 13
13 13
13


- Selenium WebDriver中执行JS语句那些事——软件测试圈
Selenium WebDriver让我们轻松实现与浏览器的交互,通过页面元素定位,执行对应的元素操作及断言设置,这一系列的步骤开启了Web自动化脚本的创建。相信大家对于元素定位及其执行并不陌生,今天我们就来聊一聊Selenium WebDriver中另一大特色JS语句的执行,即JavaScriptExecutor。
1.什么是JavaScriptExecutor
JavaScriptExecutor 是Selenium WebDriver提供的一个接口,它提供了一种通过WebDriver直接执行JavaScript的方式,在选定窗口或当前页面上运行 JavaScript 的方法。如果你用的是Java语言,那么可以通过导入“org.openqa.selenium.JavascriptExecutor” 直接使用它;如果你用的是Python, 那就更方便了,直接“from selenium import webdriver”即可。
2.为什么在 Selenium 中使用 JavaScriptExecutor
通常情况下我们会使用各种Web 定位器来定位页面元素,例如 id、name、XPath 等。但是如果这些定位器无法按预期工作,定位不到对应的元素,这时我们就可以通过JavaScriptExecutor来尝试解决这类问题。
同理,当我们对页面上某个元素执行点击操作时,最常见的就是driver.findElement(By.id(“button”)).click(); 但是click() 方法并非适用于所有 Web 浏览器,有时同一个 Web 控件在不同浏览器上的行为也有可能不同。为了应对这类情况,JavaScriptExecutor同样是一个最优的解决方案,因为JS语句本身就是?Web 脚本语言,用来控制网页行为。
3.Selenium中使用JavaScriptExecutor场景介绍
(1)点击按钮
方法一:
Python版
driver.execute_script("document.getElementById('XXX').click()")Java版
js.executeScript("document.getElementById('XXX').click();");方法二:
Python版
driver.execute_script("arguments[0].click()",button)Java版
js.executeScript("arguments[0].click();", button);方法二中的arguments指的是execute_script()方法中js代码后面的所有参数,arguments[0]表示第一个参数,argument[1]表示第二个参数。
(2)在不使用 sendKeys() 方法的情况下在文本框中键入文本
Python版
driver.execute_script("document.getElementById('XXX').value='someValue' ")Java版
js.executeScript("document.getElementById('XXX').value='someValue';");(3)通过值传递“真”|“假”来处理复选框
Python版
driver.execute_script("document.getElementById('XXX').checked=false")Java版
js.executeScript("document.getElementById('enter element id').checked=false;");(4)在Selenium WebDriver中生成Alert弹框
Python版
driver.execute_script("alert('注册成功');")Java版
js.executeScript("alert('注册成功');");(5)使用Javascript刷新浏览器窗口
Python版
driver.execute_script("history.go(0)")Java版
js.executeScript("history.go(0)");(6)获取网页标题
Python版
driver.execute_script("return document.title")Java版
js.executeScript("return document.title;").toString();(7)获取当前域名
Python版
driver.execute_script("return document.domain")Java版
js.executeScript("return document.domain;").toString();(8)实现页面滚动效果
Python版
# 通过JS进行页面滚动至末尾
driver.execute_script("window.scrollBy(0,document.body.scrollHeight)")
# 通过JS进行页面回滚至开始
driver.execute_script("window.scrollBy(0,-document.body.scrollHeight)")Java版
# 通过JS进行页面滚动至末尾 js.executeScript(“window.scrollBy(0,document.body.scrollHeight)”); # 通过JS进行页面回滚至开始 js.executeScript(“window.scrollBy(0,-document.body.scrollHeight)”);
(9)获取整个页面的内容
Python版
driver.execute_script(return document.documentElement.innerText)
Java版
js.executeScript(" return document.documentElement.innerText;").toString();4.Demo实战演练
我们以“大众点评”,通过Selenium Python + JavaScriptExecutor进行多版本迭代实战演练,获取首页网红餐厅信息。
测试场景1
不通过JavaScriptExecutor,使用常规元素定位及操作实现;
(1)通过Chrome浏览器,打开“大众点评”主页
(2)定位搜索框,搜索“网红餐厅”
(3)获取首页搜索结果中的全部餐厅名称
(4)获取获取首页“有团购”的餐厅名称
(5)获取获取首页“可订座”的餐厅名称
(6)关闭浏览器

【测试脚本实现】
(1)相关库的导入;

(2)初始化Chrome驱动,开启大众点评首页,且窗口最大化;

(3)通过ID定位搜索框,搜索“网红餐厅”;

(4)这时由于搜索结果显示页面属于新开启的页面,我们需要切换到当前页面窗口;


(5)获取首页搜索结果中的所有“网红餐厅”名称;

通过观察发现,首页中显示的餐厅共有15个,并且餐厅名称的XPath都有固定的规则,仅通过li的下标值的递增:
第一个餐厅名称的XPath:
//*[@id="shop-all-list"]/ul/li[1]/div[2]/div[1]/a/h4
最后一个餐厅名称的XPath:
//*[@id="shop-all-list"]/ul/li[15]/div[2]/div[1]/a/h4
所以通过range(1,16)循环获取当前页面上15个餐厅的名称:

(6)获取获取首页前5个“有团购”的餐厅名称;


(7)获取获取首页前5个“可订座”的餐厅名称;


(8)关闭退出。

【运行结果】


测试场景2
通过JavaScriptExecutor实现上述场景,基于场景1,本场景中还增加演示通过JS获取页面标题,当前域名,执行页面滚动操作,实现Alert弹框操作效果。
【测试脚本实现】
(1)相关库的导入;

(2)初始化Chrome驱动,开启大众点评首页,且窗口最大化;

(3)通过JS在文本框中输入“网红餐厅”,通过JS执行搜索;

(4)同场景一,需要切换到当前页面窗口(结果展示窗口);

(5)通过执行JS,进行页面滚动操作,查看当前页面中的餐厅信息;

(6)获取首页搜索结果中的所有“网红餐厅”名称;

我们直接从页面获取餐厅名称JS Path,通过观察发现,不难发现首页餐厅名称的JS Path也是有规律的,仅通过li:nth-child的下标值的递增:
第一个餐厅名称的JS Path:
document.querySelector("#shop-all-list > ul > li:nth-child(1) > div.txt > div.tit > a > h4")最后一个餐厅名称的JS Path:
document.querySelector("#shop-all-list > ul > li:nth-child(15) > div.txt > div.tit > a > h4")在定位到元素后,我们需要获取该元素的文本信息,通过JS语句获取餐厅名称元素的文本信息方式如下:
return document.querySelector('#shop-all-list > ul > li:nth-child(1) > div.txt > div.tit > a> h4').innerText由于querySelector()中的字符串内容比较长,建议将上面的JS命令进行拆分:
style = "#shop-all-list > ul > li:nth-child(1) > div.txt > div.tit > a> h4"
js_style = "return document.querySelector(" + "'" + style + "'" + ").innerText"下面我们同样结合range(1,16)循环获取当前页面上所有餐厅的名称:

(7)获取获取首页前5个“有团购”的餐厅名称,同理,我们通过定位“有团购”勾选框,获取其JS Path;

document.querySelector
("body > div.section.Fix.J-shop-search >
div.content-wrap > div.shop-wrap > div.content > div.filter-box.J_filter_box >
div.filt-classify > a:nth-child(1) > i.icon-check")获取前5个“有团购”餐厅名称代码如下:

(8)获取获取首页前5个“可订座”的餐厅名称,同理,我们通过定位“可订座”勾选框,获取其JS Path;

document.querySelector
("body > div.section.Fix.J-shop-search >
div.content-wrap > div.shop-wrap > div.content > div.filter-box.J_filter_box >
div.filt-classify > a:nth-child(2) > i")获取前5个“可订座”餐厅名称代码如下:

(9)通过JS获取当前页面标题;

(10)通过JS获取当前域名;

(11)通过JS以弹框形式显示“查询成功”消息;

(12)关闭退出。

【运行结果】


测试场景3(优化)
从场景2中可以看出,有三次都在获取当前页面中的餐厅名称,且获取名称所用到的JS代码非常相似,可见代码存在冗余情况。为了后期能够有效维护代码,我们可以将获取餐厅名称的脚步单独拿出来,作为一个函数,每次需要的时候直接调用即可。
对需要重复使用的方法进行函数封装:

完整代码如下:



5.总结
JavaScriptExecutor 让我们能够通过 WebDriver在网页上执行 JavaScript 代码,在传统定位方式失效或者某些浏览器下元素执行方式失效的情况下,JavaScriptExecutor 不失为一个最优的备选方案;在同等情况下,它还能使自动化脚本更高效地执行。
以上为大家分享了如何在 Selenium WebDriver中使用 JavascriptExecutor,通过对JavascriptExecutor 常用方法的介绍,并结合具体场景演示了JS在Selenium WebDriver中的实际应用,希望能够给大家的测试工作带来帮助,感兴趣的读者不妨一试。
作者:罗狮小钉
- 0.00 查看剩余0%
- 【留下美好印记】赞赏支持

热门文章
最新讲堂
- 推荐阅读
- 换一换
- 今年,Google将提前两个月,于 8 月 13 日举行年度硬件发布会。届时,除了Pixel 9 系列手机,Pixel Watch 3也有望亮相。Pixel Watch 将首次推出两种尺寸--这已经得到了 FCC 的确认。今天,一则新的消息透露了更多细节,据称该消息来自Google内部。据说,Pixel Watch 3 将使用骁龙 W5 SoC,并搭配一个定制的协处理器。 41 毫米的 Watch 3 配备了 310 毫安时电池,而 45 毫米的型号将配备 420 毫安时电池,较小的 Watch 3 显示屏尺寸为 32x32 毫米(比Pixel Watch 2 的 30x30 毫米大),...

-
- 苹果在一份支持文件中宣布,它将在2023年7月26日下线"我的照片流"。这项服务已经提供了十多年,允许用户通过互联网在苹果设备上同步他们的照片。这项图片同步服务最初被称为"照片流",是在2011年WWDC期间宣布的。它可以自动从iPhone或iPad上传多达1000张最近点击的照片到iCloud。 上传的媒体在云端停留长达30天,并自动下载到使用同一苹果ID的其他设备上,包括Mac和WindowsPC。同样,当年在Mac上导入iPhoto应用的新图片也会被上传到云端,并在不同设备间同步。 最终,在上传所有照片、视频以及对媒体进行编辑的iCloud...

-
- 苹果和亚马逊在 2018 年达成了协议,苹果终于建立了亚马逊官方店面,为此,两家公司再次面临审查。Insider 今天的一篇报道深入探讨了这一协议的细节,一位消息人士称,苹果正从亚马逊那里获得"大量优惠待遇"。 在过去的几年里,苹果和亚马逊之间的交易一直面临着监管部门的强烈反对。这两家公司还在与一起价格垄断诉讼作斗争,该诉讼指控它们合谋提高 iPhone 和 iPad 的价格。 正如今天的报道所详述的,苹果和亚马逊之间的协议包括一项例外条款,即减少出现在苹果设备产品页面上的广告和推荐数量。亚马逊的产品页面一般都充斥着广告、赞助商结果和推荐,而苹果的产品页面只在页面最...
-
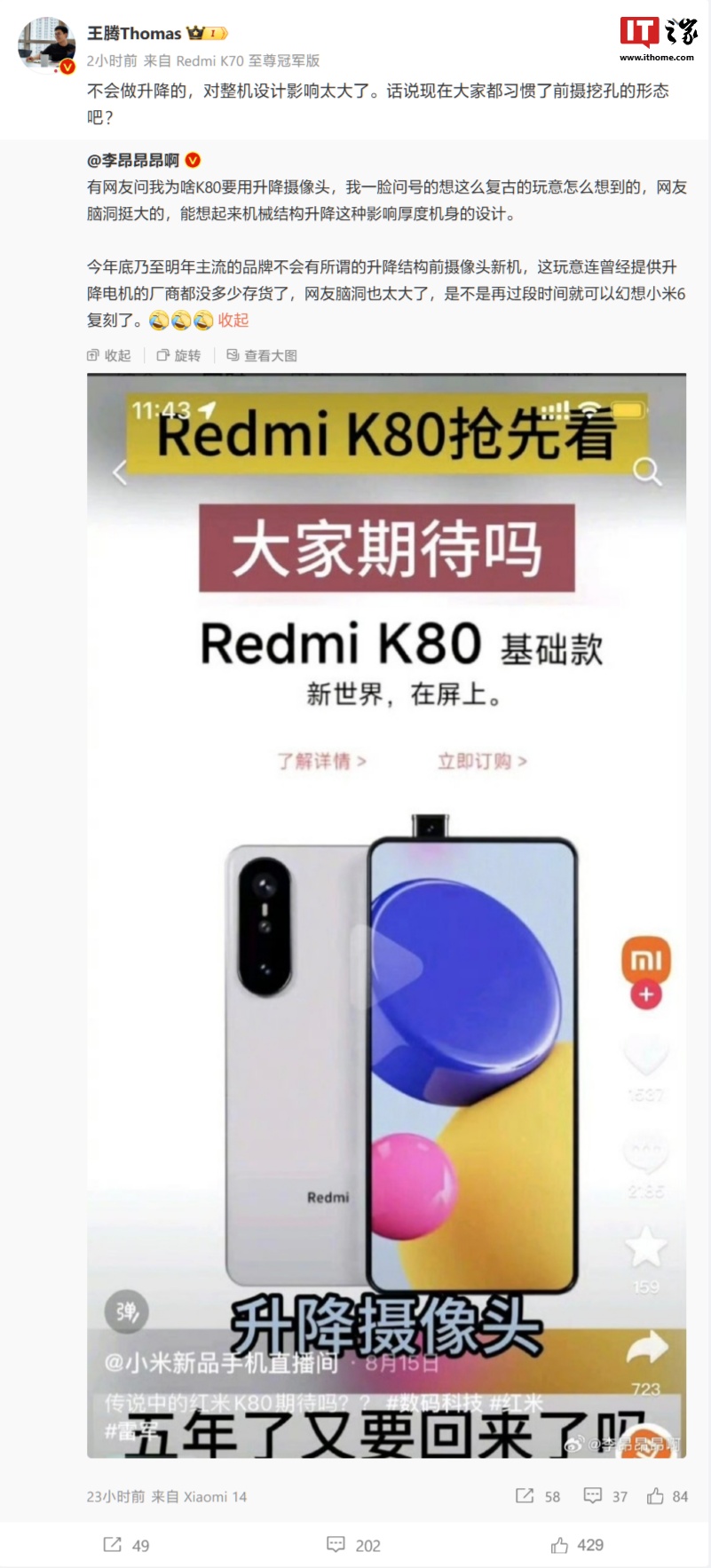
- 近期有网传消息声称,小米 Redmi K80 系列手机将采用“升降摄像头”设计,并放出了一张“预告图”。小米中国区市场部副总经理、Redmi 品牌总经理王腾今天在微博上否认了相关传闻:“不会做升降的,对整机设计影响太大了。话说现在大家都习惯了前摄挖孔的形态吧?” 王腾转发的微博中,博主“李昂昂昂啊”也对这一传闻提出了质疑。“…… 网友脑洞挺大的,能想起来机械结构升降这种影响厚度机身的设计。今年底乃至明年主流的品牌不会有所谓的升降结构前摄像头新机,这玩意连曾经提供升降电机的厂商都没多少存货了,网友脑洞也太大了,是不是再过段时间就可以幻想小米 6 复刻了。” IT之家注:2019 年至 2...
-
- 行为驱动模型-Behave12-04行为驱动开发英文名为Behave Driven Development,简称BDD,是一种敏捷开发方法,主要是从用户的需求出发强调系统行为。将此模型借鉴到自动化测试中称其为行为驱动测试模型,它是一种通过使用自然描述语言确定自动化测试脚本的模型。也就是说,用例的写法基本和功能测试用例的写法类似,具有良好协作的益处。这种测试模型使每个人都可以参与到行为开发中,而不仅仅是程序员。每个测试场景都是一个独立的行为,以避免重复,并且已有的行为可以重复使用。 目前在Python中最流行的 BDD 框架是...


,...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=147089&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=147089&pic=http://quan.51testing.com/ueditor/php/upload/image/20240711/1720664003103052.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- 关于我们 联系我们 版权声明 广告服务 站长统计
- 建议使用IE 11.0以上浏览器,800×600以上分辨率,法律顾问:上海兰迪律师事务所 项棋律师
- 版权所有 上海博为峰软件技术股份有限公司 Copyright©51testing.com 2003-2024, 沪ICP备05003035号
- 投诉及意见反馈:webmaster@51testing.com; 业务联系:service@51testing.com021-64471599-8017

- 51testing软件测试圈微信