 0
0 0
0


- 12 个用于日常编程的杀手级 Python 代码片段——软件测试圈
1、正则表达式
正则表达式是 Python 中匹配模式、搜索和替换字符串、验证字符串等的最佳技术。现在,您无需为此类工作使用循环和列表。
查看以下关于验证电子邮件格式的正则表达式片段代码示例:
# Regular Expression Check Mail
import re
def Check_Mail(email):
pattern = re.compile(r'([A-Za-z0-9]+[.-_])*[A-Za-z0-9]+@[A-Za-z0-9-]+(\.[A-Z|a-z]{2,})+')
if re.fullmatch(pattern, email):
print("valid")
else:
print("Invalid")
Check_Mail("codedev101@gmail.com") #valid
Check_Mail("codedev101-haider@uni.edu") #Invalid
Check_Mail("code-101-work@my.net") # Invalid2、Pro Slicing
这个简单的代码片段将帮助您像专业人士一样对列表进行切片。查看下面的示例代码:
# Pro Slicing # list[start:end:step] mylist = [1, 2, 3, 5, 5, 6, 7, 8, 9, 12] mail ="codedev-medium@example.com" print(mylist[4:-3]) # 5 6 7 print(mail[8 : 14]) # medium
3、Swap without Temp
您是否使用 Temp 变量来交换两个数据,而不是在 Python 中您不需要使用它?在此代码段中,我将与您分享如何在不使用 temp 的情况下交换两个数据变量。
查看下面的代码:
# Swap without Temp i = 134 j = 431 [i, j] = [j, i] print(i) #431 print(j) #134
4、Magic of F-string
我们可能使用 format() 方法或“%”方法来格式化字符串中的变量。这段代码将向您介绍 F 字符串,它比另一种格式要好得多。
看看下面的示例代码:
# Magic of f-String
# Normal Method
name = "Codedev"
lang = "Python"
data = "{} is writing article on {}".format(name, lang)
print(data)
# Pro Method with f-string
data = f"{name} is writing article on {lang}"
print(data5、获取索引
现在您不再需要 Loop 来查找特定元素的索引。您可以使用列表中的 index() 方法来完成。
查看下面的代码:
# Get Index x = [10 ,20, 30, 40, 50] print(x.index(10)) # 0 print(x.index(30)) # 4 print(x.index(50)) # 2
6、基于Another List的排序列表
此代码段将向您展示如何根据另一个列表对列表进行排序。当您需要根据所需的位置进行排序时,此代码段非常方便。
# Sort List based on another List list1 = ["a", "b", "c", "d", "e", "f", "g", "h", "i", "j", "k", "l", "m"] list2 = [ 0, 1, 1, 1, 2, 2, 0, 1, 1, 3, 4] C = [x for _, x in sorted(zip(list2, list1), key=lambda pair: pair[0])] print(C) # ['a', 'g', 'b', 'c', 'd', 'h', 'i', 'e', 'f', 'j', 'k']
7、 反转字典
现在您不需要循环来反转任何字典。此代码段代码将在第二次尝试该代码段代码时反转字典。
# Invert the Dictionary
def Invert_Dictionary(data):
return {value: key for key, value in data.items()}
data = {"A": 1, "B":2, "C": 3}
invert = Invert_Dictionary(data)
print(invert) # {1: 'A', 2: 'B', 3: 'C'}8、多线程
多线程将帮助您同时并行运行 Python 函数。假设您想同时执行 5 个函数,而无需等待每个函数完成。
查看下面的代码段:
# Multi-threading import threading def func(num): for x in range(num): print(x) if __name__ == "__main__": t1 = threading.Thread(target=func, args=(10,)) t2 = threading.Thread(target=func, args=(20,)) t1.start() t2.start() t1.join() t2.join()
9、列表中出现最多的元素
此片段代码将简单地计算列表中出现次数最多的元素。我已经展示了两种方法来做到这一点。
在下面查看它:
# Element Occur most in List from collections import Counter mylst = ["a", "a", "b", "c", "a", "b","b", "c", "d", "a"] # Method 1 def occur_most1(mylst): return max(set(mylst), key=mylst.count) print(occur_most1(mylst)) # a # Method 2 # Much Faster then Method 1 def occur_most2(mylst): data = Counter(mylst) return data.most_common(1)[0][0] print(occur_most2(mylst)) # a
10、分割线
有一个逐行格式的原始文本,并希望将其分成几行。此代码段将在一秒钟内解决您的问题。
# Split lines
data1 = """Hello to
Python"""
data2 = """Programming
Langauges"""
print(data1.split("\n")) # ['Hello to', 'Python']
print(data2.split("\n")) # ['Programming', ' Langauges']11、 将列表映射到字典
此代码段将帮助您将任意两个列表转换为字典格式。要了解它是如何工作的,请查看下面的代码:
# Map List into Dictionary
def Convert_to_Dict(k, v):
return dict(zip(k, v))
k = ["a", "b", "c", "d", "e"]
v = [1, 2, 3, 4, 5]
print(Convert_to_Dict(k, v)) # {'a': 1, 'b': 2, 'c': 3, 'd': 4, 'e': 5}12、解析电子表格
现在您不需要 Pandas 或任何其他外部 Python 包来解析电子表格。Python 有一个内置的 CSV 模块,这段代码将向您展示如何使用它。
# Parse Spreadsheet
import csv
#Reading
with open("test.csv", "r") as file:
csv_reader = csv.reader(file)
for row in csv_reader:
print(row)
file.close()
#Writing
header = ["ID", "Languages"]
csv_data = [234, "Python", 344, "JavaScript", 567, "Dart"]
with open("test2.csv", 'w', newline="") as file:
csv_writer = csv.writer(file)
csv_writer.writerow(header)
csv_writer.writerows(csv_data)作者:佚名
- -1.00 查看剩余0%
- 【留下美好印记】赞赏支持

热门文章
最新讲堂
- 推荐阅读
- 换一换
- 尝试用金字塔原理来沟通08-07世界上最遥远的距离不是我说还是没说,而是我说了什么你却没明白是怎么回事。 最近小编有幸参加了一场金字塔原理的培训课程,金字塔原理帮助我们解决两大问题:思维混乱、逻辑不清,通过金字塔的学习,可以做到想清楚、说明白。下边小编通过小明的故事,跟大家分享一下金字塔原理的工作的方式。 一天,小明在电梯里遇到了部门领导,领导问:小明,好久不见,最近在忙什么? 小明瞬间脑袋空白,不知道如何回答,支支吾吾的说:还好,没忙什么,就是在做5.0版本的项目测试。 小明不开心的回到工位,看到了群群,群群帮他分忧,群群说:小明,你可以采用时间逻辑进行回答,比如我上个月在做一个创新项目升级策略的工具,这个月刚...
- 测试需要中台吗?——软件测试圈04-02TL;DR, 不需要!背景年前老东家裁员,我了解到的是原来不跟业务,纯做测试中台的几个同事基本都躺枪了,而技术不太行但是业务比较熟练的同事都留下了。这一波去中台化就很明显了。由于我在老东家也做测试中台,结合最近工作的感触,想聊聊这个事儿:测试到底需不需要中台?测试到底是干什么的我认为,测试工作的本质,就是平衡质量与效率。为了不出事故,总不能一点儿不测吧;为了能尽快发布,总不能事无巨细的测吧。执行质量和执行效率相同的前提下,用例越多,测试周期越长,质量越高。但是问题在于,用户会在意产品质量是不是100分么?并不是!精致的用户在意体验,严谨的用户在意稳定,大部分用户只在意能不能用。用户普...

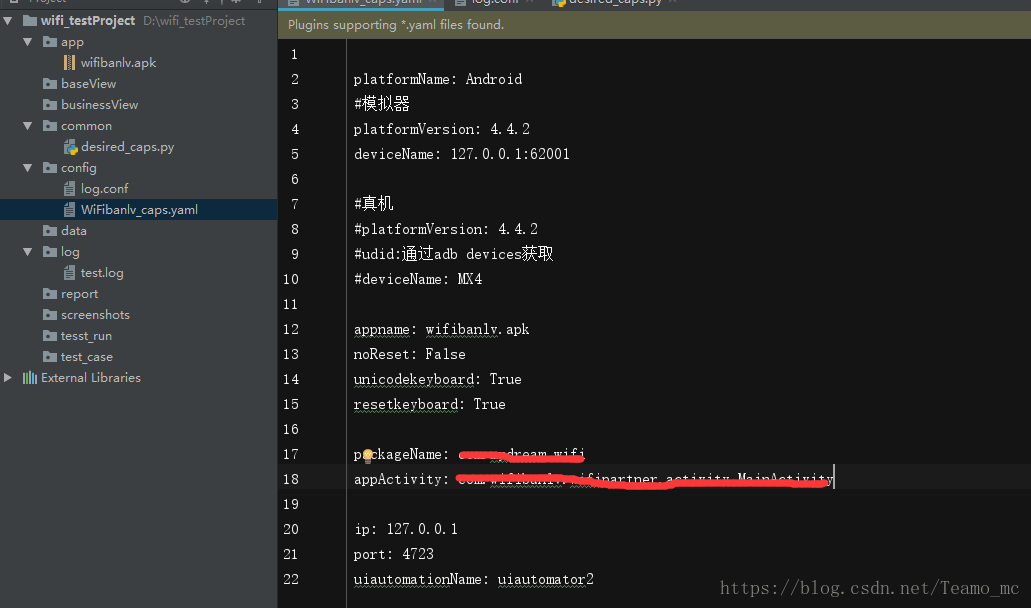
- 读取yaml配置文件:有两种方式,一个是file open,一个是with open方式1file = open('../config/WiFibanlv_caps.yaml', 'r') data = yaml.load(file) file.close() #必须使用close,否则文件会出现占用情况方式2:with open('../config/WiFibanlv_caps.yaml', 'r', encoding='utf-...
-
- 无论自动化或手工测试其主要目的都是为了持续提高产品的质量,无论企业的项目采取哪种软件开发模型, 自动化测试早已成为当下测试过程中不可或缺的一部分,增加自动化测试覆盖率也已被企业视为衡量测试团队效率的关键绩效指标(KPI)之一。 今天我们就来聊一聊Web自动化测试中的页面对象模型(POM),开启你对它的认知,探访POM是如何通过减少代码重复来有效减轻自动化维护的工作。 1. 页面对象模型(POM)攻略 页面对象模型是一种设计模式,其核心重点是通过减少代码重复,进而达到最小化代码更新/维护中涉及的工作量。 基于页面对象模型(POM)的实现包含以下关键要素: (1) 页面类(P...
-
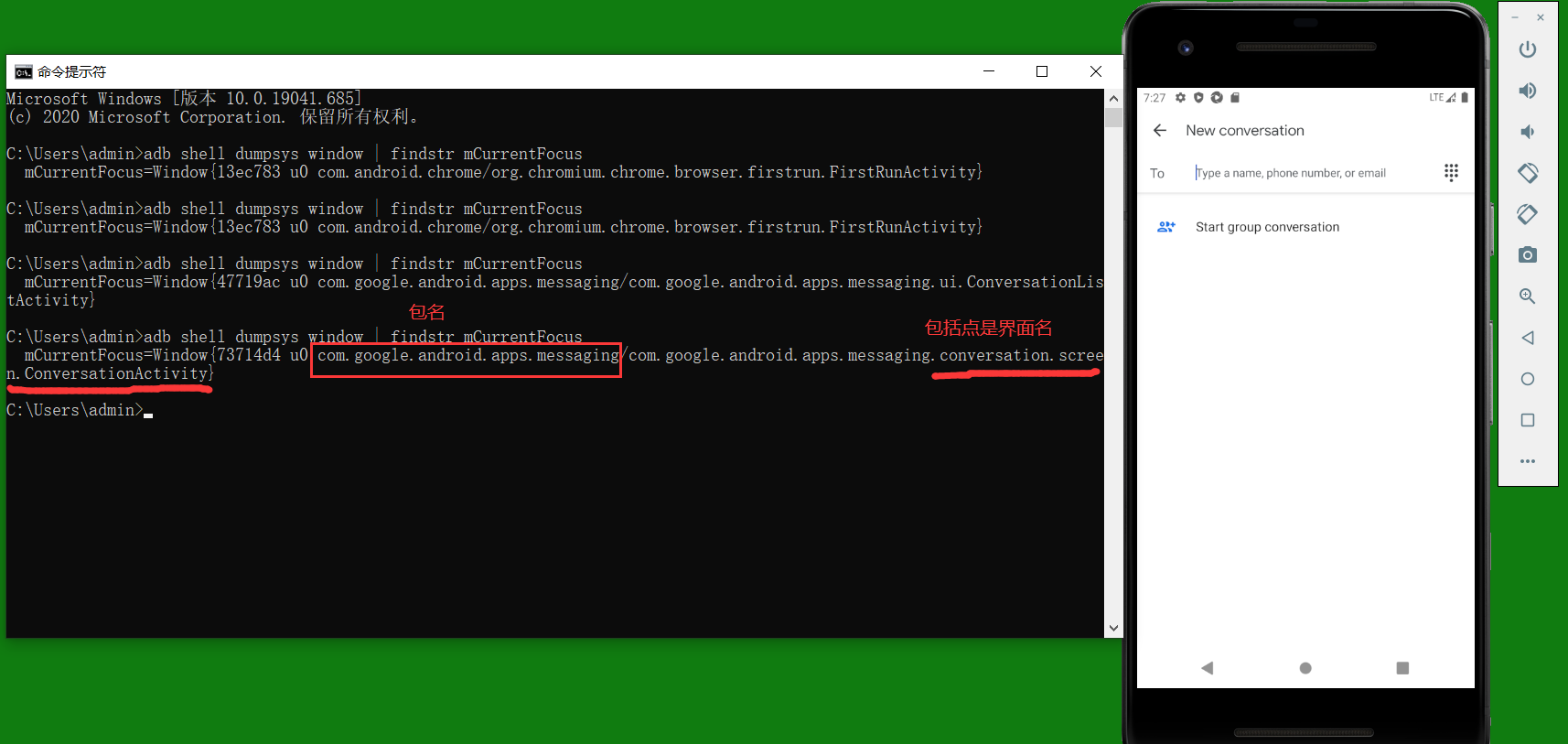
- 一、前提开启模拟器(我的是直接用的Android Studio的模拟器,所以在开启模拟器之前我还要开启Android Studio)打开appium服务器打开pycharm打开cmd二、上实战打开模拟器在cmd中输入代码:adb shell dumpsys window | findstr mCurrentFocus可查询到包名和界面名(界面名可以省略包名,但是我害怕漏了那个点,一般都不省略)比如说我的包名:com.google.android.apps.messaging界面名.conversation.screen.Convers...
-


{kind=link}
{kind=link}
-driver的封装(capability)》&读取yaml配置文件:有两种方式,一个是file open,一个是with open方式1file = open('../config/WiFibanlv_caps.yaml', 'r')
data = yaml.load(file)
file.close() #必须使用close,否则文件会出现占用情况方式2:with open('../config/WiFibanlv_caps.yaml', 'r', encoding='utf-...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=144950&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=144950&pic=http://quan.51testing.com/ueditor/php/upload/image/20220708/1657239331881387.png){kind=link}
之一。 今天我们就来聊一聊Web自动化测试中的页面对象模型(POM),开启你对它的认知,探访POM是如何通过减少代码重复来有效减轻自动化维护的工作。 1. 页面对象模型(POM)攻略 页面对象模型是一种设计模式,其核心重点是通过减少代码重复,进而达到最小化代码更新/维护中涉及的工作量。 基于页面对象模型(POM)的实现包含以下关键要素: (1) 页面类(P...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=143947&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=143947&pic=http://quan.51testing.com/ueditor/php/upload/image/20210802/1627875132524798.png){kind=link}
打开appium服务器打开pycharm打开cmd二、上实战打开模拟器在cmd中输入代码:adb shell dumpsys window | findstr mCurrentFocus可查询到包名和界面名(界面名可以省略包名,但是我害怕漏了那个点,一般都不省略)比如说我的包名:com.google.android.apps.messaging界面名.conversation.screen.Convers...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=1244&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=1244&pic=http://quan.51testing.com/ueditor/php/upload/image/20201229/1609228525150041.png){kind=link}
- 关于我们 联系我们 版权声明 广告服务 站长统计
- 建议使用IE 11.0以上浏览器,800×600以上分辨率,法律顾问:上海兰迪律师事务所 项棋律师
- 版权所有 上海博为峰软件技术股份有限公司 Copyright©51testing.com 2003-2024, 沪ICP备05003035号
- 投诉及意见反馈:webmaster@51testing.com; 业务联系:service@51testing.com021-64471599-8017

- 51testing软件测试圈微信