 14
14 14
14


- 想用Excel进行自动化冒烟测试?用这个就对了——软件测试圈
tablib 是 requests 库作者常年维护的一个 python 第三方库,可以操作 Excel 等多种文件格式变成一种通用数据集。
tablib 支持的主要数据格式有:
xls, 老版 office 的 Excel 文件格式;
xlsx 系列,新版 office 文件格式;
JSON
YAML
HTML
CSV
df,(pandas 的 DataFrame, 需要安装 pandas)
tablib 操作测试用例的基础使用非常简单,你只需要记住以下 2 点:
1、使用 import_set 导入 Excel 文件
with open('demo.xls', 'rb') as f:
# 接受 2 个参数,读出来的数据和读取的文件格式
data = tablib.import_set(f.read(), 'xls')
print(data)使用 DataSet 创建 Excel 表格
data = tablib.Dataset(*data_list, headers=headers,title='测试用例')
现在来进行更精确的操作:
行列数据操作
先通过加载 Excel 文件获取到数据
a = tablib.import_set(f.read(), 'xls')
a 得到的是一个列表,每个元素是每一行数据。
1、获取行
# 获取第一行第一列 print(a[0][0]) # 获取第一行的 url 列 print(a.dict[0]['url']) # 获取前 2 行 print(a[:2])
2、获取列
print(a['url'])
3、插入行
with open('demo_book.xls', 'rb+') as f:
a = tablib.import_set(f.read(), 'xls')
print(a)
# 添加行
a.append(['zhiwang', 'put', '成功'])
# 在指定行插入
a.insert(2,['zhiwang', 'put', '成功'])
with open('demo_book.xls', 'wb') as f:
f.write(a.xls)
print(a)4、插入列
# 在最后添加 a.append_col(['成功','失败', '失败'], header='actual_result') # 在指定位置添加列 a.insert_col(3,['成功','失败', '失败'], header='actual_result')
5、修改
# 修改某一行数据
a[0] = ('baidu', 'put', 'shibai', 'shibai')
# 修改某个具体的数据
a._data[0][0] = 'wobuzhidao'注意:不要在代码里直接操作 a._data, 可以封装成方法。
冒烟用例执行
在测试过程中,我们经常需要执行冒烟用例。或者给测试用例打标签,比如登录功能,成功用例,异常用例等等。tablib 通过 tags 关键字方便删选指定的测试用例来执行。
1、添加 tags
# 添加标签 a.append(['buzhi', 'put', 'c','c'], tags=['成功']) # 获取所有‘成功’的测试用例 success = a.filter(tag='成功')
2、修改 tags
# 将测试用例的标签修改成‘失败’ a._data[0].tags = ['失败'] # 获取所有‘失败’ 的测试用例 failed = a.filter(tag='失败') print(failed)
3、去除重复元素
a.remove_duplicates()
灵活的格式切换
测试数据最常用的功能是需要切换格式,比如把 Excel 格式的数据切换成 YAML , 这个在接口自动化测试框架 httprunner 中经常用到。还是用 a 来表示 DataSet 数据:
1、存储为 YAML 文件:
with open('demo.yml', 'w', encoding='utf-8') as f:
f.write(a.yaml)2、导入 YAML 文件:
with open('demo.yml', 'r') as f:
a = tablib.Dataset().load(f.read(), format='yaml')
print(a.html)效果:

651 x 193
3、导出为 HTML :
with open('demo.html', 'w', encoding='utf-8') as f:
f.write(data.html)效果:

728 x 188 879 x 227
5、导出为 json:
with open('demo.json', 'w', encoding='utf-8') as f:
f.write(data.json)效果:
[
{
"url": "baidu",
"method": "get",
"expect": "failed"
},
{
"url": "lemon",
"method": "post",
"expect": "success"
}
]其他常用方法
lpop(),lpush(row, tags=[]),lpush_col(col, header=None) 是对列的相关操作
pop(),rpop(),rpush(row, tags=[]),rpush_col(col, header=None) 是对行的相关操作
remove_duplicates() 去除重复的记录
sort(col, reverse=False) 根据列进行排序
subset(rows=None, cols=None) 返回子 Dataset
wipe() 清空 Dataset,包括表头和内容
总结
tablib 这个库非常灵活,用法非常好记,完全符合我们对 Excel 的理解。非常适用于 python 自动化测试的用例数据管理。只有一个缺点:中文资料太少。后面我会翻译一些优秀的英文文档,让更多人把这个优秀的库用起来。
作者:互联网IT二狗子
链接:https://juejin.cn/post/7010741240832458782
- 0.00 查看剩余0%
- 【留下美好印记】赞赏支持
热门文章
最新讲堂
- 推荐阅读
- 换一换
- 北京亦庄官方宣布,北京小米机器人技术有限公司正式乔迁至北京亦庄小米汽车工厂。 据介绍,目前小米机器人公司正推进仿人机器人在自有制造系统的分阶段落地。短期内小米机器人是一个专用智能机器人,应用在智能制造的某些场景中,未来将向更多场景拓展。 小米集团高级副总裁、手机部总裁曾学忠表示:“未来扎根北京亦庄这片创新宝地,我们希望能与行业伙伴携手合作,持续推动机器人产业的发展,一个由智能机器、仿人机器人和人类专家共同组成的‘人机一体化时代’一定会加速到来。” 小米机器人公司于 2023 年 4 月在北京亦庄注册成立,成为小米集团专注于仿生机器人技术创新与产品研发、产业化的唯一主体。目前,小米已发...

-
- 近日有多名网友发现,DOTA2 周边商城中部分名字带有“英雄”的商品变成了“英雌”,引发许多玩家不满。 今日下午,DOTA2 官方就此发布了“关于 DOTA2 周边商城运营事故的处理公告”进行回应。作者:佚名原文链接:新浪科技_新浪网(sina.com.cn)

-
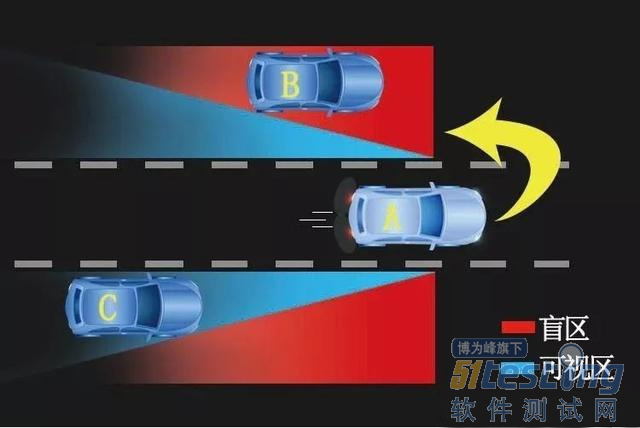
- ADAS概述 ADAS翻译成中文为“高级驾驶辅助系统”,全称Advanced Driving Assisstance Systems,是在汽车紧急情况下提前做出主动判断和预防,以达到预防和辅助的作用。 注意Systems是复数,因此该系统只是单一个系统,且是由许多子功能系统组成。 可以将这些子功能划分为行车和泊车两大类。行车部分常见的有AEB-自动紧急制动、ACC-自适应巡航、FCW-前向碰撞预警、LCA-变道辅助、LKA-车道保持、TLA-交通信号灯提醒、TSR-交通标志识别、ICC-智能巡航控制等。 泊车部分有APA-自动泊车、AVP-代客泊车等,而这些子系统就是发展全自动驾驶...
-
- 如何模拟后台API调用场景,很细!08-05简介在开发前后台分离项目并且通过不同团队来实现的时候,如何将后台设计的 API 准确的传达到前台,是一个非常重要的工作。为了简化这个过程,开源社区做了很多努力,比如 protobuf技术,swagger 的诞生, 以及后面 openapi 的演化,都在试图解决 API 描述和文档的问题。这些标准某些程度上大大简化了 API 文档的撰写和维护,但是API设计往往比较复杂,所以另外还有一些痛点没有解决:若干 API 的调用顺序是有要求的若干 API 的输入和输出是相互关联的若干 API 需要重复调用达到不同的效果举了具体的例子, 某后端小伙伴X和前端小伙伴Y合作开发一款游戏, X 设计好 API ...

- Jmeter之接口测试流程详解——软件按测试圈12-19一、jmeter简介Jmeter是由Apache公司开发的java开源项目,所以想要使用它必须基于java环境才可以;Jmeter采用多线程,允许通过多个线程并发取样或通过独立的线程对不同的功能同时取样。二、jmeter安装首先需要安装jdk(最好是最新版的);其次去官网下载最新的jmeter版本;然后配置jmeter的环境变量;最后双击jmeter.bat或者在“命令提示符”输入jmeter,运行jmeter。具体安装步骤请自行网上查看三、设置jmeter的中文界面进入jmeter的bin目录,找到“jmeter.properties”文件,打开文件搜索“language”,将“#langu...




{kind=link}
&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=146412&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=146412&pic=http://quan.51testing.com/ueditor/php/upload/image/20230811/1691722496362977.jpg){kind=link}
{kind=link}
{kind=link}
;其次去官网下载最新的jmeter版本;然后配置jmeter的环境变量;最后双击jmeter.bat或者在“命令提示符”输入jmeter,运行jmeter。具体安装步骤请自行网上查看三、设置jmeter的中文界面进入jmeter的bin目录,找到“jmeter.properties”文件,打开文件搜索“language”,将“#langu...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=145704&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=145704&pic=http://quan.51testing.com/ueditor/php/upload/image/20221219/1671432236424348.png){kind=link}
- 关于我们 联系我们 版权声明 广告服务 站长统计
- 建议使用IE 11.0以上浏览器,800×600以上分辨率,法律顾问:上海兰迪律师事务所 项棋律师
- 版权所有 上海博为峰软件技术股份有限公司 Copyright©51testing.com 2003-2024, 沪ICP备05003035号
- 投诉及意见反馈:webmaster@51testing.com; 业务联系:service@51testing.com021-64471599-8017

- 51testing软件测试圈微信