 0
0 0
0
分享


- Selenium真正绕过webdriver检测——软件测试圈
一、什么是真正绕过浏览器检测?
https://bot.sannysoft.com 这是chrome的真正检测网址
为什么要强调绕过webdriver属性检测?
有些网址通过webdriver检测使得Selenium无法获取元素、无法控制按钮等情况
1、PC环境打开chrome的效果

一般来说普通的启用webdriver即使也是会标红的,以上是打开本地chrome的检测属性
2、 普通的启动webdriver
上码
from selenium import webdriver
class WebDriverChrome(object):
def __init__(self):
self.driver = self.StartWebdriver()
def StartWebdriver(self):
options = webdriver.ChromeOptions()
options.add_argument("start-maximized")
options.add_experimental_option("excludeSwitches", ["enable-automation"])
options.add_experimental_option("useAutomationExtension", False)
driver = webdriver.Chrome(options=options)
return driver
def RunStart(self):
self.driver.get('https://bot.sannysoft.com')
# time.sleep(10)
# self.driver.quit()
if __name__ == '__main__':
Crawl = WebDriverChrome()
Crawl.RunStart()
3、Js注入真正绕过webdriver的检测属性
为什么我注入的js属性有效?
该js文件是pyppetter中绕过webdriver检测所用到的
现在直接导入到Selenium启动的chrome中
上码:
from selenium import webdriver
class WebDriverChrome(object):
def __init__(self):
self.driver = self.StartWebdriver()
def StartWebdriver(self):
options = webdriver.ChromeOptions()
options.add_argument("start-maximized")
options.add_experimental_option("excludeSwitches", ["enable-automation"])
options.add_experimental_option("useAutomationExtension", False)
driver = webdriver.Chrome(options=options)
with open('./stealth.min.js') as f:
js = f.read()
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": js
})
return driver
def RunStart(self):
self.driver.get('https://bot.sannysoft.com')
# time.sleep(10)
# self.driver.quit()
if __name__ == '__main__':
Crawl = WebDriverChrome()
Crawl.RunStart()
js注入的文件[stealth.min.js]
命名不统一要求能读取就可以了
获取方式:
安装node.js
npx extract-stealth-evasions
就会在你执行命令的文件夹下面生成一个stealth.min.js文件
作者:顽强拼搏的阿k
原文链接:https://blog.csdn.net/weixin_38640052/article/details/112692031
- -1.00 查看剩余0%
- 【留下美好印记】赞赏支持
登录 后发表评论

饭团🍙测试白白
+ 关注
热门文章
最新讲堂
温馨提示
- 推荐阅读
- 换一换
- 【原创】做软件测试有前途么?03-13看到这个问题你是不是已经笑了?当然我也做好了挨喷的准备了。我搜了一下知乎,同样的问题可以翻好几页,回答的观点也各式各样,但是没有一个统一的高赞答案,今天我姑且谈谈我的个人看法,欢迎大家一起讨论。来来来,坐好啦,先给大家说说我自己关于选择的故事。一、学习 Java 有前途么?我是 2005 年开始学习 Java 的,应该是相当早了(暴露年龄了),那时的我还没大学毕业,所以在学习前、学习中、学习后的所有阶段,「Java 是否有前途」的问题,一直让我惶惶不得终日,我当时也上网搜了很多次这个问题,看了几乎所有的观点,结果和现在一样,并没有一个统一的高赞答案。有说很有前途的,毕竟当时的 Python 还...
- 软件测试之测试的基本功——软件测试圈10-18结合笔者所在团队的实际情况,团队的目标是要能够快速反应,支持业务快速迭代,同时要把测试人员从繁重的重复工作中解放出来,为内外提供赋能,提供好的测试平台、好用的测试工具和高效的测试方法等,这就对测试人员提出了一些新的要求。1.代码具备编写代码能力能够提高测试效率,独立或者辅助开发人员定位问题,而不是只报告问题,这也有助于帮助测试人员了解程序过程,完善思维方式,提升测试形象。在测试过程中懂程序的人更能够深入地把程序测试好,通过走读代码发现逻辑上的缺陷、写法上的繁琐带来的性能问题等,达到事半功倍。系统与数据库打交道,程序部署在中间件上,中间件运行在操作系统上,即要懂数据库知识、中间件知识、操作系统知...
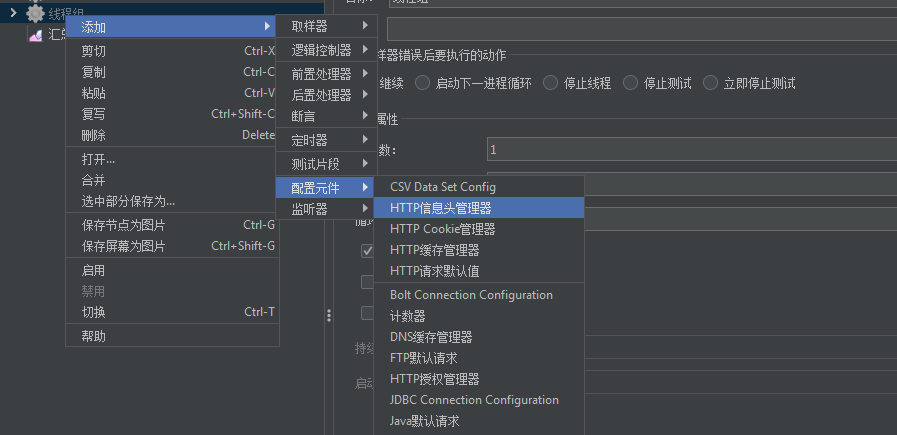
- 教你在Jmeter里添加Post请求07-18添加http的post请求和get请求思路是一致的,步骤也是基本相同的。 简单来说,就是在测试计划上添加线程组,然后添加HTTP请求(类型选择POST)、 添加HTTP信息头管理器、添加监视器。 添加HTTP请求步骤请参考添加Get请求部分:http://quan.51testing.com/pcQuan/article/144959,这里就不再赘述了。 在之前建的线程组里添加一个HTTP请求,请求类型选择POST。需要注意的是添加POST请...
- 如何写出让业务满意的性能测试报告——软件测试圈03-28前言春节前在北京出差,和同事聊到了一个关于流量网关如何进行性能验证的需求,当时写了一篇文章《聊了简单的话题:如何分析性能需求》。结果节后上班同事找到我,希望我帮他们写一份给到业务团队的性能测试报告,原因是业务觉得他们之前提供的报告不够充分。这篇文章,来聊聊我对这个需求的分析和理解,以及如写出让业务满意的性能测试报告。需求背景需求背景实际上在前面的文章《聊了简单的话题:如何分析性能需求》中已经提到了,写性能测试报告的初衷,是目前的组织架构和业务形态决定的。我目前在Application Infrastructure团队,负责测试开发和性能及稳定性相关工作,由于公司是纵向的独立BU式的组织架构,基...
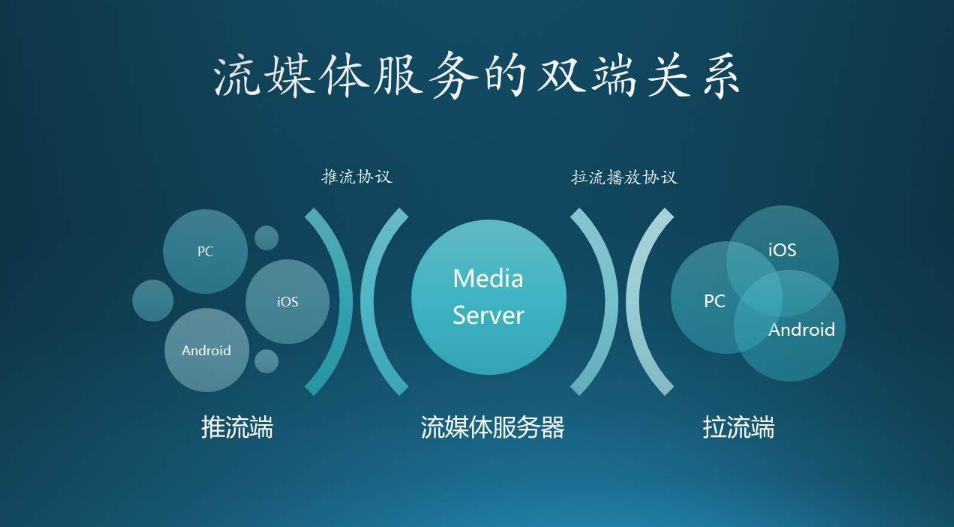
- 视频直播平台性能测试——软件测试圈03-011、测试背景 随着直播业务的兴起,越来越多的直播平台开始涌现,这火热的程度好像一个应用不带上直播业务出来都不好意思跟人打招呼。 公司也在赶时髦,做了一个直播平台,直播内容是面向公司内部员工的,还有少量外部用户。直播平台好不好,最重要的一点是观众观看是否流畅是否清晰,能否满足较多的人观看。平台需要进行测试是否满足大量用户观看直播,这么重要的事情当然要交给性能测试人员来做。2、直播技术 一般来说,我们常把视频直播的流程可以分为如下几步:&nbs...




、 添加HTTP信息头管理器、添加监视器。 添加HTTP请求步骤请参考添加Get请求部分:http://quan.51testing.com/pcQuan/article/144959,这里就不再赘述了。 在之前建的线程组里添加一个HTTP请求,请求类型选择POST。需要注意的是添加POST请...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=145016&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=145016&pic=http://quan.51testing.com/ueditor/php/upload/image/20220715/1657875905420008.png){kind=link}
{kind=link}
温馨提示
打开微信 扫一扫
温馨提示
设置支付密码
- 关于我们 联系我们 版权声明 广告服务 站长统计
- 建议使用IE 11.0以上浏览器,800×600以上分辨率,法律顾问:上海兰迪律师事务所 项棋律师
- 版权所有 上海博为峰软件技术股份有限公司 Copyright©51testing.com 2003-2024, 沪ICP备05003035号
- 投诉及意见反馈:webmaster@51testing.com; 业务联系:service@51testing.com021-64471599-8017

- 51testing软件测试圈微信