 11
11 11
11


- 录制线上流量做回归测试的正确打开方式——软件测试圈
线上流量
什么是录制线上流量回放

为什么需要录制线上流量回放
项目大迭代更新,容易漏测,或者有很多没用评估到的地方。
如果用线上流量做一次回归测试,可以进一步减少 bug 的风险。
大大节省构造测试数据,或者构造测试数据脚本的时间,提高效率。
线上流量回放的限制是什么
· 只回放 GET 请求
因为其他请求的回放,会对用户数据进行操作,有风险,需要排除。
除非构建多套备份数据库,但成本太高,不是很有必要。
· 需要对比回放前后的流量
不然回放就没有意义了,你都不知道回放前后对比的差异是什么。
· 需要去噪音
对比完了,对于一些类似时间戳的值,其实就是噪音,这些不一样很正常,我们需要剔除,不然差异没有价值。
由此可见,想要正确打开线上流量录制回放,需要解决很多问题。
而重中之重,就是 diff。
回放差异 diff
diff 实现对比和去噪

demo 实现
docker-compose
version: '2' services: http-demo-record: image: shaonian/http-demo:gor-test-v2.9 ports: - "8080:8080" http-demo-replay-old: image: shaonian/http-demo:diff-old-1 http-demo-replay-old-noise: image: shaonian/http-demo:diff-old-2 http-demo-replay-new: image: shaonian/http-demo:diff-new diff: image: shaonian/diff:v0.1 command: - -candidate=http-demo-replay-new:8080 - -master.primary=http-demo-replay-old:8080 - -master.secondary=http-demo-replay-old-noise:8080 - -service.protocol=http - -serviceName='Diff Test' - -proxy.port=:8880 - -admin.port=:8881 - -http.port=:8888 - -rootUrl=localhost:8888 - -summary.email='your@email.com' ports: - "8881:8881" - "8888:8888"
diff 效果

diff 限制
diff 的归类有问题。
因为 url 能携带各种各样的 param,所以 diff 设计里面不会直接把 url 作为归纳名,需要通过在请求的 header 里面增加 Canonical-Resource: http-demo 来设置。
这就出来一个问题,线上转发的流量,无法根据具体的路由来动态设置归纳名,只能统一设置成是一个服务的,比如 http-demo 这样,但是我这个 http-demo 下有很多 api,出来的差异具体是哪一个 api 呢,我也不知道,得看返回字段去猜,就很华而不实。
所以做到这里,只能自嗨,无法落地到实际项目中,想要真正落地,这一步也是一定一定要解决的!
缺陷
以上实现的方法总结起来,就是把录制 gor 组件写进 Dockerfile,并在项目运行的时候,实时录制线上流量,转发到测试环境,然后进行 diff 去噪对比。
但是这样就大功告成了吗?
并没有。
还有几个问题需要自我反问一下。
· 我们真的需要实时录制转发吗?
其实不需要。
我们只是希望能够录制线上请求,然后根据再迭代之后用来回放测试。
如果开启实时回放,会在我们不需要测试的时候,浪费服务器的性能和资源。
· 线上录制的回放,真的就代表全部场景吗?
其实也不对。
用户不一定不触发的场景,其实我们也需要覆盖。
录制只是让我们更容易更便捷生成测试数据而已。
· 线上录制会有性能损耗吗?
或多或少都有影响,毕竟 gor 和 服务处于同一个容器中。
所以三个反问以后,我们的需求逐渐明确了。
我们需要一个不会影响线上服务性能的,又能快速生成测试数据回放,并且能自定义补全更多场景的测试回放。
同时,我们还需要解决 diff 的路由智能匹配的问题。
这样可以吗?
我觉得可以。
尝试的解决方案
可以通过复制粘贴人为构造回放所需的测试数据日志

上图是录制流量以后保存的 log 文件,我们可以清楚看到它的结构,所以这是不是意味着,只要我们写出来这份相同格式的 log,我们就能直接凭借这份 log 来回放呢?
对的。
此外,这个 log 里面,你可以直接根据具体的 url,设置好相应的 Canonical-Resource,就直接解决了 diff 路由归纳名的问题。
而且,我们根本不需要真的到线上去录制,伪造一份这样格式的 log,甚至还可以直接修改补全一些没有的场景进去,就可以直接以此为范本,作为回放 log 的效果了。
这样也根本不需要担心线上录制会影响线上服务器的性能和资源。
解决所有问题以后,还有什么不优雅的地方
那 log 我也得复制粘贴去生成,而且 log 里面的时间戳排序,我也得自己造,这样看似方便,其实只是方便了不用手写代码来编造测试数据,可以直接通过编写 log 就能回放流量。
也就是,这样的方案,只是降低了测试技术栈的门槛,提高了一点点的效率。
而且还有个问题,很多的数据,我其实是动态生成的,我传进去之前,还得通过其他接口去获取返回值,再动态填进去,这样写 log 并不能实现啊。
还有,很多参数也有时效问题,过段时间 token 过期了,我替换 token 也很麻烦。
就算,设置成万能的 token,那涉及到用户的数据,比如有些业务场景 token 里面包含了某类用户具体信息的时候,万能 token 就不管用了,因为有很多自定义的数据要去测。
所以,看似解决完所有技术栈问题以后,其实还有很多业务问题,导致它使用场景有限,甚至无法完全落地。
正确打开方式
为什么要拘泥于用线上流量来回放呢?
如果我的脚本能够批量构造大量且覆盖众多场景,且可高度自定义的请求,再将这些请求直接去请求 diff,不就能直接对比出前后有什么差异吗?
何况,就算我的内部 rpc 服务调用更改,变得更加复杂,但是暴露在外给用户的业务操作,是不会发生大改的。
而且此前,基于项目 shaonian/boomer_locust 的压测工具,我之前已经实现了全链路压测的业务逻辑覆盖。
所以这里完全可以引出一个全新的概念,用可控速度的压测工具,以及高度灵活的编程脚本,实现大批量构造测试数据,模拟业务场景压力,并直接实现前后对比差异的不同。
因为数据全部都是新构造好的,所以不止 GET 请求我可以做,POST PUT DELETE 请求我也可以,因为数据都是我构造上传的,如果在测试环境中,完全删掉都不会有影响,而且只要设置好前后的测试脏数据的清理,其实线上数据库都能做。(当然,直接做到 stage 环境数据库就可以了,prod 没必要。)
进一步完善
既然正确打开了前后版本的快速 diff 测试,那么如何进一步完善呢?
当然是提高脚本的业务覆盖场景,已经代码覆盖率。
如何判断自己的构造回归流量,尽可能覆盖完全呢?
我们可以引入代码的实时染色,在本地就先测好覆盖率,再去部署上线。
这个代码实时染色,可以基于 goc 在 vscode 的插件来实现。

录制线上流量做回归测试的正确打开方式
至此,快速构造测试数据,对比前后版本的方案成型,且可根据业务定制脚本,可落地实现,真正意义上地实现回归 diff 测试。
由此为基础以后,下一步,当然就是精准化测试,也是未来测试的大势所趋。
作者:美好一点
来源:http://www.51testing.com/html/51/n-4477851.html
- -1.00 查看剩余0%
- 【留下美好印记】赞赏支持

热门文章
最新讲堂
- 推荐阅读
- 换一换
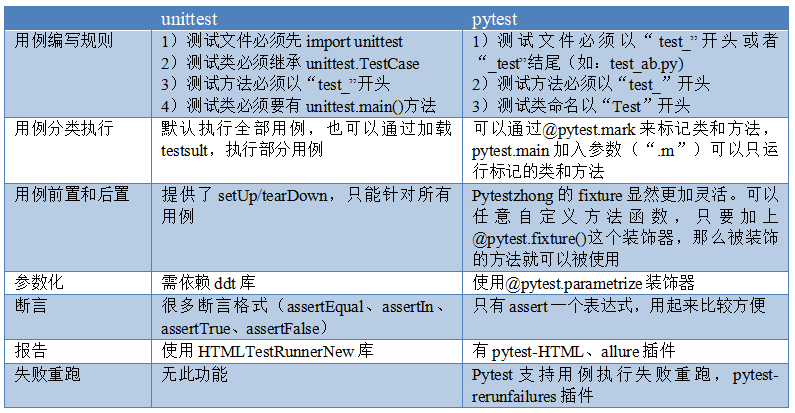
- 最近在这整理知识,发现在pytest的知识文档缺少系统性,这里整理一下,方便后续回忆。 在python中,大家比较熟悉的两个框架是unittest和pytest: ·Unittest是Python标准库中自带的单元测试框架,Unittest有时候也被称为PyUnit,就像JUnit是Java语言的标准单元测试框架一样,Unittest则是Python语言的标准单元测试框架。 · Pytest是Python的另一个第三方单元测试库。它的目的是让单元测试变得更容易,并且也能扩展到支持应用层面复杂的功能测试。 两者之间的区别如下: 这里试用的pytest框架,加上reques...
-
- 小编看到过这样的一个帖子,根据题主的描述可以看出来他是一名拥有十年工作经验的功能测试人员,目前掌握的技能还只是简单的功能测试,没有什么代码能力,面对功能测试的职场窘境,正在选择下一步该转测试开发还是软件开发?其实现在像题主一样处境的人不在少数,这就是行业技术发展的趋势导致。开篇之前,小编直接亮明观点,在测试开发和软件开发之间,选择前者的发展会永远比后者好。 这篇文章将从以下三个方面阐述我的观点: ·功能测试为什么不建议选择软件开发? · 为什么功能测试会产生转行软件开发的想法? · 功能测试如何晋升测试开发? 一、功能测试为什么不建议选择软件开发? 表面看,...

-
- 想必金字塔测试原理大家已经很熟悉了,近年来的测试驱动开放在各个公司开始盛行,测试代码先写的倡议被反复提及。 鉴于此,许多中大型软件公司对单元测试的要求也逐渐提高。那么,编写单元测试有哪些小技巧可以借鉴和学习的呢? 测试代码文件路径与开发代码文件路径“相同” 这里的“相同”并不是完全意义的一摸一样,测试代码和开发代码处于同一目录,而是指的测试代码文件路径你与开发代码文件路径“大体相同”。 如下图1、2所示,开发代码路径和测试代码路径都包括/java/ru/yandex/clickhouse/。图1 开发代码路径图2 测试代码路径 测试代码文件名清晰 清晰的测试代码文件名可以帮助阅...

-
- 苹果在一份支持文件中宣布,它将在2023年7月26日下线"我的照片流"。这项服务已经提供了十多年,允许用户通过互联网在苹果设备上同步他们的照片。这项图片同步服务最初被称为"照片流",是在2011年WWDC期间宣布的。它可以自动从iPhone或iPad上传多达1000张最近点击的照片到iCloud。 上传的媒体在云端停留长达30天,并自动下载到使用同一苹果ID的其他设备上,包括Mac和WindowsPC。同样,当年在Mac上导入iPhoto应用的新图片也会被上传到云端,并在不同设备间同步。 最终,在上传所有照片、视频以及对媒体进行编辑的iCloud...

-
- 前言 自动化执行结果都需要有个报告来展示,常用的报告有HTMLTestRunner,pytest-html,Allure。这三种报告各有不同,本文主要介绍如何通过python来生成Alluer报告。 Allure Alluer属于一种开源的测试框架,可以基于多种语言进行使用,如java的junit,python的pytest。alluer生成的报告内容比较美观,目前测试中常用的测试报告。Allure的环境是基于java环境的,前提条件需要将java的环境安装完成(下载JDK,配置环境变量)。 下载地址:https://github.com/allure-framework/allu...
-
{kind=link}
{kind=link}
{kind=link}
{kind=link}
。 下载地址:https://github.com/allure-framework/allu...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=117185&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=117185&pic=http://quan.51testing.com/ueditor/php/upload/image/20210617/1623894263243055.png){kind=link}
- 关于我们 联系我们 版权声明 广告服务 站长统计
- 建议使用IE 11.0以上浏览器,800×600以上分辨率,法律顾问:上海兰迪律师事务所 项棋律师
- 版权所有 上海博为峰软件技术股份有限公司 Copyright©51testing.com 2003-2024, 沪ICP备05003035号
- 投诉及意见反馈:webmaster@51testing.com; 业务联系:service@51testing.com021-64471599-8017

- 51testing软件测试圈微信