 0
0 0
0


- CAN通信:Busoff问题知多少——软件测试圈
1、测试中,为什么是32个错误帧出现一次Busoff?
Busoff的产生是因为TEC(Transmit Error Counter)>255导致,再次提醒:与REC(Receive Error Counter)无关。也就是说,如果节点状态切换到Busoff,是因为节点自身外发报文错误导致TEC>255。
回顾一下节点状态机,节点状态机如下所示:

在切入主题之前,对Error Passive状态做一个展开,节点由Error Active进入Error Passive,是因为REC>127 or TEC>127。所以,节点进入Error Passive状态的可以分两个层面看:
第一、总线上其他节点(eg:Node A)引发的错误,导致接收节点(eg:Node B)的REC>127。既然是外因,即:Node A错误导致Node B进入Error Passive状态,对Node B的最大"伤害"到此状态即可,Node B的通信状态没有什么问题,无需断开总线连接;
第二、发送节点引发错误,当TEC>127时,进入Error Passive状态,如果发送节点依然识别到自身发送报文有问题(有错误帧),为了降低对总线上其他节点的影响,发送节点要为自己的错误行为负责,当TEC>255时,节点需要暂时退出总线通信,之后尝试恢复通信。
对于节点的Error Passive和Busoff状态,驱动层可以提供对应的接口给上层,以此改善功能算法。以英飞凌tc3xx为例,如下所示:

通过BO位域和EP位域可以更准确的获悉节点状态,如下所示:

如果需要更进一步的知道Error Passive是TEC还是REC导致的,可以进一步读取错误计数寄存器(ECR)的RP位域,如下所示:

提示:REC使用7个Bit表示,最大可表示128,TEC用8个Bit表示,最大可表示256。
回到这个小节的问题:“测试中,为什么错误帧达到32帧,就会Busoff呢?可以大于32帧吗?”
如果要搞清楚发送多少错误帧会导致TEC>255,进而让节点进入Bus off状态,我们需要先清楚TEC的累加规则:
发送节点在发送时,产生错误标志,TEC + 8。注意,有两种工况除外:
第一、仲裁阶段,节点发送隐性位("1"),收到显性位("0")。当其他节点CAN ID小,优先级高时,低优先级(CAN ID大)的节点仲裁失败,发送的隐性位被显性位覆盖导致;
第二、节点处于Error Passive模式时,Ack Slot发送隐性位,收到隐性位(没有节点应带发送节点),说明当前总线只有一个节点在总线中,此时TEC不需要再累加;
发送节点在发送主动错误标志或者过载标志时,检测出位错误(Bit Error), TEC + 8;
节点从主动错误标志、过载标志的最开始检测出连续14个显性位。之后,每检测出连续8个显性位。TEC + 8;
被动错误标志后检测出连续8个显性位。TEC + 8;
发送节点正常发送完一帧数据,且被其他接收节点应答(Ack)。TEC - 1,如果TEC = 0,则保持0;
如果节点已经Busoff,当检测到128个连续11 bit隐性位时。TEC = 0。
通过如上规则可以看出,对于发送节点自身发送报文导致的错误,TEC均会累加8,也就是说,如果想最快地使得某个节点进入Bus off状态,就得让发送节点自己识别到自身产生的错误,而且,最少要产生32次,32*8 = 256 >255,节点进入Bus off状态。
有的时候看到总线错误不止32帧,节点才进入Busoff,又是因为什么呢?这里我们分析一种工况:
测试中,如果通过Capl脚本只是干扰节点(Node A)固定的CAN ID(eg:0x10),可能需要>32个错误帧,才能让Node A进入Bus off。一个项目中,一个节点的外发报文可以有多个。
假设:Node A有5个外发的周期性应用报文,CAN ID:0x01~0x20,周期都是10ms。测试中,只干扰CAN ID = 0x10的报文。
如上TEC计数规则中,节点每成功发送一帧报文,TEC会减1,由于Node A 的5个CAN报文周期相同,干扰0x10使得TEC + 8,但是,如果其余4个报文成功被发送,则每发送一帧,TEC - 1。这样就使得TEC不能很快的>255,进而错误帧的次数会超过32帧。所以,如果想快速的制造Bus off,可以对多有外发报文的某个Bit干扰,这样,可以连续的干扰出32个错误帧。
只干扰特定CAN ID报文,总线报文状态示意如下所示:

提示:一个错误帧中,可能有多种错误类型。
2、Bus off的DTC问题
当Bus off发生到一定程度时,会影响到总线的正常通信,需要将此故障信息记录下来,以便于后续问题排查。对于Bus off DTC的设计策略,每家OEM要求有所不同。本文,分享一种需求,供大家参考:
Busoff检测频率10ms。DTC一般会对应一个或者多个事件(Event),为了识别事件的状态,会约束一个检测频率,检测频率的大小,意味着事件发生故障时,能否被快速检测到,进而决定着事件对应的DTC能否被快速触发;
Busoff快恢复32次,快恢复周期10ms。当节点通信出现故障时,如果能快速恢复通信,节点功能也能及时恢复,所以,设计10ms的快恢复也就能理解。尝试32次,也是想尽可能地挽救故障节点的通信功能;
Busoff慢恢复NA(不做明确约束),慢恢复周期60s。当快恢复32次都不能有效挽救节点通信时,说明节点大概率出现了不可逆的故障。所以,设计一个较慢的慢恢复期,就是想再碰碰运气,万一节点通信又恢复了呢?如果节点不能恢复通信,车辆又不能立马停下,只能任其不断地尝试慢恢复,因此,不做慢恢复的约束。此时,同网段内的其他节点会监控对应的通信报文是否丢失,故障节点由于发生Busoff,非Busoff DTC的监控功能禁止;
Busoff发生32次,进入慢恢复期时,Bus off DTC Confirmation(Bit 3 = 1)。既然做了最大努力的尝试,节点不能恢复通信,为了便于后续的车辆检修,需要记录Bus off DTC;
Step Up = 4,32次Busoff后,4*32 >127,Step Down = 128。
相对于其他监控事件,Bus off 事件优先级(Event priority)一般较低,注意:1表示highest priorit,数字越大,事件的优先级越低。
这里需要讨论一个“连续”问题,Busoff发生32次,且Busoff由快恢复(Level1)进入慢恢复(Level2)阶段时,Busoff DTC需要上报。这里的32次如何计算呢?这里抛一个问题:”如上需求中,10ms可以检测一次节点Busoff状态,假设前100ms检测到了10次节点Busoff状态,中间1s节点恢复了通信,之后又快速的发生了32次Busoff,需要上报Busoff DTC吗?“,如下所示:

如上的问题就涉及到了一个问题:”Busoff次数如何累加?“,对于这个问题的答案,需要结合项目需求,和甲方明确好。每家OEM的约束不同,这里讨论一种约束工况:以10ms检测频率为基准,如果20ms的检测周期内没有检测到Busoff,则Busoff CNT不再累加,重置Busoff CNT(Busoff CNT = 0),因为此时的Busoff不是"连续"的。
作者:佚名
- -1.00 查看剩余0%
- 【留下美好印记】赞赏支持
热门文章
最新讲堂
- 推荐阅读
- 换一换
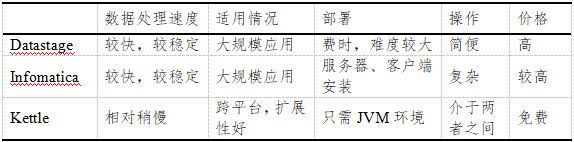
- 开源数据抽取工具kettle的研究与实践11-28摘要:测试数据在项目开发、测试过程中占据着重要的作用,随着我行信息系统建设速度的加快,软件更新速度的不断提升,对数据交付时间和数据格式的要求也越来越高。对于数据库大表来说,无论是脱敏还是导出的速度,往往不能满足实际需要,Kettle作为业内最著名的开源ETL(数据抽取)工具,可直接对数据库表进行操作并以多种格式进行导出,格式规范,效率较高,能很好的满足使用过程中的需要。本文对kettle在实际中具体的使用与实践进行重点介绍。1、常用ETL工具现状简介ETL是Extract-Transform-Load的简写,用来描述将数据从源端经过抽取(extract)、转换(transform)、加载(lo...
- 今天我们要探讨的话题源于一篇在社交媒体引起广泛争议的 “阿里P8员工征婚贴”。该贴通过一张截图流传开来,主角是一位背景不凡的阿里P8级员工,具体信息如下: 这位阿里P8级别的高级工程师,他的成长轨迹堪称励志典范,出生于安徽农村的他,凭借顽强的毅力和卓越的智慧,一步步跃过了生活的龙门,先是凭借优异的成绩考入了全国知名的211高校就读本科,紧接着又在学业上更进一步,成功取得了985名校的硕士学位。如今,他已经在首都北京安家落户,拥有了一份羡煞旁人的都市生活,居住在一套位于繁华地段北苑的宽敞三居室中,尽管这套120平米的房产仍有200万元的贷款余额,但这丝毫没有影响到他对于生活的追求与期待。他...
-
- 如何用Apifox发送接口请求?05-24大家好,我们已经安装好了Apifox。而且也建立好了团队和项目。 从建立项目的过程中,我们可以看到Apifox 其实是一个很好的API 管理工具。通过文件夹的层级,可以管理我们项目的所有API。 今天我们的学习任务呢,就是用Apifox 发送一个接口请求。今天我们就来学习下大部分都要用的API工具的接口测试功能,也是对测试人员来说最实用的功能。1.首先用其他工具先抓包。不管是网页里 F12里的网络里的请求或者是抓包工具里的请求。我们复制下CUrl。(如果你本身对接口特别熟悉,可以直接添加接口)。2.打开我们昨天已经创建好项目,点击+。3.选择「 导入抓包数据(cURL)」 ,就可以导入单个接口...
- 软件测试有多种多样的方法和技术,可以从不同角度对它们进行分类。其中,根据软件生命周期,针对不同的测试对象与目标,可将测试过程分为4个阶段:单元测试、集成测试、系统测试和验收测试。本文着重介绍了如何借用pytest与httprunner进行接口自动化测试。一、 什么是接口测试根据wiki中的定义,接口是一个共享的边界,计算机系统的多个独立组件通过它交换信息。这些信息的交换可以基于软件、硬件、外部设备、人和它们之间的组合。根据上述定义,可以面向软件、硬件、交互设备等展开接口测试。软件的接口测试是面向独立组件之间接口的一种测试,主要用于检测内外部系统及内部各子系统之间的交互点。测试的重点在于检查逻辑...

-
- 今年刚接触了(功能)测试工程师的面试工作,有遇到对信贷业务流程较熟悉的、工作内容纯测试App功能的、什么都接触过但是不够深入的,发现简历上写的东西和实际真的有点差距,面试也是一个艺术活。 为了更好地考察面试者的能力,让面试工作更加有条理,总结了下我考虑的几个方面:沟通能力、测试基础和技能、业务能力、测试思维、学习能力。 基本的逻辑能力、表达能力 这个不用特意考察,观察面试者在表达的时候条理是否清晰,逻辑性强不强,是简洁明了还是一大堆无关紧要的让人抓不住重点。 对项目流程的了解 一个完整的项目流程是什么,测试工作从哪里开始介入到哪里结束,每个步骤中测试工程师的职责是什么? 如果该...
-


工具,可直接对数据库表进行操作并以多种格式进行导出,格式规范,效率较高,能很好的满足使用过程中的需要。本文对kettle在实际中具体的使用与实践进行重点介绍。1、常用ETL工具现状简介ETL是Extract-Transform-Load的简写,用来描述将数据从源端经过抽取(extract)、转换(transform)、加载(lo...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=343&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=343&pic=http://quan.51testing.com/ueditor/php/upload/image/20191127/1574824161705271.png){kind=link}
。2.打开我们昨天已经创建好项目,点击+。3.选择「 导入抓包数据(cURL)」 ,就可以导入单个接口...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=144733&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=144733&pic=http://quan.51testing.com/ueditor/php/upload/image/20220524/1653385900765568.png){kind=link}
{kind=link}
- 关于我们 联系我们 版权声明 广告服务 站长统计
- 建议使用IE 11.0以上浏览器,800×600以上分辨率,法律顾问:上海兰迪律师事务所 项棋律师
- 版权所有 上海博为峰软件技术股份有限公司 Copyright©51testing.com 2003-2024, 沪ICP备05003035号
- 投诉及意见反馈:webmaster@51testing.com; 业务联系:service@51testing.com021-64471599-8017

- 51testing软件测试圈微信