 0
0 0
0


- 轻松理解ES(elasticsearch)搜索引擎(图)——软件测试圈
我们在开发测试过程中是不是常常会因为查询效率低下而感到苦恼?
把数据都存在数据库中,通过建立索引可以提高数据查询效率,但是如果我们查找的数据索引无法生效,数据库一条一条的判断效率又得不到提升。
这里我们给大家介绍一种能够在大数据量下提高查询效率的方法ES(elasticsearch)搜索引擎,接下来我们从什么是搜索、普通搜索面临的问题和ES如何解决这些问题这几个方面,让大家快速理解ES搜索引擎。
什么是搜索
简单的说搜索就是我们在搜索框输入关键词,查找哪些网页包含对应的关键词的过程。
例如:用户在搜索框输入一个词,客户端软件发送一个请求到后台,后台通过sql语句从数据库中找出相关条目(数据库会一条一条对比),这就是一个最简单搜索原型。
普通搜索面临的问题
1、当网页很多时,假如1000万个网页呢,即使服务器的性能足够快,从用户角度,从点击搜索按钮到看到搜索结果可能要很长时间,1小时?2小时?甚至好几天?
2、当数据量达到几十T,一台服务器已经放不下了,这时候就需要多台,这就是分布式。
这时候数据就在不同的服务器了,一个客户端不可能去请求每台机器,所以就需要一个管理员角色,负责把客户端请求分发到每台机器,同时汇总结果返回给客户端。
ES搜索引擎如何解决这些问题
建立倒排索引
正向的查找数据需要消耗大量的时间,我们可否反过来进行存存储呢,现在我们有很多网页,如何才能快速的查到对应的网页呢?
我们知道哈希表的查找效率特别快,借鉴一下哈希表,我们给每个网页都打上标签,每个标签和对应的网页建立对应的映射,我们通过标签与网页的映射关系就可以马上找到对应的网页了。
首先把所有的原始数据进行编号,形成文档列表如图1:

图1 原始数据进行编号
其次,把文档数据进行分词,得到很多的词条,以词条为索引。
保存包含这些词条的文档的编号信息,如图2:

图2 分词与原始数据对应关系
当用户输入任意的词条时,首先对用户输入的数据进行分词,得到用户要搜索的所有词条,然后拿着这些词条去倒排索引列表中进行匹配。找到这些词条就能找到包含这些词条的所有文档的编号。
分布式的实现
Elasticsearch 也是会对数据进行切分,同时每一个分片会保存多个副本,其原因是为了保证分布式环境下的高可用。
在 ES中,节点是对等的,节点间会通过自己的一些规则选取集群的 Master,Master 会负责集群状态信息的改变,并同步给其他节点。
值得注意的是,只有建立索引和类型需要经过 Master,数据的写入有一个简单的 Routing 规则,可以 Route 到集群中的任意节点,所以数据写入压力是分散在整个集群的。
Elasticsearch 建立一个索引,这个索引可以拆分成多个 shard,每个 shard 存储部分数据。
这个shard 的数据实际是有多个备份,就是说每个 shard 都有一个 primary shard,负责写入数据,但是还有几个 replica shard。
primary shard 写入数据之后,会将数据同步到其他几个 replica shard 上去,如图3,通过这个 replica 的方案,每个 shard 的数据都有多个备份,如果某个机器宕机了,还有别的数据副本在别的机器上。

图3分布式搜索引擎架构图
总结
本文从什么是搜索、普通搜索面临的问题和ES如何解决这些问题这几个方面,让大家快速理解ES搜索引擎。
ES通过倒排索引提高了大数据下的数据查询效率,通过分布式的方式实现了大数据的存储与系统的高可用,采用ES搜索引擎可满足大数据量下的数据查询场景,利用现有的框架可极大地缩小开发成本,提升用户的使用体验。
作者:崔岢
- -1.00 查看剩余0%
- 【留下美好印记】赞赏支持

热门文章
最新讲堂
- 推荐阅读
- 换一换
- 1. linux目录与文件Windows: 以多根的方式组织文件 C:\ D:\ E:Linux: 以单根的方式组织文件 /[root@c7-4 /]# ls bin boot dev etc home lib lib64 media mnt opt proc root run sbin&nb...
-
- 前言 测试过程中经常会遇到需要将本地的文件上传到远程服务器上,或者需要将服务器上的文件拉到本地进行操作,以前安静经常会用到xftp工具。今天安静介绍一种python库Paramiko,可以帮助我们通过代码的方式进行完成对远程服务器的上传和下载操作,也可以进行对远程服务器输入操作命令。 Paramiko Paramiko属于python的一个第三方库,可以远程连接Linux服务器,进行通过python进行对Linux进行操作,可以实现进行对远程服务器进行下载和上传文件操作。 安装 既然是第三方库,我们可以通过pip进行安装:pip install paramik...

-
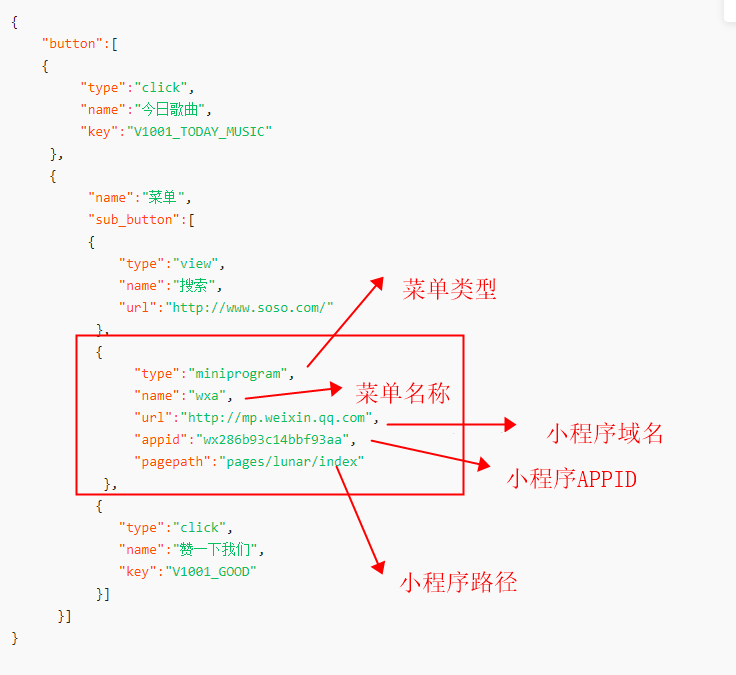
- 微信公众号跳转到小程序的几种方式——软件测试圈03-08摘要:记录开发过程中遇到的问题,希望对诸君有所帮助,快速解决开发中遇到的类似问题。最近再开发过程中,因为公司增加了小程序业务,需在公众号中增加小程序的跳转,故将公众号跳转小程序的方法整理如下,供诸位使用,避免采坑。重点:只能跳转与公众号关联的小程序。1、公众号自定义菜单跳转到小程序http请求方式:POST(请使用https协议)接口:https://api.weixin.qq.com/cgi-bin/menu/create?access_token=ACCESS_TOKEN;自定义菜单格式如下:2、开放标签跳转小程序:1. 引入JS文件在需要调用JS接口的页面引入如下JS文件:http://...
- 节省时间的分层测试,到底怎么做?——软件测试圈05-26为什么要做分层测试 从软件工程的角度,结合软件开发的V模型、MVC架构、测试金字塔,综合起来便于理解。 1.借鉴与软件开发的V模型 从V模型的底部往右上方向,先做单元测试,再做集成测试一直到最后的验收测试。 2.来源于MVC架构 MVC全名是Model View Controller,是模型(model)-视图(view)-控制器(controller)的缩写。 我们可以简单理解为V是用户看到的界面,C是中间逻辑,M是数据。对于现在流行的微服务SOA来说,V就是前端WEB或者APP, C就是中间密密麻麻的各种接口,M就是最下层的数据: 3.来源于测试金子塔 testing ...

- Postman接口自动化测试实战——软件测试圈02-11Postman可用来实现简单的接口自动化测试,也可对接口进行压力测试一:相关知识回顾1、测试沙箱与测试断言实战测试沙箱常用功能:postman测试沙箱其实是结合js脚本完成测试中都功能,在请求发起前后实现部分测试操作常用功能:请求前脚本(pre-request scripts)设置请求前置操作如设置变量等请求后对状态码,响应头,响应正文等信息进行断言操作使用console控制台进行调试:通过console查看接口请求返回信息,以及对脚本中使用的变量进行输出调试等操作2、测试集与数据驱动为了方便的管理接口请求的执行,可通过postman测试集(collection)来完成测试的操作,每一个测试请...

{kind=link}
接口:https://api.weixin.qq.com/cgi-bin/menu/create?access_token=ACCESS_TOKEN;自定义菜单格式如下:2、开放标签跳转小程序:1. 引入JS文件在需要调用JS接口的页面引入如下JS文件:http://...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=144536&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=144536&pic=http://quan.51testing.com/ueditor/php/upload/image/20220308/1646707866431275.png){kind=link}
-视图(view)-控制器(controller)的缩写。 我们可以简单理解为V是用户看到的界面,C是中间逻辑,M是数据。对于现在流行的微服务SOA来说,V就是前端WEB或者APP, C就是中间密密麻麻的各种接口,M就是最下层的数据: 3.来源于测试金子塔 testing ...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=146164&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=146164&pic=http://quan.51testing.com/ueditor/php/upload/image/20230526/1685087133539222.png){kind=link}
设置请求前置操作如设置变量等请求后对状态码,响应头,响应正文等信息进行断言操作使用console控制台进行调试:通过console查看接口请求返回信息,以及对脚本中使用的变量进行输出调试等操作2、测试集与数据驱动为了方便的管理接口请求的执行,可通过postman测试集(collection)来完成测试的操作,每一个测试请...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=144486&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=144486&pic=http://quan.51testing.com/ueditor/php/upload/image/20220211/1644568852689209.jpg){kind=link}
- 关于我们 联系我们 版权声明 广告服务 站长统计
- 建议使用IE 11.0以上浏览器,800×600以上分辨率,法律顾问:上海兰迪律师事务所 项棋律师
- 版权所有 上海博为峰软件技术股份有限公司 Copyright©51testing.com 2003-2024, 沪ICP备05003035号
- 投诉及意见反馈:webmaster@51testing.com; 业务联系:service@51testing.com021-64471599-8017

- 51testing软件测试圈微信