.65,0.64, 0.63, 0.55, 0.54, 0.51, 0.49, 0.30, 0.2, 0.1, 0.09]
GTlist表示真实样本,1.0代表真样本,0.0代表假样本;
Problist表示预测样本,每个值表示预测到对应真实样本为真的概率。比如第一个0.99表示预测第一个正样本的概率为99%,第三个0.97表示预测第三个假样本的概率为97%。通过运行我们得到如下曲线图。

我们考察A(0,0)、B(1,1)、C(0,1)、D(1,0)四个点:
A(0,0):表示真阳率与假阳率均为0,表示什么都没有测试到;
B(1,1):表示真阳率与假阳率均为100%;
C(0,1):真阳率为100%,假阳率均为0,测试到的全是真的;
D(1,0):真阳率为0,假阳率均为100%,测试到的全是假的。
由此可见C点的情况最高,所以曲线越靠近左上角说明算法最好。
另外,上面代码也会给出了化P-R图的方法,对于ROC曲线,采用同一个测试数据,画出来的图如下显示。

版权声明:本文出自51Testing会员投稿,51Testing软件测试网及相关内容提供者拥有内容的全部版权,未经明确的书面许可,任何人或单位不得对本网站内容复制、转载或进行镜像,否则将追究法律责任。
- 0.00 查看剩余0%
- 【留下美好印记】赞赏支持
热门文章
最新讲堂
- 推荐阅读
- 换一换
- 软件测试黑盒测试与白盒测试简单分类——软件测试圈12-15软件测试其实就是对程序进行一些操作,来发现程序所存在的缺陷,衡量软件的质量,并对其是否能满足设计要求进行评估的过程。软件测试方法分类基于直觉和经验的方法Ad-hoc测试方法:强调测试人员根据自己的经验,不受测试用例的约束,放开思想,灵活地进行测试。ALAC测试方法:Act like a customer,像客户那样做,对常用的功能进行测试;错误推测法:有经验的测试人员根据自己的工作经验和直觉测出程序可能存在的错误,从而有针对性地进行测试。基于输入域的测试方法等价类划分法边界值分析法基于组合及其优化的方法判定表法因果图法pair-wise方法正交试验法基于逻辑覆盖的方法语句覆盖判定覆盖条件覆盖判...

- 教你使用js代码覆盖率测试工具08-21摘 要 喂,你那个刚测好的页面怎么又出现了bug?这里怎么交互几次页面重绘就出了问题?你到底对前端测试用例的覆盖率有几分把握,真的没有测试遗漏嘛?对于这些疑问,正在看文章的你如果能够轻松应对,那么请关掉屏幕,本文与你关系不大,出去运动一下吧。但如果你也有类似的困惑,并且正在寻找衡量js代码测试完整度的方法,那么请继续阅读,文中介绍的js覆盖率工具会让你在完善前端测试用例的征途上,走的轻松一些。 正 文 众所周知,前端测试需求多、改动大,业务逻辑复杂又紧密,往往首轮设计的测试用例并不能完全覆盖所有的功能点和diff代码。这时,就需要代码覆盖率工具帮助我们发现测试未能覆盖到的代码分支和逻...
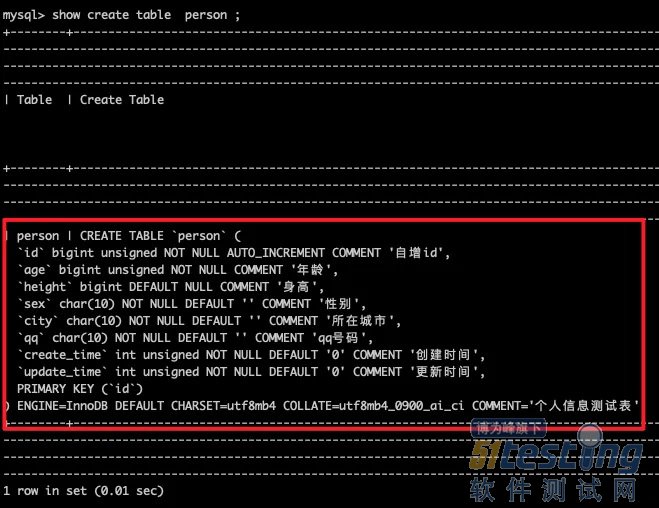
- 详解接口测试构造测试数据——软件测试圈06-04构造数据方法 构造少量数据 对于上面例子(2)是我们经常碰到的情况。如果只需要构造一个人的信息,即可满足测试,我们可以使用SQL 语句在数据库里面 insert 插入一条数据,或者 update 一条历史数据使其满足查询条件即可 下面演示一下,先在数据库里面创建person数据表,创建SQL语句如下: create table `person` ( `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMME...
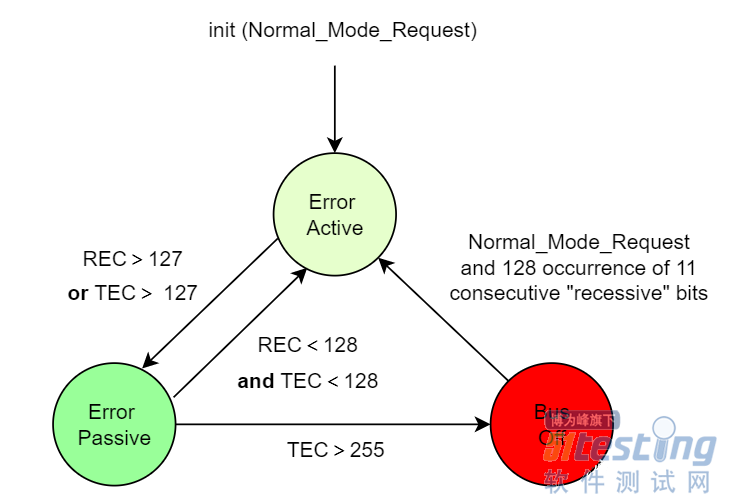
- CAN通信:Busoff问题知多少——软件测试圈04-091、测试中,为什么是32个错误帧出现一次Busoff? Busoff的产生是因为TEC(Transmit Error Counter)>255导致,再次提醒:与REC(Receive Error Counter)无关。也就是说,如果节点状态切换到Busoff,是因为节点自身外发报文错误导致TEC>255。 回顾一下节点状态机,节点状态机如下所示: 在切入主题之前,对Error Passive状态做一个展开,节点由Error Active进入Error Passive,是因为REC>127 or TEC>127。所以,节点进入Error Passive状态的可以分两个层面看...
- 项目系统介绍 地质系统——主要作用进行地质数据建模、数据收集、数据计算及数据传递。 执行系统——主要根据地质系统传过来的数据,如平面地质图、巷道现状图等进行车辆调度并统计相关生产数据。 Mes系统——主要用于从相关系统获得的数据进行日报展示、大屏重点数据展示及相关数据业务数据展示。 各系统间逻辑关系:数据获取-计算-执行-展示。 项目背景:没有详细的需求文档,测试人力少 (2人)。 用例编写 用例的重要性 有时候因为时间紧张,没有编写测试用例,虽然可能会在一定程度上节省时间,但是这也可能导致关键的测试点被遗漏,从而影响测试的全面性和准确性。编写测试用例能够确保系统的各个方面...

-




{kind=link}
{kind=link}
是我们经常碰到的情况。如果只需要构造一个人的信息,即可满足测试,我们可以使用SQL 语句在数据库里面 insert 插入一条数据,或者 update 一条历史数据使其满足查询条件即可 下面演示一下,先在数据库里面创建person数据表,创建SQL语句如下: create table `person` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMME...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=147013&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=147013&pic=http://quan.51testing.com/ueditor/php/upload/image/20240604/1717489939878383.jpg){kind=link}
>255导致,再次提醒:与REC(Receive Error Counter)无关。也就是说,如果节点状态切换到Busoff,是因为节点自身外发报文错误导致TEC>255。 回顾一下节点状态机,节点状态机如下所示: 在切入主题之前,对Error Passive状态做一个展开,节点由Error Active进入Error Passive,是因为REC>127 or TEC>127。所以,节点进入Error Passive状态的可以分两个层面看...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=146903&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=146903&pic=http://quan.51testing.com/ueditor/php/upload/image/20240409/1712649463552419.png){kind=link}
。 用例编写 用例的重要性 有时候因为时间紧张,没有编写测试用例,虽然可能会在一定程度上节省时间,但是这也可能导致关键的测试点被遗漏,从而影响测试的全面性和准确性。编写测试用例能够确保系统的各个方面...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=146530&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=146530&pic=http://quan.51testing.com/ueditor/php/upload/image/20231010/1696905739862477.png){kind=link}
- 关于我们 联系我们 版权声明 广告服务 站长统计
- 建议使用IE 11.0以上浏览器,800×600以上分辨率,法律顾问:上海兰迪律师事务所 项棋律师
- 版权所有 上海博为峰软件技术股份有限公司 Copyright©51testing.com 2003-2024, 沪ICP备05003035号
- 投诉及意见反馈:webmaster@51testing.com; 业务联系:service@51testing.com021-64471599-8017

- 51testing软件测试圈微信