 3
3 3
3


- 想要实时搜索,最重要的是同步数据库
目前大部分mysql和elasticsearch同步机制使用的插件实现的,常用的插件包为:logstash-input-jdbc,go-mysql-elasticsearch, elasticsearch-jdbc、canal。
插件优缺点对比
1. logstash-input-jdbc
logstash官方插件,集成在logstash中,下载logstash即可,通过配置文件实现mysql与elasticsearch数据同步
优点
·能实现mysql数据全量和增量的数据同步,且能实现定时同步。
·版本更新迭代快,相对稳定。
·作为ES固有插件logstash一部分,易用。
缺点
·不能实现同步删除操作,MySQL数据删除后Elasticsearch中数据仍存在。
·同步最短时间差为一分钟,一分钟数据同步一次,无法做到实时同步。
2、go-mysql-elasticsearch
go-mysql-elasticsearch 是国内作者开发的一款插件
优点
·能实现mysql数据增加,删除,修改操作的实时数据同步
缺点
·无法实现数据全量同步Elasticsearch
·仍处理开发、相对不稳定阶段
3、elasticsearch-jdbc
目前最新的版本是2.3.4,支持的ElasticSearch的版本为2.3.4, 未实践
优点
·能实现mysql数据全量和增量的数据同步.
缺点
·目前最新的版本是2.3.4,支持的ElasticSearch的版本为2.3.4
·不能实现同步删除操作,MySQL数据删除后Elasticsearch中数据仍存在.
mysql安装
安装依赖
yum search libaio # 检索相关信息
yum install libaio # 安装依赖包
mysql是否安装
yum list installed | grep mysql
mysql卸载
yum -y remove mysql-libs.x86_64
mysql yum下载
wget -i -c http://dev.mysql.com/get/mysql57-community-release-el7-10.noarch.rpm
安装 MySQL
yum -y install mysql57-community-release-el7-10.noarch.rpm
yum -y install mysql-community-server
查看mysql安装位置
whereis mysql
启动mysql
systemctl start mysqld.service
systemctl status mysqld.service
关闭mysql
systemctl stop mysqld
查看密码
grep 'temporary password' /var/log/mysqld.log
mysql修改密码远程连接
SET PASSWORD = PASSWORD('/20as3SElksds0ew98');
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY '/20as3SElksds0ew98' WITH GRANT OPTION;
logstash-input-jdbc实现mysql数据库与elasticsearch同步
logstash5.x之后,集成了logstash-input-jdbc插件。安装logstash后通过命令安装logstash-input-jdbc插件
./logstash-plugin install logstash-input-jdbc
配置
在logstash/config文件夹下新建jdbc.conf,配置内容如下:
# 输入部分
input {
stdin {}
jdbc {
# mysql数据库驱动
jdbc_driver_library => "../config/mysql-connector-java-5.1.30.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
# mysql数据库链接,数据库名
jdbc_connection_string => "jdbc:mysql://localhost:3306/cmr"
# mysql数据库用户名,密码
jdbc_user => "root"
jdbc_password => "12345678"
# 设置监听间隔 各字段含义(分、时、天、月、年),全部为*默认含义为每分钟更新一次
schedule => "* * * * *"
# 分页
jdbc_paging_enabled => "true"
# 分页大小
jdbc_page_size => "50000"
# sql语句执行文件,也可直接使用 statement => 'select * from t_school_archives_fold create_time >=
:sql_last_value order by create_time limit 200000'
statement_filepath => "/config/jdbc.sql"
# elasticsearch索引类型名
type => "t_employee"
}
}
# 过滤部分(不是必须项)
filter {
json {
source => "message"
remove_field => ["message"]
}
}
# 输出部分
output {
elasticsearch {
# elasticsearch索引名
index => "octopus"
# 使用input中的type作为elasticsearch索引下的类型名
document_type => "%{type}" # <- use the type from each input
# elasticsearch的ip和端口号
hosts => "localhost:9200"
# 同步mysql中数据id作为elasticsearch中文档id
document_id => "%{id}"
}
stdout {
codec => json_lines
}
}
# 注: 使用时请去掉此文件中的注释,不然会报错在config 目录下新建jdbc.sql文件
select * from t_employee
运行
cd logstash-6.4.2 # 检查配置文件语法是否正确 bin/logstash -f config/jdbc.conf --config.test_and_exit # 启动 bin/logstash -f config/jdbc.conf --config.reload.automatic --config.reload.automatic: 会自动重新加载配置文件内容 在kibana中创建索引后查看同步数据 PUT octopus GET octopus/_search
Canal实现mysql数据库与elasticsearch同步
mysql
修改/etc/my.cnf
log-bin=mysql-bin binlog-format=ROW server-id=1
创建授权
create user canal identified by 'Canal@2020!'; #创建canal账户 grant select,replication slave,replication client on *.* to 'canal'@'%'; #授权canal账户查询和复制权限 flush privileges; #刷新授权
查看binlog是否正确启动
show variables like 'binlog_format%';
创建需要同步的数据库
create database canal_testdb character set utf8; CREATE TABLE canal_table ( #创建canal_table表,字段为 id age name address id int(11) NOT NULL, age int(11) NOT NULL, name varchar(200) NOT NULL, address varchar(1000) DEFAULT NULL, PRIMARY KEY (id) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; INSERT INTO canal_testdb.canal_table(id, age, name, address) VALUES (1, 88, '小明', '测试');
Elasticsearch参考第一节
部署Canal-deployer服务端
下载并解压
# 没有的话新建 cd /usr/local/canal/canal-deployer/ wget https://github.com/alibaba/canal/releases/download/canal-1.1.5-alpha-1/canal.deployer-1.1.5-SNAPSHOT.tar.gz tar xf canal.deployer-1.1.5-SNAPSHOT.tar.gz
修改配置文件 instance.properties
vim /usr/local/canal-deployer/conf/example/instance.properties ################################################# ## mysql serverId , v1.0.26+ will autoGen canal.instance.mysql.slaveId=3 # enable gtid use true/false canal.instance.gtidon=false # position info canal.instance.master.address=127.0.0.1:3306 canal.instance.master.journal.name= canal.instance.master.position= canal.instance.master.timestamp= canal.instance.master.gtid= # rds oss binlog canal.instance.rds.accesskey= canal.instance.rds.secretkey= canal.instance.rds.instanceId= # table meta tsdb info canal.instance.tsdb.enable=true #canal.instance.tsdb.url=jdbc:mysql://127.0.0.1:3306/canal_testdb #canal.instance.tsdb.dbUsername=canal #canal.instance.tsdb.dbPassword=canal #canal.instance.standby.address = #canal.instance.standby.journal.name = #canal.instance.standby.position = #canal.instance.standby.timestamp = #canal.instance.standby.gtid= # username/password canal.instance.dbUsername=canal canal.instance.dbPassword=Canal@2020! canal.instance.connectionCharset = UTF-8 # enable druid Decrypt database password canal.instance.enableDruid=false #canal.instance.pwdPublicKey=MFwwDQYJKoZIhvcNAQEBBQADSwAwSAJBALK4BUxdDltRRE5/zXpVEVPUgunvscYFtEip3pmLlhrWpacX7y7GCMo2/JM6LeHmiiNdH1FWgGCpUfircSwlWKUCAwEAAQ== # table regex canal.instance.filter.regex=.*\\..* # table black regex canal.instance.filter.black.regex= # table field filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2) #canal.instance.filter.field=test1.t_product:id/subject/keywords,test2.t_company:id/name/contact/ch # table field black filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2) #canal.instance.filter.black.field=test1.t_product:subject/product_image,test2.t_company:id/name/contact/ch # mq config canal.mq.topic=example # dynamic topic route by schema or table regex #canal.mq.dynamicTopic=mytest1.user,mytest2\\..*,.*\\..* canal.mq.partition=0 # hash partition config #canal.mq.partitionsNum=3 #canal.mq.partitionHash=test.table:id^name,.*\\..* #################################################
启动canal-deployer
因为canal-depaloyer由java开发,所以需要jdk环境,jdk版本需要大于1.5
yum install java-1.8.0-openjdk.x86_64 java-1.8.0-openjdk-devel.x86_64 -y
/usr/local/canal/canal-deployer/bin/startup.sh
查看日志及端口
tail -f /usr/local/canal/logs/example/example.log
canal-deployer默认监听三个端口,11110、11111、11112
11110:为admin管理端口
11111:为canal deployer 服务器占用的端口
11112:为指标下拉端口
部署Canal-adapter客户端
下载并解压
cd /usr/local/canal/canal-adapter/ wget https://github.com/alibaba/canal/releases/download/canal-1.1.5-alpha-1/canal.adapter-1.1.5-SNAPSHOT.tar.gz tar xf canal.adapter-1.1.5-SNAPSHOT.tar.gz
添加mysql8.0.18连接器
cd /usr/local/canal/canal-adapter/lib/ wget https://repo1.maven.org/maven2/mysql/mysql-connector-java/8.0.18/mysql-connector-java-8.0.18.jar chmod 777 /usr/local/canal-adapter/lib/mysql-connector-java-8.0.18.jar #权限修改与其它lib库一致 chmod +st /usr/local/canal-adapter/lib/mysql-connector-java-8.0.18.jar
修改application.yml
server: port: 8081 spring: jackson: date-format: yyyy-MM-dd HH:mm:ss time-zone: GMT+8 default-property-inclusion: non_null canal.conf: mode: tcp # kafka rocketMQ canalServerHost: 127.0.0.1:11111 # zookeeperHosts: slave1:2181 # mqServers: 127.0.0.1:9092 #or rocketmq # flatMessage: true batchSize: 500 syncBatchSize: 1000 retries: 0 timeout: srcDataSources: defaultDS: url: jdbc:mysql://127.0.0.1:3306/canal_testdb?useUnicode=true username: canal password: Canal@2020! canalAdapters: - instance: example # canal instance Name or mq topic name groups: - groupId: g1 outerAdapters: - name: logger - name: es7 hosts: 192.168.0.200:9300,192.168.0.200:8200 properties: mode: rest # or rest # security.auth: test:123456 # only used for rest mode cluster.name: my-es
修改适配器映射文件
vim /usr/local/canal/canal-adapter/conf/es7/mytest_user.yml
dataSourceKey: defaultDS #指定在application.yml文件中srcDataSources源数据源自定义的名称
destination: example #cannal的instance或者MQ的topic,我们是把数据同步至es,所以不用修改,也用不到此处
groupId: g1 #对应MQ模式下的groupId, 只会同步对应groupId的数据
esMapping: #es中的Mapping设置
_index: canal_tsdb #指定索引名称
_id: _id #指定文档id,_id 此值则由es自动分配文档ID
sql: "select a.id as _id,a.age,a.name,a.address from canal_table a" #sql映射
etlCondition: "where a.c_time>={}" #etl的条件参数
commitBatch: 3000 #提交批大小Elasticsearch创建索引
POST canal_tsdb/_doc
{
"mappings":{
"_doc":{
"properties":{
"age":{
"type":"long"
},
"name":{
"type":"text"
},
"address":{
"type":"text"
}
}
}
}启动Canal-adapter并写入数据
/usr/local/canal/canal-adapter/bin/startup.sh
tail -f /usr/local/canal/canal-adapter/logs/adapter/adapter.log
在MySQL再次插入一条数据并查看日志
INSERT INTO canal_tsdb.canal_table(id, age, name, address) VALUES (2, 88, '小明', '测试');
查看Canal-deployer服务端日志
tail -f /usr/local/canal/canal-deployer/logs/example/meta.log
在es里面可以看到数据
部署Canal Admin
canal-admin的限定依赖:
1.MySQL,用于存储配置和节点等相关数据
2.canal版本,要求>=1.1.4 (需要依赖canal-server提供面向admin的动态运维管理接口)
Canal Admin下载并解压
mkdir /usr/local/canal/canal-admin wget https://github.com/alibaba/canal/releases/download/canal-1.1.5-alpha-1/canal.admin-1.1.5-SNAPSHOT.tar.gz tar xf canal.admin-1.1.5-SNAPSHOT.tar.gz
application.yml
server:
port: 8089 #Canal Admin监听端口
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss #时间格式
time-zone: GMT+8 #时区
spring.datasource: #数据库信息
address: 192.168.0.200:8809 #指定Canal Admin所使用的数据库地址及端口
database: canal_manager #指定数据库名称
username: cadmin #指定数据库账户
password: Cadmin@2020! #指定数据库密码
driver-class-name: com.mysql.jdbc.Driver #指定数据库驱动
url: jdbc:mysql://${spring.datasource.address}/${spring.datasource.database}?useUnicode=true&characterEncoding=UTF-8&useSSL=false
hikari:
maximum-pool-size: 30
minimum-idle: 1
canal: #Canal UI界面默认账号密码
adminUser: admin
adminPasswd: admin创建数据库及授权用户
create database canal_manager character set utf8; create database canal_manager character set utf8; create user cadmin identified by 'Cadmin@2020!'; grant all on canal_manager.* to 'cadmin'@'%'; flush privileges;
/usr/local/canal/canal-admin/conf/canal_manager.sql;数据库数据导入
启动
/usr/local/canal/canal-admin/bin/startup.sh
作者:wmburst
来源:51Testing软件测试网原创
- 0.00 查看剩余0%
- 【留下美好印记】赞赏支持

热门文章
最新讲堂
- 推荐阅读
- 换一换
- 软件测试笔试面试题(一)——软件测试圈11-18软件缺陷:1)软件未实现产品说明书要求的功能2)软件出现了产品说明书指明不应该出现的错误3)软件实现了产品说明书未提到的功能4)软件未实现产品说明书虽未明确提及但应该实现的目标5)软件难以理解、不易使用、运行缓慢或者从测试员的角度看最终用户会认为不好软件测试:为了发现软件产品中的各种缺陷,而对软件产品进行验证和确认的活动过程,此过程贯穿整个软件开发生命周期。 简单的说,软件测试是以发现错误为目的而执行的一个程序或系统的过程。软件测试的目的:验证软件需求和功能是否得到完整实现验证软件是否可以发布尽可能多的发现软件中的bug尽可能早的发现软件中的bug对软件质量做出合理评估预防下个版本可能出现的问...
- 昨日百度 Apollo 在北京车展前夕举办了以“破晓?拥抱智变时刻”为主题的智能汽车产品发布会,围绕汽车智能化,发布了全新升级的“驾舱图”系列产品。 会上,百度 Apollo 正式发布了纯视觉城市领航辅助驾驶产品 ANP3 Pro,官方称将高阶城市智驾的硬件成本拉入万元时代。 从 Apollo 智能驾驶公众号获悉,与当前市场上大部分搭载激光雷达的高阶城市智驾产品不同,ANP3 Pro 采用演进速度更快、算法上限更高的纯视觉技术路线,搭载 1 颗 NVIDIA DRIVE Orin(254TOPS)、11 个摄像头、3 个毫米波雷达以及 12 个超声波雷达,在实现更低 BOM 成本的同时...
-
- 测试开发是测试,还是开发?08-01读者提问:测试开发工程师到底是测试,还是开发 ?阿常回答:既是测试,也是开发。首先,测试开发是测试工程师,他们是服务于业务测试同学的,目标是解决业务测试工程师的具体问题。这就要求他们必须具备测试思维。其次,测试开发也是开发工程师,他们会针对业务测试同学的具体诉求设计研发对应的小工具,或者研发定制化的一套测试平台。这就要求他们同时具备编程能力。阿常碎碎念:前一阵子阿常团队招测试开发时,就有纯开发经历的同学来面试,一般看到这样的简历阿常会直接 pass 不考虑。当然不排除有纯开发经验的同学,同时也具备良好的测试思维,但这只占少数部分。通常都是有真正测试实践经历的测试同学,才可能具备更好的...
- 如何测试你搭建的软件测试环境?——软件测试圈10-18填测试行业问卷,不仅能获得价值398元的测试资料,还可以参与我们的抽奖活动,赶快参与一下吧。链接:http://vote.51testing.com/ 测试过程 在逻辑上。测试活动是按顺序进行的.但是实际测试过程中,这些活动是可以重叠或同时进行的。(比如支付宝的加好友,登录,转账等。对于加好友模块的测试,还是需要先登录这个模块的操作的。) 1、测试策划过程 测试策划分为以下三个部分: 测试策划步骤: 1)进行测试需求的分析,确定需要测试的内容或质量特征,明确测试的充分性要求。 2)提出测试的基本方法。 测试策划需要进行: 1)确定测试的资源和技术需求。 2)进行风险分析...

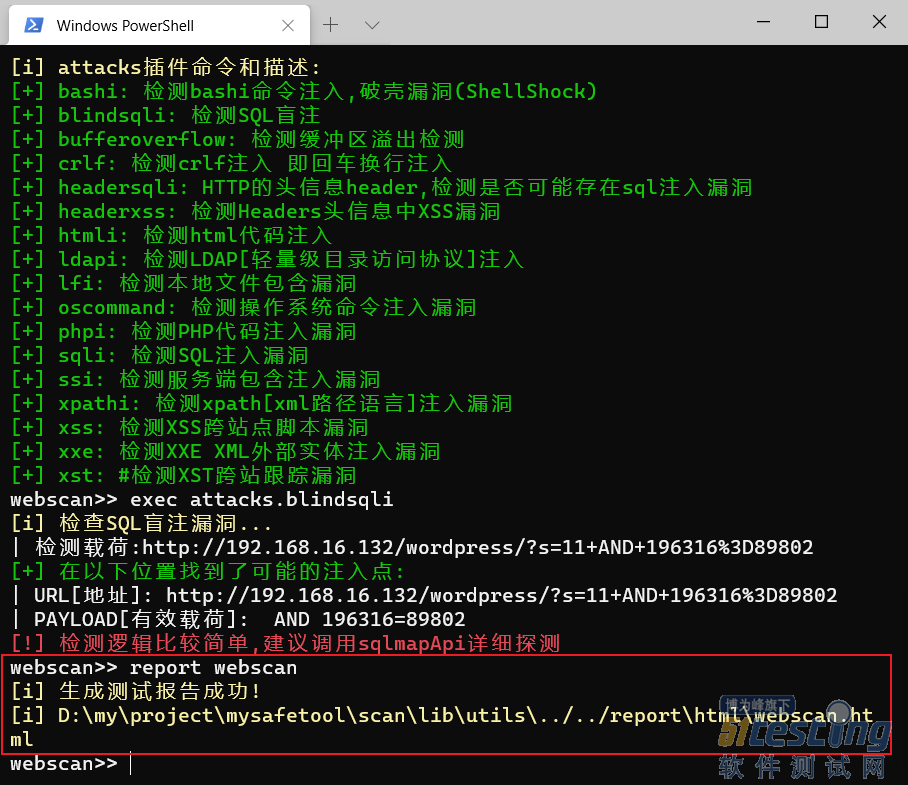
- report命令 生成测试报告命令。 命令参数:report [报告名称]。 注:只有执行过起码一次完整的插件检测才能生成报告,而不是专项漏洞检测,即exec 插件名称,而不是exec插件名称、模块名称。 输入命令:report webscan。 按照提示显示的目录,打开测试报告,报告格式是html的: 好了,以上就是使用扫描器的所有命令和完整的执行流程。 插件的编写 大家按章节一的下载地址下载工具后,用vscode或者你顺手的工具打开,插件扫描器就在scan目录下。 我们的插件编写,先从scan\lib\utils\settings.py全局配置文件开始。 第一步:先...
-

——软件测试圈》&软件缺陷:1)软件未实现产品说明书要求的功能2)软件出现了产品说明书指明不应该出现的错误3)软件实现了产品说明书未提到的功能4)软件未实现产品说明书虽未明确提及但应该实现的目标5)软件难以理解、不易使用、运行缓慢或者从测试员的角度看最终用户会认为不好软件测试:为了发现软件产品中的各种缺陷,而对软件产品进行验证和确认的活动过程,此过程贯穿整个软件开发生命周期。 简单的说,软件测试是以发现错误为目的而执行的一个程序或系统的过程。软件测试的目的:验证软件需求和功能是否得到完整实现验证软件是否可以发布尽可能多的发现软件中的bug尽可能早的发现软件中的bug对软件质量做出合理评估预防下个版本可能出现的问...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=904&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=904&pic=http://quan.51testing.com/ueditor/php/upload/image/20201118/1605664894624732.png){kind=link}
 1、测试策划过程 测试策划分为以下三个部分: 测试策划步骤: 1)进行测试需求的分析,确定需要测试的内容或质量特征,明确测试的充分性要求。 2)提出测试的基本方法。 测试策划需要进行: 1)确定测试的资源和技术需求。 2)进行风险分析...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=145477&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=145477&pic=http://quan.51testing.com/ueditor/php/upload/image/20221018/1666083159963962.png){kind=link}
——软件测试圈》& report命令 生成测试报告命令。 命令参数:report [报告名称]。 注:只有执行过起码一次完整的插件检测才能生成报告,而不是专项漏洞检测,即exec 插件名称,而不是exec插件名称、模块名称。 输入命令:report webscan。 按照提示显示的目录,打开测试报告,报告格式是html的: 好了,以上就是使用扫描器的所有命令和完整的执行流程。 插件的编写 大家按章节一的下载地址下载工具后,用vscode或者你顺手的工具打开,插件扫描器就在scan目录下。 我们的插件编写,先从scan\lib\utils\settings.py全局配置文件开始。 第一步:先...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=117133&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=117133&pic=http://quan.51testing.com/ueditor/php/upload/image/20210603/1622685292857008.png){kind=link}
- 关于我们 联系我们 版权声明 广告服务 站长统计
- 建议使用IE 11.0以上浏览器,800×600以上分辨率,法律顾问:上海兰迪律师事务所 项棋律师
- 版权所有 上海博为峰软件技术股份有限公司 Copyright©51testing.com 2003-2024, 沪ICP备05003035号
- 投诉及意见反馈:webmaster@51testing.com; 业务联系:service@51testing.com021-64471599-8017

- 51testing软件测试圈微信