 2
2 5
5
分享


- 【原创】使用 Python 实现文件递归遍历的 3 种方法
今天有个脚本需要遍历获取某指定文件夹下面的所有文件,我记得很早前也实现过文件遍历和目录遍历的功能,于是找来看一看,嘿,不看不知道,看了吓一跳,原来之前我竟然用了这么搓的实现。
先发出来看看:
def getallfiles(dir):
"""遍历获取指定文件夹下面所有文件"""
if os.path.isdir(dir):
filelist = os.listdir(dir)
for ret in filelist:
filename = dir + "\\" + ret
if os.path.isfile(filename):
print filename
def getalldirfiles(dir, basedir):
"""遍历获取所有子文件夹下面所有文件"""
if os.path.isdir(dir):
getallfiles(dir)
dirlist = os.listdir(dir)
for dirret in dirlist:
fullname = dir + "\\" + dirret
if os.path.isdir(fullname):
getalldirfiles(fullname, basedir)
我是用了 2 个函数,并且每个函数都用了一次 listdir,只是一次用来过滤文件,一次用来过滤文件夹,如果只是从功能实现上看,一点问题没有,但是这…太不优雅了吧。
开始着手优化,方案一:
def getallfiles(dir):
"""使用listdir循环遍历"""
if not os.path.isdir(dir):
print dir
return
dirlist = os.listdir(dir)
for dirret in dirlist:
fullname = dir + "\\" + dirret
if os.path.isdir(fullname):
getallfiles(fullname)
else:
print fullname
从上图可以看到,我把两个函数合并成了一个,只调用了一次 listdir,把文件和文件夹用 if~else~ 进行了分支处理,当然,自我调用的循环还是存在。
有木有更好的方式呢?网上一搜一大把,原来有一个现成的 os.walk() 函数可以用来处理文件(夹)的遍历,这样优化下就更简单了。
方案二:
def getallfilesofwalk(dir):
"""使用listdir循环遍历"""
if not os.path.isdir(dir):
print dir
return
dirlist = os.walk(dir)
for root, dirs, files in dirlist:
for file in files:
print os.path.join(root, file)
只是从代码实现上看,方案二是最优雅简洁的了,但是再翻看 os.walk() 实现的源码就会发现,其实它内部还是调用的 listdir 完成具体的功能实现,只是它对输出结果做了下额外的处理而已。
附上os.walk()的源码:
from os.path import join, isdir, islink
# We may not have read permission for top, in which case we can't
# get a list of the files the directory contains. os.path.walk
# always suppressed the exception then, rather than blow up for a
# minor reason when (say) a thousand readable directories are still
# left to visit. That logic is copied here.
try:
# Note that listdir and error are globals in this module due
# to earlier import-*.
names = listdir(top)
except error, err:
if onerror is not None:
onerror(err)
return
dirs, nondirs = [], []
for name in names:
if isdir(join(top, name)):
dirs.append(name)
else:
nondirs.append(name)
if topdown:
yield top, dirs, nondirs
for name in dirs:
path = join(top, name)
if followlinks or not islink(path):
for x in walk(path, topdown, onerror, followlinks):
yield x
if not topdown:
yield top, dirs, nondirs
至于 listdir 和 walk 在输出时的不同点,主要就是 listdir 默认是按照文件和文件夹存放的字母顺序进行输出,而 walk 则是先输出顶级文件夹,然后是顶级文件,再输出第二级文件夹,以及第二级文件,以此类推,具体大家可以把上面脚本拷贝后自行验证。
以上,如果觉得有用,请帮忙转发分享,不甚感激。
本文原创发布于公众号「sylan215」,十年测试老兵的原创干货,关注我,涨姿势!
- 0.00 查看剩余0%
- 【留下美好印记】赞赏支持
登录 后发表评论

sylan215公众号「sylan215」,关注送电子书
+ 关注
热门文章
最新讲堂
温馨提示
- 推荐阅读
- 换一换
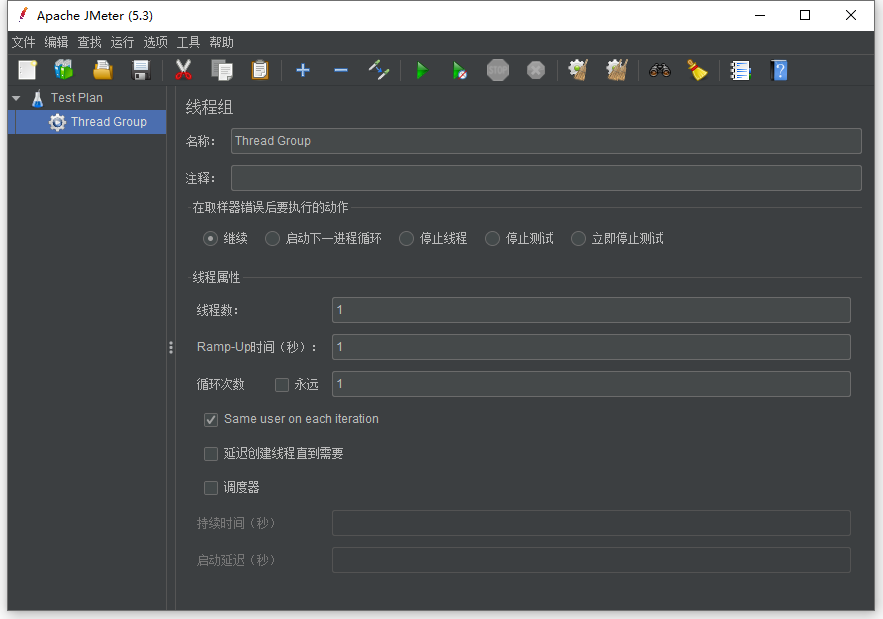
- Jmeter线程组配置08-01使用JMeter做性能测试模拟多少用户发请求本质上依靠的就是线程组元件,线程组会告诉JMeter你想要模拟的用户数量,用户发送请求的频率和发送的数量。一、线程组配置字段说明以中文为例,字段含义如下:【名称】:线程组的名称。【注释】:对于线程组的描述相关注释,不是必填项。【在取样器错误后要执行的动作】:取样器发生错误要执行哪个动作,包含继续、启动下一进程循环、停止线程、停止测试、立即停止测试五个动作。这五个动作的含义如下:继续:取样器发生错误,忽略错误继续执行,默认选项启动下一进程循环:取样器发生错误,忽略错误并停止当前线程循环,执行下一个循环停止线程:当前线程运行完毕后,停止所有线程停止测试:...
- 渗透测试那些事之API接口渗透测试研究11-27摘要本文旨在解析并梳理目前API接口渗透测试相关漏洞和测试方法,列出API接口在使用中可能出现的漏洞,针对不同的漏洞采用不同测试方法,提出使用方面的建议。1.引言接口渗透测试是通过用渗透测试的方法测试系统组件间接口的一种测试。接口渗透测试主要用于检测外部系统与系统之间以及内部各个子系统之间的交互点。测试的重点是要检查数据的交换,传递和控制管理过程,以及系统间的相互逻辑依赖关系等。2.API接口介绍2.1.RPC(远程过程调用)远程过程调用(英语:Remote Procedure Call,缩写为 RPC)是一个计算机通信协议。该协议允许运行于一台计算机的程序调用另一台计算机的子程序,而程序员无...
- 苹果公司目前的 iPhone SE 3 采用的是近十年前首次推出的设计,该公司似乎正计划用现代的设计来取代它。 此前有报道称,iPhone SE 4 将采用与 iPhone 15 类似的设计,这意味着它将获得更小的刘海和更大的 OLED 显示屏,而不是 LCD。 从一张新的 iPhone SE 4 手机壳图片中可以看出,该公司将保留部分硬件变化,如动作按钮。 从 iPhone 15 Pro 及更新机型开始,苹果在所有 iPhone 机型上都取消了静音开关,据说 iPhone SE 4 也有同样的改变。 不过,根据一张新的 iPhone SE 4 手机壳图片,可以看出该设备可能会配备静音开...
-
- 小论游戏测试及互联网测试更好的提高质量!09-181、开始测试1年半左右,一直在做的是游戏测试。现在对于黑盒的游戏测试感觉到迷茫,对于做游戏的黑盒测试来说,技术成长性在哪里?哪些知识能更好的帮助自己的工作?是这样的,测试入门的门槛相对其他技术工种来说不高,但可以提升空间是很大的。黑盒也好,白盒也好,其实所描绘的是测试立场和角度,最早国外上世纪提出的 是基于开发者了解内部结构去寻找问题(谓之白盒),黑盒是使用者的角度,不需要了解内部结构去验收(谓之黑盒),如果以测试策略来描绘的话,这个就是PDCA,P前面的target,这个阶段的测试目标是什么如你所言,接触服务端测试接触到了lr的基础(压力测试及负载测试),服务端相关测试还有对应的window...
- 想查看小程序的请求,使用wireshark捣鼓了半天还是无法解析微信小程序的HTTPS协议,于是使用Fiddler试试。Tools --> Options重启 Fiddler点击右边的 Filter 选项卡。然后点击 Actions --> Run Filterset Now接着点开PC微信小程序,就能看到请求列表。双击右边某一行即可展开详细信息显示请求的时间在左侧的列表区域头部任意栏上鼠标右键,选择 Customize Columns,然后Add,就会多出一列时间。需要注意的是,Fiddler 如果异常退出的话,会导致浏...

-


{kind=link}
远程过程调用(英语:Remote Procedure Call,缩写为 RPC)是一个计算机通信协议。该协议允许运行于一台计算机的程序调用另一台计算机的子程序,而程序员无...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=342&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=342&pic=http://quan.51testing.com/ueditor/php/upload/image/20191127/1574822733814808.png){kind=link}
{kind=link}
温馨提示
打开微信 扫一扫
温馨提示
设置支付密码
- 关于我们 联系我们 版权声明 广告服务 站长统计
- 建议使用IE 11.0以上浏览器,800×600以上分辨率,法律顾问:上海兰迪律师事务所 项棋律师
- 版权所有 上海博为峰软件技术股份有限公司 Copyright©51testing.com 2003-2024, 沪ICP备05003035号
- 投诉及意见反馈:webmaster@51testing.com; 业务联系:service@51testing.com021-64471599-8017

- 51testing软件测试圈微信