 0
0 0
0
分享


- 如何使用Python爬取Google搜索结果中的URL——软件测试圈
当我们需要在互联网上搜索一些信息时,往往会选择使用搜索引擎来获取更加准确和丰富的信息。Google搜索引擎是全球最大的搜索引擎之一,拥有着极其庞大的数据库和算法,可以根据关键词搜索出大量的相关信息。但是,当我们需要采集搜索结果中的URL时,手动复制粘贴会非常繁琐。因此,本文将介绍如何使用Python编写爬虫程序,自动爬取Google搜索结果中的URL。注意:谷歌爬取是要代理。
前置条件
在开始编写爬虫程序之前,需要确保已经安装了Python编程环境和一些必要的Python库,比如requests、re等。可以使用pip命令来安装这些库。
爬虫程序的实现
首先,我们需要设置请求头信息和搜索关键词。在实际爬取时,应该将搜索关键词替换为需要搜索的具体内容。
import requests import re
设置headers
headers = {
'User-Agent': '********'}设置搜索关键词 这里建议采用谷歌语法查询
keyword = "***"
接着,我们使用requests库发送HTTP GET请求,获取Google搜索结果的HTML页面。由于Google搜索的结果通常会分为多个页面,因此我们需要对每一页的结果进行爬取。这里我们以每页显示10个结果为例,共爬取10页的搜索结果。在爬取过程中,我们使用正则表达式匹配出HTML页面中所有的URL链接。
爬取搜索引擎的结果
urls = []
for page in range(0, 101, 10):
url = "www.google.com/search?q={}…, page)
r = requests.get(url, headers=headers)
# 使用正则表达式匹配所有url
urls += re.findall('href="(https?://.*?)"', r.text)最后,我们将爬取到的所有URL链接进行去重,并将结果保存到本地文件中。这样就完成了整个爬虫程序的实现。
去重
urls = list(set(urls))
将url保存到文件
with open('urls.txt', 'w') as f:
for url in urls:
f.write(url + '\n')代码汇总
import requests
import re
# 设置headers
headers = {
'User-Agent': '****'}
# 设置搜索关键词
keyword = "***"
# 爬取搜索引擎的结果
urls = []
for page in range(0, 101, 10):
url = "https://www.google.com/search?q={}&start={}".format(keyword, page)
r = requests.get(url, headers=headers)
# 使用正则表达式匹配所有url
urls += re.findall('href="(https?://.*?)"', r.text)
# 去重
urls = list(set(urls))
# 将url保存到文件
with open('urls.txt', 'w') as f:
for url in urls:
f.write(url + '\n')总结
本文介绍了如何使用Python编写爬虫程序,自动爬取Google搜索结果中的URL。通过这种方法,我们可以快速地采集大量的URL链接,为后续的数据分析和挖掘提供更加丰富的数据来源。在实际爬取时,还需要注意一些反爬虫措施。
作者:mss
- -1.00 查看剩余0%
- 【留下美好印记】赞赏支持
登录 后发表评论

quinn
+ 关注
热门文章
最新讲堂
温馨提示
- 推荐阅读
- 换一换
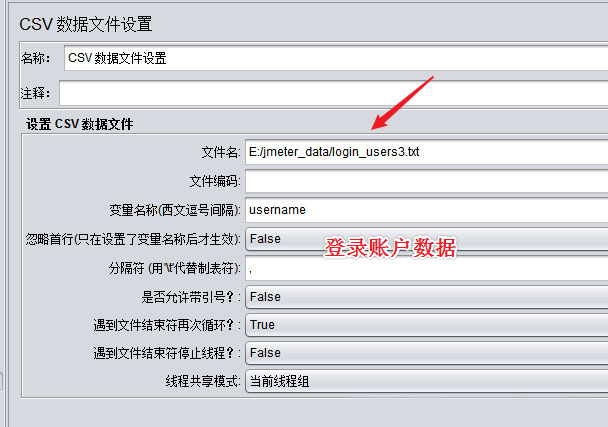
- 1.数据准备已事先准备好5个不同用户账号2.设置线程并发数ramp-up period 指 JMeter 用于执行全部请求的时间 如果设置了 100 个线程,并且 ramp-up period 是 2 秒,那么 JMeter 将在 2 秒钟 之内启动 100 个线程.如果循环次数是 2,那么 jmeter 将在 2 秒之内发送 200 个 请求(100*2) 如果循环次数设置为永远,那么 jmeter 将以最大可能去发送请求,以此测试出 最大并发数此处采用5个并发数作为测试演示设置为5个用户并发访问注意,若设置5个用户并发访问时,需在线程组中设定,用于模拟多用户同时测试的线程数为5个。如果线程...
-
- 测试如何避免成为背锅专业户?07-11一、如何尽最大的努力避免成为背锅侠?本文主要讲述自己从一个测试菜鸟,逐步成长到现在过程中累积的一些经验。在日常测试工作中,经常听到开发说:这个bug是产品设计缺陷?这个细节产品设计文档没有?这个bug是前端的?这个bug是app端的?等等诸如此类的推脱,不愿意承认这个bug是他代码漏洞造成的。最后苦逼的测试就陷入两难的地步,提交一个bug吧,开发小哥哥不乐意了,不提吧万一出了问题就要我们测试小虾米来背锅了。凡是遇到线上故障,都是测试负主要责任,开发负次要责任。可怜的测试人员在背锅到道路上越走越远… 以下是个人总结的如何避免成为背锅侠?如何完美的甩锅...

- 春节刚过,ChatGPT便快速引爆了资本圈与AI圈,很多从业者把它“吹爆了”。 OneFlow深度学习框架创始人袁进辉告诉新浪财经,ChatGPT的技术进步,可比作首次“登月”,这样的进步令行业感到震惊。但出门问问创始人兼CEO李志飞虽然也肯定了ChatGPT的变革,但表示“它所知道的答案是缺乏逻辑起点和推理规则,只是一个空中楼阁。“ 为此,新浪财经开通了“chat.openai.com”官网账号上,对ChatGPT进行了实测,看看它究竟有没有那么神奇?能引领AI风口,还是昙花一现? 实测ChatGPT,究竟有没有那么神奇? “ChatGPT的体验已经是目前最好的了,甚至可以当作谷...
-
- Mybatis常见面试题总结——软件测试圈03-161、什么是Mybatis?Mybatis是一个半ORM(对象关系映射)框架,它内部封装了JDBC,加载驱动、创建连接、创建statement等繁杂的过程,开发者开发时只需要关注如何编写SQL语句,可以严格控制sql执行性能,灵活度高。作为一个半ORM框架,MyBatis 可以使用?XML 或注解来配置和映射原生信息,将?POJO映射成数据库中的记录,避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集。称Mybatis是半自动ORM映射工具,是因为在查询关联对象或关联集合对象时,需要手动编写sql来完成。 不像Hibernate这种全自动ORM映射工具,Hibernate查询关联对象或...
- #先看一下简单的API # coding = utf-8 from selenium import webdriver import time browser = webdriver.Firefox() time.sleep(3) browser.get("http://www.baidu.com") time.sleep(3) browser.find_element_by_id("kw").send_keys("selenium") time...
-



》&1.数据准备已事先准备好5个不同用户账号2.设置线程并发数ramp-up period 指 JMeter 用于执行全部请求的时间 如果设置了 100 个线程,并且 ramp-up period 是 2 秒,那么 JMeter 将在 2 秒钟 之内启动 100 个线程.如果循环次数是 2,那么 jmeter 将在 2 秒之内发送 200 个 请求(100*2) 如果循环次数设置为永远,那么 jmeter 将以最大可能去发送请求,以此测试出 最大并发数此处采用5个并发数作为测试演示设置为5个用户并发访问注意,若设置5个用户并发访问时,需在线程组中设定,用于模拟多用户同时测试的线程数为5个。如果线程...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=72124&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=72124&pic=http://quan.51testing.com/ueditor/php/upload/image/20210224/1614148209407804.jpg){kind=link}
{kind=link}
{kind=link}
温馨提示
打开微信 扫一扫
温馨提示
设置支付密码
- 关于我们 联系我们 版权声明 广告服务 站长统计
- 建议使用IE 11.0以上浏览器,800×600以上分辨率,法律顾问:上海兰迪律师事务所 项棋律师
- 版权所有 上海博为峰软件技术股份有限公司 Copyright©51testing.com 2003-2024, 沪ICP备05003035号
- 投诉及意见反馈:webmaster@51testing.com; 业务联系:service@51testing.com021-64471599-8017

- 51testing软件测试圈微信