 0
0 0
0
分享


- 自动化测试webdriver常用的API——软件测试圈
#先看一下简单的API
# coding = utf-8
from selenium import webdriver
import time
browser = webdriver.Firefox()
time.sleep(3)
browser.get("http://www.baidu.com")
time.sleep(3)
browser.find_element_by_id("kw").send_keys("selenium")
time.sleep(3)
browser.find_element_by_id("su").click()
browser.quit()脚本解析 coding = utf-8 可加可不加,开发人员喜欢加一下,防止乱码。 from selenium importwebdriver 要想使用selenium 的webdriver 里的函数,首先把包导进来 browser =webdriver.Firefox() 我们需要操控哪个浏览器呢?Chrome ,当然也可以换成Ie 或Firefox。 browser.get() 可以随便取,但后面要用它操纵 各种函数执行。 browser.find_element_by_id(“kw”).send_keys(“selenium”) 一个控件有若干属性id、name、(也可以用其它方式定位),百度输入框的id 叫kw ,我要在输入框里输入 selenium 。 browser.find_element_by_id(“su”).click() 搜索的按钮的id 叫su ,我需要点一下按钮(click() )。 browser.quit() 退出并关闭窗口的每一个相关的驱动程序。
一、元素的定位
webdriver 提供了一系列的对象定位方法,常用的有以下几种
1、id和name定位
(举例:通过前端工具,找到百度输入框的相关属性)
<input id="kw" class="s_ipt" type="text" maxlength="100" name="wd" autocomplete="off">
id=”kw” 通过find_element_by_id(“kw”) 函数就是捕获到百度输入框 name=”wd”通过find_element_by_name(“wd”)函数同样也可以捕获百度输入框
2、class name 和 tag name的定位
从上面的百度输入框的属性信息中,我们看到,不单单只有id 和name 两个属性, 比如class 和tag name(标签 名)
input 就是一个标签的名字 可以通过find_element_by_tag_name(“input”) 函数来定位。 class=“s_ipt”, 通过find_element_by_class_name(“s_ipt”)函数捕获百度输入框
3、link text
有时候不是一个输入框也不是一个按钮,而是一个文字链接,我们可以通过link定位
#coding=utf-8
from selenium import webdriver
browser = webdriver.Chrome()
browser.get("http://www.baidu.com")
browser.find_element_by_link_text("hao123").click()
browser.quit()4、partial link text
#coding=utf-8
from selenium import webdriver
browser = webdriver.Chrome()
browser.get("http://www.baidu.com")
browser.find_element_by_partial_link_text("hao").click()
browser.quit()5、xpath
XPath 扩展了上面id 和name 定位方式,提供了很多种可能性。
6、css selector
CSS 的比较灵活可以选择控件的任意属性,上面的例子中: find_element_by_css_selector("#kw")
通过find_element_by_css_selector( )函数,选择取百度输入框的id 属性来定义webdriver 中比较常用的操作对象的方法有下面几个:
click 点击对象 send_keys 在对象上模拟按键输入 clear 清除对象的内容,如果可以的话 submit清除对象的内容,如果可以的话 text 用于获取元素的文本信息
智能等待:通过添加implicitly_wait() 方法就可以方便的实现智能等待;implicitly_wait(30)的用法应该比time.sleep() 更智能, 后者只能选择一个固定的时间的等待,前者可以在一个时间范围内智能的等待。
作者:Sandy
原文链接:https://blog.csdn.net/qq_44938404/article/details/105609917
- 0.00 查看剩余0%
- 【留下美好印记】赞赏支持
登录 后发表评论

北极测试员
+ 关注
热门文章
最新讲堂
温馨提示
- 推荐阅读
- 换一换
- 1.编写测试用例有哪几种方法?答:大刚法、等价类、边界值、因果图、场景法、正交法、错误推断法、正则表达式2.测试的六条基本法则是什么?答:功能、可靠性、易用性、效率、可维护性、可移植性3.软件测试分类有哪些?(从是否关心软件内部结构的角度划分)答:白盒、灰盒、黑盒4.软件测试的测试流程是什么?答:分析需求文档-需求评审-编写测试计划-计划评审-编写测试用例-用例评审-执行测试用例-迭代测试轮次-提交阶段性测试报告-验收测试-提交测试总结性报告5.编写测试用例的原则是什么?答:100%的覆盖需求规格说明书6.软件测试过程中必须经历哪些阶段?答:单元测试集成测试系统测试验收测试7.黑盒测试包含哪些...
-
- 一:等价类划分法 1:有效等价类: 2:无效等价类: 案例:比如一个登陆输入框,规定只能输入中文,同时长度为6-10。 通过等价类设计测试用例: 测试用例中重要的三步: 输入 操作 预计结果 如果与预期结果不符合就是bug。 有效等价类: 输入:输入长度为6的中文,输入的为王小明,这就是有效等价类。 无效等价类: 1: 输入长度为4的中文,输入位小名,点击登录,预计结果长度不符合要求。 2: 输入长度为6,但是是英文的,点击登录,预计结果 请输入中文。 3: 输入长度为4,而且不是中文的,是数字,1234,点击登录,预计结果请输入中文并且长度为6-10位。 4:输入长度...
-
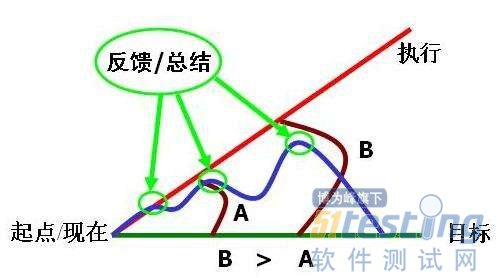
- 及时同步信息 在工作中,出现问题时应及时跟进并向关键人员同步进展。但实际工作中,比较常见的是问题出现后,你跟进得可能很及时,但问题产生的原因、影响、进展情况等信息的同步往往比较滞后,通常是主管或项目干系人询问你,你才反馈出来。如果你存在这样的情况,那么本文就是为你准备的。 一个问题的生命周期大体包含问题出现、问题发现、问题分析,问题定位,问题解决或改进几个环节,发现问题时就应该同步,而不是问题解决或改进了再同步。对于QA来说,日常工作的信息同步有两大类场景,一类是线上问题的同步,一来是项目进展的同步。 关于线上问题的同步 发现线上问题时,应第一时间反馈给你的主管。大体上包含如下几块...
-
- 最近参与了几次面试,面试者的简历中都会提及:需求或者版本测试结束后会进行测试总结,不仅仅提供一份测试报告以及相关文档手册。 于是特意追问了一下,测试总结中都包含什么内容。 答复上基本都是:执行了多少用例、发现了多少问题、解决了多少问题,待解决的问题还有多少、bug的修复率是多少,很少有其它方面的延伸。 于是自己也思考了一些,整理了这篇文章,也希望大家多多补充,提提意见。 一、何为测试总结 区别与测试报告一般是针对开发完成编码后对开发质量的一个总结。 测试总结站的角度,更多是在整个软件研发过程中所有问题的总结,总结的范围相对更宽一些。 包含需求搜集阶段的问题、产品需求分析设计阶...
-
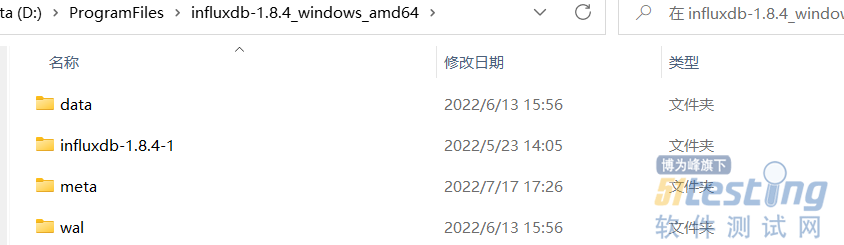
- 二、CentOS安装: 方式一:把下载的.rpm包推送到服务器上; 方式二:直接命令行安装#下载 wget https://dl.influxdata.com/influxdb/releases/influxdb-1.7.1.x86_64.rpm #安装 yum localinstall?influxdb-1.7.1.x86_64.rpm -y 2.3 修改配置文件 解压完成的InfluxDB,主要有四个文件夹:data、Influxdb-1.8.4.1、meta、wal,如下图: Meta目录:用于存储数据库的一些元数据,meta.db 文件; ...
-


——软件测试圈》&1.编写测试用例有哪几种方法?答:大刚法、等价类、边界值、因果图、场景法、正交法、错误推断法、正则表达式2.测试的六条基本法则是什么?答:功能、可靠性、易用性、效率、可维护性、可移植性3.软件测试分类有哪些?(从是否关心软件内部结构的角度划分)答:白盒、灰盒、黑盒4.软件测试的测试流程是什么?答:分析需求文档-需求评审-编写测试计划-计划评审-编写测试用例-用例评审-执行测试用例-迭代测试轮次-提交阶段性测试报告-验收测试-提交测试总结性报告5.编写测试用例的原则是什么?答:100%的覆盖需求规格说明书6.软件测试过程中必须经历哪些阶段?答:单元测试集成测试系统测试验收测试7.黑盒测试包含哪些...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=116966&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=116966&pic=http://quan.51testing.com/ueditor/php/upload/image/20210406/1617690683895027.jpg){kind=link}
{kind=link}
》& 二、CentOS安装: 方式一:把下载的.rpm包推送到服务器上; 方式二:直接命令行安装#下载
wget https://dl.influxdata.com/influxdb/releases/influxdb-1.7.1.x86_64.rpm
#安装
yum localinstall?influxdb-1.7.1.x86_64.rpm -y 2.3 修改配置文件 解压完成的InfluxDB,主要有四个文件夹:data、Influxdb-1.8.4.1、meta、wal,如下图: Meta目录:用于存储数据库的一些元数据,meta.db 文件; ...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=145810&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=145810&pic=http://quan.51testing.com/ueditor/php/upload/image/20230207/1675735967243901.png){kind=link}
温馨提示
打开微信 扫一扫
温馨提示
设置支付密码
- 关于我们 联系我们 版权声明 广告服务 站长统计
- 建议使用IE 11.0以上浏览器,800×600以上分辨率,法律顾问:上海兰迪律师事务所 项棋律师
- 版权所有 上海博为峰软件技术股份有限公司 Copyright©51testing.com 2003-2024, 沪ICP备05003035号
- 投诉及意见反馈:webmaster@51testing.com; 业务联系:service@51testing.com021-64471599-8017

- 51testing软件测试圈微信