 0
0 0
0


- pytest+requests+allure自动化测试——软件测试圈
最近在这整理知识,发现在pytest的知识文档缺少系统性,这里整理一下,方便后续回忆。
在python中,大家比较熟悉的两个框架是unittest和pytest:
·Unittest是Python标准库中自带的单元测试框架,Unittest有时候也被称为PyUnit,就像JUnit是Java语言的标准单元测试框架一样,Unittest则是Python语言的标准单元测试框架。
· Pytest是Python的另一个第三方单元测试库。它的目的是让单元测试变得更容易,并且也能扩展到支持应用层面复杂的功能测试。
两者之间的区别如下:

这里试用的pytest框架,加上request来实现接口自动化的测试,整个框架考虑到使用数据驱动的方式,将数据维护在Excel文档中。
1、下载安装allure
下载地址:https://github.com/allure-framework/allure2/releases
https://repo.maven.apache.org/maven2/io/qameta/allure/allure-commandline/
选择需要的版本下载,这里我下载的是2.13.2版本。
下载好后,解压到你需要存放的路目录,并配置环境变量。

检查是否配置成功,执行cmd,输入命令 allure,出现如下图,则表示安装成功。

2、下载安装python
下载地址https://www.python.org/
下载好后,安装并配置环境变量,具体流程可以网络查找。
3、python安装依赖包
cmd命令执行,也可以通过项目中的requirements.txt来安装,安装步骤后面再说。
pip3 install allure-pytest pip3 install pytest pip3 install pytest_html pip3 install request
4、下载并安装pycharm工具
查看网络教程。
5、在pycharm,新建项目及编码

项目目录如图:
base:存放一些最底层的方法封装,协议,请求发送等。
common:存放一些公共方法。
config:存放配置文件。
testData:存放测试数据。
log:存放日志。
report:存放报告。
testCase:存放用例。
utils:存放公共类。
readme:用于说明文档。
requirements.txt: 用于记录所有依赖包极其版本号,便于环境部署,可以通过pip命令自动生成和安装。

这里采用数据驱动的方式,数据通过读取excel文件来执行测试,所以这里需要封装读取excel的方法,使用xlrd来操作读取。
# operationExcel.py
import json
from common.contentsManage import filePath
import xlrd, xlwt
class OperationExcel:
# 获取shell表
def getSheet(self, index=0):
book = xlrd.open_workbook(filePath())
return book.sheet_by_index(index) #根据索引获取到sheet表
# 以列表形式读取出所有数据
def getExcelData(self, index=0):
data = []
sheet = self.getSheet(index=index)
title = sheet.row_values(0) # (0)获取第一行也就是表头
for row in range(1, sheet.nrows): # 从第二行开始获取
row_value = sheet.row_values(row)
data.append(dict(zip(title, row_value))) # 将读取出第一条用例作为一个字典存放近列表
return data
# 对excel表头进行全局变量定义
class ExcelVarles:
case_Id = "用例ID"
case_module="用例模块"
case_name="用例名称"
case_server="用例地址"
case_url="请求地址"
case_method="请求方法"
case_type="请求类型"
case_data="请求参数"
case_headers="请求头"
case_preposition="前置条件"
case_isRun = "是否执行"
case_code = "状态码"
case_result = "期望结果"
if __name__ == "__main__":
opExcel = OperationExcel()
# opExcel.getSheet()
# print(opExcel.getExcelData())
opExcel.writeExcelData(1, 7, f"test{2}")excel 文件内容如图:

封装用例
# test_api_all.py
# 参数化运用所有用例
import json
import pytest
from utils.operationExcel import OperationExcel, ExcelVarles
from base.method import ApiRequest
from common.log import logger
opExcel = OperationExcel()
apiRequest = ApiRequest()
@pytest.mark.parametrize('data', opExcel.getExcelData()) # 装饰器进行封装用例
def test_api(data, login_token=None):
if data[ExcelVarles.case_isRun] == "N" :
logger.info("跳过执行用例")
return
# 请求头作为空处理并添加token
headers = data[ExcelVarles.case_headers]
if len(str(headers).split()) == 0:
pass
elif len(str(headers).split()) >= 0:
headers = json.loads(headers) # 转换为字典
# headers['Authorization'] = login_token # 获取登录返回的token并添加到读取出来的headers里面
headers = headers
# 对请求参数做为空处理
params = data[ExcelVarles.case_data]
if len(str(params).split()) == 0:
pass
elif len(str(params).split()) == 0:
params = params
url = data[ExcelVarles.case_server] + data[ExcelVarles.case_url] + "?" + params
r = apiRequest.all_method( data[ExcelVarles.case_method] ,url, headers=headers)
logger.info(f"响应结果{r}")
responseResult = json.loads(r)
case_result_assert(data[ExcelVarles.case_code], responseResult['code'])
# 断言封装
def case_result_assert(expectedResult, actualReuls) :
'''
断言封装
:param expectedResult: 预期结果
:param actualReuls: 实际结果
:return:
'''
assert expectedResult == actualReuls # 状态码封装日志文件
# log.py
#!/usr/bin/python
# -*- coding: utf-8 -*-
import logging
import time
import os
from common.contentsManage import logDir
# BASE_PATH = os.path.dirname(os.path.dirname(os.path.realpath(__file__)))
# # 定义日志文件路径
# LOG_PATH = os.path.join(BASE_PATH, "log")
# if not os.path.exists(LOG_PATH):
# os.mkdir(LOG_PATH)
# 方法1
# 封装自己的logging
class MyLogger:
def __init__(self):
self._logName = os.path.join(logDir(), "{}.log".format(time.strftime("%Y%m%d")))
self._logger = logging.getLogger("logger")
self._logger.setLevel(logging.DEBUG)
self._formatter = logging.Formatter('[%(asctime)s][%(filename)s %(lineno)d][%(levelname)s]:%(message)s')
self._streamHandler = logging.StreamHandler()
self._fileHandler = logging.FileHandler(self._logName, mode='a', encoding="utf-8")
self._streamHandler.setFormatter(self._formatter)
self._fileHandler.setFormatter(self._formatter)
self._logger.addHandler(self._streamHandler)
self._logger.addHandler(self._fileHandler)
# 获取logger日志记录器
def get_logger(self):
return self._logger
logger = MyLogger().get_logger()封装请求方法
# method.py
import json
import requests
from common.log import logger
from utils.commonUtils import isJson
class ApiRequest(object):
# ---- 第一种请求方式封装requests库,调用可根据实际情况传参 ----
# def send_requests(self, method, url, data=None, params=None, headers=None,
# cookies=None,json=None,files=None,auth=None,timeout=None,
# proxies=None,verify=None,cert=None):
# self.res = requestes.request(method=method, url= url, headers=headers,data=data,
# params=params, cookies=cookies,json = json,files=files,
# auth=auth, timeout= timeout, proxies=proxies,verify=verify,
# cert=cert)
# return self.res
# 第二种封装方法
def get(self, url, data=None, headers=None, payload=None):
if headers is not None:
res = requests.get(url=url, data=data,headers=headers)
else:
res = requests.get(url=url, data=data)
return res
def post(self, url, data, headers, payload:dict, files=None):
if headers is not None:
res = requests.post(url=url, data=data, headers=headers)
else :
res = requests.post(url=url, data=data)
if str(res) == "<Response [200]>" :
return res.json()
else :
return res.text
def put(self,url,data,headers, payload:dict, files=None):
if headers is not None :
res = requests.put(url=url,data=data,headers=headers)
else:
res = requests.put(url=url,data=data)
return res
def delete(self,url,data,headers, payload:dict):
if headers is not None :
res = requests.delete(url=url,data=data,headers=headers)
else:
res = requests.delete(url=url,data=data)
return res
def all_method(self, method, url, data=None, headers=None, payload=None, files=None):
logger.info(f"请求方法是{method}, 请求地址{url}")
if headers == None:
headers = {}
if method.upper()=='GET':
res = self.get(url,data,headers, payload)
elif method.upper()=='POST':
res = self.post(url, data, headers, payload, files)
elif method.upper() == 'PUT':
res = self.put(url, data, headers, payload, files)
elif method.upper() == 'DELETE':
res = self.delete(url, data, headers, payload)
else :
res = f'请求{method}方式不支持,或者不正确'
return json.dumps(res, ensure_ascii=False, indent=4, sort_keys=True, separators=(',',':'))运行
# run.py
import shutil
import pytest
import os
from common.log import logger
import subprocess # 通过标准库中的subprocess包来fork一个子进程,并运行一个外部的程序
from common.contentsManage import htmlDir, resultDir
if __name__ == '__main__':
htmlPath = htmlDir()
resultPath = resultDir()
if os.path.exists(resultPath) and os.path.isdir(resultPath):
logger.info("清理上一次执行的结果")
shutil.rmtree(resultPath, True)
logger.info("开始测试")
pytest.main(["-s", "-v", "--alluredir", resultPath]) #运行输出并在resport/result目录下生成json文件
logger.info("结束测试")
# 如果是代码单独执行,需要立马看到报告,可以执行下面语句,如果配合Jenkins使用,则可以不需要执行,Jenkins自带的插件allure会操作
# logger.info("生成报告")
# subprocess.call('allure generate ' + resultPath + ' -o '+ htmlPath +' --clean', shell=True) # 读取json文件并生成html报告,--clean诺目录存在则先清楚
# logger.info("查看报告")
# subprocess.call('allure open -h 127.0.0.1 -p 9999 '+htmlPath+'', shell=True) #生成一个本地的服务并自动打开html报告依赖包安装,可以执行命令 pip3 install -r requirements.txt,来安装。
# requirements.txt pytest==7.4.3 pytest-html==4.1.1 pytest-xdist==3.5.0 pytest-ordering==0.6 pytest-rerunfailures==13.0 allure-pytest==2.13.2 xlrd==1.2.0 requests==2.31.0
至此,项目的代码框架就基本结束了。
6、安装并配置Jenkins
Jenkins的安装,看你需要在Windows还是Linux下安装,具体教程可以网络查找。
Jenkins安装allure插件:

Jenkins安装并登录后,可以创建任务。



添加构建步骤,根据你安装环境的不同,选择不同的构建。


添加构建后操作,选择 allure Report。

配置代码执行的结果地址。

运行测试后,可以在任务中查看allure生成的报告。


至此,jenkins+python+pytest+requests+allure的接口自动化测试就记录到这里,刚兴趣的可以去看看pytest的官方文档,了解更多知识。
作者:seven
- -1.00 查看剩余0%
- 【留下美好印记】赞赏支持

热门文章
最新讲堂
- 推荐阅读
- 换一换
- 金山WPS被曝“套娃式”收费——软件测试圈04-17互联网上关于金山办公软件WPS被曝“套娃式”收费的讨论持续升温,引发众多用户关注。多名用户反映在购买WPS“超级会员”后,为了获取AI功能,不得不额外购买“超级会员Pro”,而如今再次收到弹窗提示,要求升级为“大会员”以继续使用AI功能。这一连串的付费升级现象被用户称为“套娃式”收费,引发用户对WPS会员制度透明度和合理性质疑。 针对用户的投诉,WPS热线客服给出了官方回应。客服表示,目前公司尚未出台会员体系整合政策,但未来可能会对现有的会员体系进行升级,或是推出涵盖更完善会员功能的新产品,以满足用户对不同功能需求的精细化服务。此回应虽未直接回应“套娃式”收费问题,但暗示了公司正考虑对现...
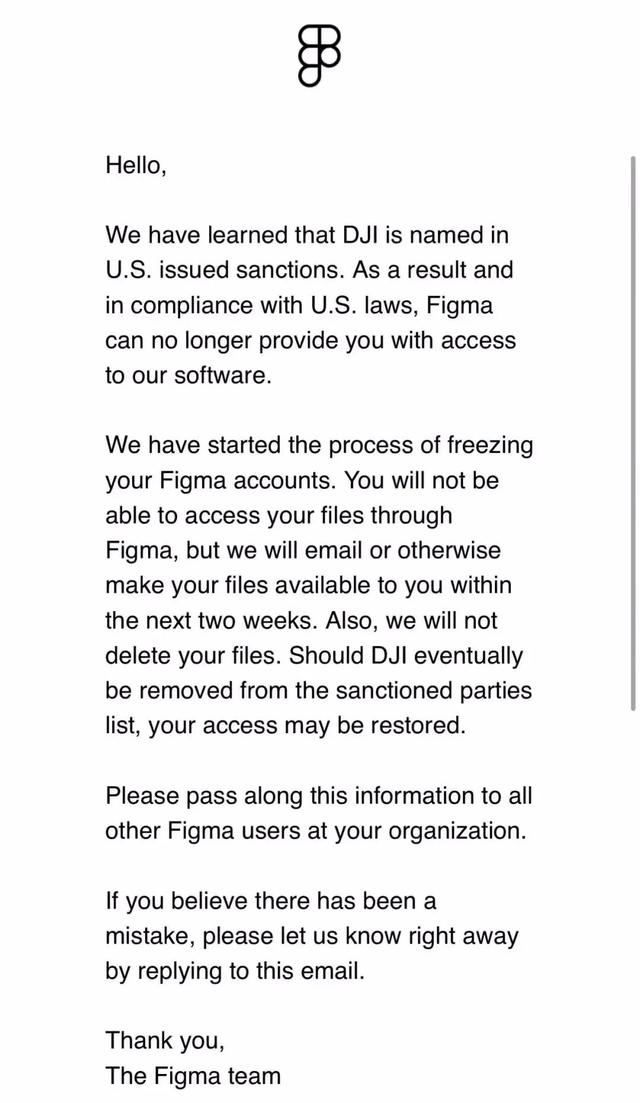
- “新冷战”蔓延到生产力工具著名 UI 设计软件 Figma 宣布制裁大疆!近日,网上流传一份 Figma 发送给大疆的内部邮件。其中写道:“我们了解到,大疆在美国制裁名单中被点名。因此根据美国法律,Figma 无法再为您提供对我们软件的访问权限,我们已经开始冻结您的 Figma 账户。我们将在未来两周内通过电子邮件或其他方式将您的文件提供给您。此外,我们不会删除您的文件。如果大疆最终从受制裁方列表中删除,您的访问权限可能会恢复。”好在,在 Figma 封号的消息传出后,国内包括蓝湖 MasterGo 等被称为“中国 Figma ”的设计工具团队宣布,可以进行 Figma 文件导入,并且支持导入...
-
- 用例评审会议流程07-29读者提问:用例评审会议有通用的流程吗,是什么样的 ?阿常回答:这个要分复杂项目和简单项目。一、复杂项目如果是复杂项目,需要走会议评审,目的是为了查漏补缺,保证用例覆盖了所有需求。1、将需要评审的用例文档共享给相关人员提前查看(主要是产品、研发、测试)。2、在项目沟通群和大家确认参加评审会的时间(给出具体的时间,让大家确认)。3、正式向相关人员(产品、设计、研发、测试)发起用例评审会议邀请。4、评审会议上由测试团队按主流程、细分模块逐一梳理测试点。5、产品及研发在测试梳理测试点的过程中,可随时提出疑问或给予补充。6、会议结束后,测试团队将更新后的测试用例同步给项目组人员查看。二、简单项...
- 开发人员为什么要写测试用例?——软件测试圈06-06作为一名开发人员,你可能会发现周围的开发并不太喜欢写测试用例,甚至有些同学根本不写测试用例,认为写测试用例完全是浪费时间,或者是测试用例只是测试的事情。 在开发过程中,往往都是呼啦啦的写完代码,然后用 Postman 或者 Httpclient 等接口工具请求下接口,看着没问题就提测,然后等测试人员反馈问题。 这大概和职业以及所处的环境又关系,有些是公司没有相关的要求,有些是注重敏捷开发(项目和自己总有一个敏捷),不过群里有些同学问测试用例的事情,而我前段时间正好在写测试用例,所以做了一些笔记,在这里和大家分享一下。 以下内容都是自己粗鄙的理解,不对的地方,请指出。 为什么要写测试...

- 3年汽车软件测试工程师的经验总结——软件测试圈04-10入行汽车电子行业已经要三年了,闲下来的时间爱总结总结,感受一下现在自己的行业水平,技术水平和发展想法。 首先,工作三年了,除了业务知识积累之外,我觉得增长更多的是沟通与做事方式的长进。经常挂在嘴边的一句话:“道理都懂,但就是不清楚怎么做。”从小学到大学,十几年甚至二十几年在学校里更多的是教会了自己如何快速高效的记忆,却并未就给自己太多思考的时间。 虽说到了大学后,时间多了,可以有很多思考的时间,但殊不知,思维差不多已经固化了,很多习惯好像在机械重复了多遍以后,就像是刻进了基因里,长进了骨子里,它让你很多个瞬间总是毫不犹豫的选择了那些个你觉得不确定的确定,所有的这些选择构成了我们现在的人...



{kind=link}
,不过群里有些同学问测试用例的事情,而我前段时间正好在写测试用例,所以做了一些笔记,在这里和大家分享一下。 以下内容都是自己粗鄙的理解,不对的地方,请指出。 为什么要写测试...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=147019&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=147019&pic=http://quan.51testing.com/ueditor/php/upload/image/20240606/1717659049716270.jpg){kind=link}
- 关于我们 联系我们 版权声明 广告服务 站长统计
- 建议使用IE 11.0以上浏览器,800×600以上分辨率,法律顾问:上海兰迪律师事务所 项棋律师
- 版权所有 上海博为峰软件技术股份有限公司 Copyright©51testing.com 2003-2024, 沪ICP备05003035号
- 投诉及意见反馈:webmaster@51testing.com; 业务联系:service@51testing.com021-64471599-8017

- 51testing软件测试圈微信