 12
12 13
13


- 浅谈pytest+HttpRunner如何展开接口测试——软件测试圈
软件测试有多种多样的方法和技术,可以从不同角度对它们进行分类。其中,根据软件生命周期,针对不同的测试对象与目标,可将测试过程分为4个阶段:单元测试、集成测试、系统测试和验收测试。本文着重介绍了如何借用pytest与httprunner进行接口自动化测试。
一、 什么是接口测试
根据wiki中的定义,接口是一个共享的边界,计算机系统的多个独立组件通过它交换信息。这些信息的交换可以基于软件、硬件、外部设备、人和它们之间的组合。根据上述定义,可以面向软件、硬件、交互设备等展开接口测试。软件的接口测试是面向独立组件之间接口的一种测试,主要用于检测内外部系统及内部各子系统之间的交互点。测试的重点在于检查逻辑正确性、交互依赖性、数据正确性.
二、 引入自动化背景
基于以下几个情况,数栈引入自动化测试,以期提高测试效率,保障交付产品质量。
1、产品迭代迅速
目前数栈产品已经迭代至Release4.3版本。每过几个月进行一次产品release更新让回归测试的工作量持续上升。接口自动化测试可以很好的减少回归工作量。
2、应用系统日趋复杂
数栈目前自研8款产品和多个插件,产品之间的交互与产品-插件之间的交互日趋复杂。客观现实带来了更大的测试风险,测试消耗成本越来越高,花费的时间也越来越长。接口自动化测试可以提高测试效率。
3、部署环境多样
作为一款面向大数据的产品,除了开源的Hadoop,还需要适配TDH、CDH、HDP等其他引擎。同时,各种客户的POC环境也需要大量人力支持。
三、 自动化技术选型
接口测试可以使用的工具有很多,Postman、Jmeter、REST-Assured、SoapUI、httpclient等等。数栈产品使用的是HttpRunner这个框架。相比较于前几类工具,它具有以下特点:
1、简单易用。
虽然前几款工具中有图形化界面可以让人直观的进行操作,但HttpRunner以“关键字”的优势可以让QA快速的上手框架,对代码能力要求低。根据对应的关键字填入相应的值,即可生成一条测试用例。
2、可扩展性强
HttpRunner的V3版本支持了pytest,可以方便的借助pytest插件解决接口测试中遇到的问题,如数据驱动、参数化等。jUnit虽然也具有扩展性强的特点,但是Java语言对于QA来说太重,且学习成本比HttpRunner更高。
1、易于集成CI
HttpRunner支持CLI命令,可以方便的接入Jenkins、Gitlab CI等工具。
2、录制回放
通过Charles、Fiddler等工具将请求到处为.har文件,然后通过HttpRunner提供的命令,就可以将.har文件转换成json/yaml文件。
数栈产品曾使用过Jmeter作为接口自动化工具。Jmeter拥有可视化图形界面,通过拖动组件信息就可完成用例编排,方便QA使用。但是Jmeter的内置函数不能满足于复杂的数栈产品,虽然可以选择beanshell来写工具脚本,但其难以调试,第三方包管理困难等问题使编写效率低下。同时Jmeter容易出现编码混乱、日志不易于查看等问题。
HttpRunner作为一款优秀的开源框架,在GitHub上拥有2.6k star,集简单易用、扩展性强、易于集成、录制回放等特性于一体,相比较于Jmeter更适用于数栈自动化实践。
四、 自动化测试用例
数栈整体自动化测试架构如下图所示。从上到下可分为用户层、配置层、用例层、数据源。用户可以通过Docker镜像、Pipeline、定时任务来触发自动化任务。运行的结果记录到禅道,然后通过接入自研的EasyV进行展示。配置文件分为两类:一类是应用系统信息,如业务数据库信息、域名、账号密码等;另一类是数据源信息,用于用例的执行,现在支持的数据源有MySQL、Oracle、Kafka、HBase等等。从业务层面分,可以分为8个产品,每个产品编写各自的用例;从执行层面分,可分为接口测试和场景测试。若选择接口测试,则会运行所有产品的接口测试用例。下面拿接口测试用例进行举例说明。

一条接口测试用例可分为两部分:配置和测试步骤。先来看配置:
config = (
Config("测试创建项目接口")
.variables(
**{
"cookie": Cookie().get_cookie(),
"url": api.aiworks.aiworks_api.AiworksApi.create_project.value,
"tenant_name": ENV_CONF.uic.tenant_name,
"project_name": project_name
}
)
.base_url(ENV_CONF.base_url.rdos)
)首先第一个遇到的问题就是获取cookie。基本上接口都需要cookie或者token校验才能调用,因此将获取cookie的方法抽象提取成一个get_cookie(),避免了每个用例写一遍登陆。这个方法就属于架构图中预置函数的模块。url、tenant_name、project_name三个变量是后续测试步骤中所需要用到的变量值,这些都预先在variables中定义好。其中还可以看到有AiworksApi、ENV_CONF这几个文件。AiworksApi是所有Aiwork产品的接口枚举类,对接口内容进行管理;ENV_CONF包含了整个自动化项目的配置信息,是一个配置文件,属于配置层。
teststeps = [
Step(
RunRequest("开始请求创建项目接口")
.post("$url")
.with_headers(**{"cookie": "$cookie"})
.with_json(
{
"enableCycleSchedule": "$enableCycleSchedule",
"isSwitchJupyter": "$isSwitchJupyter",
"projectAlias": "$projectAlias",
"projectDesc": "$projectDesc",
"projectEngineList": "$projectEngineList",
"projectName": "$projectName",
"switchGpu": "$switchGpu"
}
)
.validate()
.assert_equal("status_code", 200)
.assert_equal("body.code", "$code")
.assert_contains("body.message", "$message")
.teardown_hook("${delete_project()}")
)
]然后在测试步骤部分,整个teststeps由Step数组构成。可以看到创建项目这个接口只有一个Step,整个Step分为post、with_headers、with_json、validate、teardown_hooke5个部分组成。其中,with_json中key-value键值对的值全都是引用的方式来取得,而不是写死的固定值。这样就可以将用例与数据区分开来。而具体的值则通过@pytest.mark.parameterize这个装饰器传入,params里定义了这个用例所需的所有字段值。整体用例编写思路为“用例与数据分离”,避免修改测试用例需要改动大量的代码。
@pytest.mark.parametrize("params", params)
def test_start(self, params):
super().test_start(params)所以整体来看,HttpRunner框架提供了一个用例模版--由多个关键字组成,使用者只需要将模版中的内容填充完整,就可以完成一条用例的编写。
五、自动化成果
自2021年4月自动化立项以来,已编写超过900条用例,8个子产品接口覆盖率平均达到60%以上。每日通过Jenkins构建定时任务,在持续集成环境对最新的代码进行自动化测试。同时,自动化测试接入了测试环境、客户环境中使用。在提供环境信息完备的情况下,可以随时接入自动化,并运行得出报告给到QA,大大减少了回归工作量,从原先3-4周的时间缩短到1-2周完成。
作者:袋鼠云数栈DTinsight
原文链接:https://my.oschina.net/u/3869098/blog/5286875
- -1.00 查看剩余0%
- 【留下美好印记】赞赏支持
热门文章
最新讲堂
- 推荐阅读
- 换一换
- 软件测试工程师需要掌握哪些技能呢?——软件测试圈08-17在谈到软件测试工程师时,许多人还是会想到那些重复使用软件并试图在频繁的操作中发现 BUG的人,也就是人们常说的按照测试规范和测试案例来测试软件,检查软件是否有错误,判断软件是否稳定。但这是一个很老派和错误的观点。 由于以上观念,导致软测试工程师在最初的十年中基本上处于较低的地位,认为测试工程师从事的是技术含量不高、随时可以取代的重复工作。 据调查,国内的软件测试,在互联网刚刚兴起的十多年间被冷眼对待,特别是那些没有配备软件测试人员的中小型软件企业,测试工作往往由开发岗位兼任,通常只进行简单的白盒测试,这种做法在一定程度上等于让用户也充当了测试的角色,造成的后果往往是用户发现一堆问题后进...
- 各位小伙伴们还记上个月小红书APP崩溃闪退,导致大批用户卸载APP重装的事故吗?闪退Bug从凌晨持续到第二天上午。 事发第二天,就有研发在线承认了,因为自己的失误导致了这次事件,评论区也有人担心博主会不会失去工作。 这件事会到此为止吗?有研发人员承认了错误,测试人员还需要负责吗? 也由此引出一个测试人员的最大疑问: 项目上线后出了严重Bug,到底是谁的责任? 目前存在如下两种观点: Mr.Zhou Mr.Zhou是企业的研发总监,他看到这个Bug时,确定是测试的锅。 他认为:测试工程师是软件产品质量的最后一个把关者,没有做好更新测试,才导致版本发布上线后APP更新崩溃。因此...
-
- 单元测试再出发03-31在构建软件系统时,测试是软件开发工作流程的必不可少的部分之一。作为软件开发人员,都希望编写的程序按预期工作。程序没有BUG,测试可以协助这个目标的达成。本文将讨论一种称为单元测试的测试方法。什么是单元测试?应该如何实施?单测优点和局限性是什么?什么是单元测试单元测试的目标是隔离程序的每个部分并显示各个部分按预期工作。单元测试是由软件开发人员编写和运行的自动化测试,以确保应用程序的一部分(称为单元)按预期工作。单元是可以在系统中逻辑隔离的最小代码段。这可以是单个函数、方法、过程、模块、类或对象。通常,一个单元有几个输入和一个输出。单元测试由软件开发人员在应用程序的开发(编码阶段)期间完成。只有各...
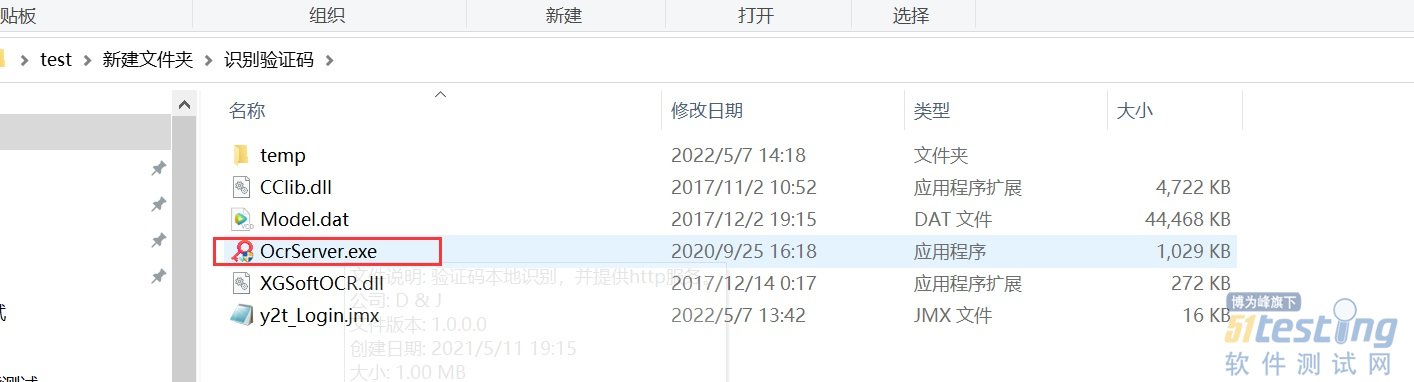
- Jmeter对图片验证码的处理——软件测试圈06-13jmeter对图片验证码的处理 在web端的登录接口经常会有图片验证码的输入,而且每次登录时图片验证码都是随机的;当通过jmeter做接口登录的时候要对图片验证码进行识别出图片中的字段,然后再登录接口中使用; 通过jmeter对图片验证码的识别方法 1、通过ocrserver工具识别图片验证码 如下图:解压后双击OcrServer.exe;然后电脑的右下角会显示该服务的IP和端口。 2、在jmeter中发送获取该验证码图片的接口;如下图 3、在获取验证码图片的接口下面添加监听器》保存响应到文件;如下图: 4、再取样器中再添加JSR223 Sampler;注释一下该...
- 入行软件测试,你需要知道这些——软件测试圈11-15互联网的发展使得各种软件APP越来越多,这些软件APP要想占领市场,肯定要拿质量说话。 如果一个软件或者APP质量不过关,出现很多bug,这将直接影响到用户体验,从而带给企业难以承受的损失。基于此,作为软件质量的把关者,软件测试也越来越受到重视。 面对这样的发展前景,越来越多的人开始学习软件测试,也有不少人转行到软件测试。 那么软件测试行业到底如何?有学历要求吗?收入怎样?以后发展前景好吗?到底值得入行吗?下面就给大家做一个深度剖析。 1、软件测试行业发展前景如何? 其实在开篇我们也提到了,随着大数据、云计算的发展,很多大厂都认识到一个问题。用户群体越大,系统就会有更高的概率带来...





{kind=link}
{kind=link}
{kind=link}
- 关于我们 联系我们 版权声明 广告服务 站长统计
- 建议使用IE 11.0以上浏览器,800×600以上分辨率,法律顾问:上海兰迪律师事务所 项棋律师
- 版权所有 上海博为峰软件技术股份有限公司 Copyright©51testing.com 2003-2024, 沪ICP备05003035号
- 投诉及意见反馈:webmaster@51testing.com; 业务联系:service@51testing.com021-64471599-8017

- 51testing软件测试圈微信