 14
14 14
14


- Oracle数据库性能测试过程中索引使用问题记录——软件测试圈
近日在执行Oracle数据库性能测试时,通过在使用JMeter发压前后分别生成数据库快照,进而生成AWR报告分析,发现某一SQL语句的执行时间较长,遂对此语句进行分析。
通过AWR报告中Main Report-->SQL Statistics-->Elapsed Time per Exec(s)找到执行时间长的SQL语句(注意需根据Elapsed Time(s)/Executions和SQL Module判断此语句是否为发压过程中实际执行的查询语句),并记录其SQL Id。执行select * from table(dbms_xplan.display_awr(‘9p4xcbfjzx27z’)),其中“9p4xcbfjzx27z”为SQL Id,获得此SQL语句的执行计划,发现T表在查询时使用了全表扫描(TABLE ACCESS FULL),如图1所示。分析具体的SQL语句:select T.x, T.y from T where T.z !=‘A’,发现T表在y列和z列建立了一个联合索引,那么为什么执行这条SQL语句时仍然使用了全表扫描呢?这个问题可以从以下三个方面分析。

图1 在T表上执行查询操作时使用了全表扫描
一、单独引用联合索引里非第一位置的索引列作为条件查询时不走索引。T表中与z列有关的索引是与y列共同组成的联合索引,如图2所示。而y列做为联合索引中位于第一位置的索引,在此查询中并未应用,因此单独查询z列时并未使用此联合索引。建议将可选性高的字段和使用频繁的字段放在组合索引顺序的前面,因为联合索引的前缀性,只有左侧的索引字段得到应用,后面的索引才可能得到应用。举个例子,索引建立成IDX_TABLENAME(A,B,C),当where条件中包含(A)或(A,B)或(A,B,C)时可以应用索引,条件为(B,C)时不能应用索引,条件为(A,C)时只有A字段可以应用索引。注:可选性也叫区分度,指的是字段中唯一值的数量多少,可以用选择率来衡量。选择率=字段中唯一值总行数/字段总行数,选择率越高代表可选性越高。图3为联合索引条件查询时使用和不使用第一位置列时的索引使用情况。

图2 T表的yz联合索引

图3 联合索引条件查询时(a)使用和(b)不使用第一位置列时的索引使用情况
二、不等于(<>、!=等)、not in等不走索引。若T表中的索引并不是组合索引,而是仅在z列创建索引,那么第一个问题将不存在,但负向查询的操作同样会导致索引失效。负向查询指的是NOT,!=,<>,!<,!>等操作符对条件字段进行操作的查询。这些负向操作相当于需遍历整个字段,因此无法用到索引。图4为条件查询时不使用和使用负向操作时的索引使用情况,为实验更加直观,只对z列创建索引。

图4 条件查询时(a)不使用和(b)使用负向操作时的索引使用情况
三、数据量分布会影响索引使用。根据应用的特点,当SQL返回的行数占整个表行数的比例<=5%时,建议建立索引。当查询的字段返回行数比例超过一定阈值,即可选性过低时,优化器认为全表扫描更省时间,不会使用该字段的索引。即若不考虑问题一和问题二,z列中A值的占比也将影响索引的使用。图5为条件查询时返回数据量占比高和返回数据量占比低时的索引使用情况,为实验更加直观,只对z列创建索引,z值为6占所有数据的98%,z值为7占所有数据的1%。可以看到(b)实验结果并未像预想的那样全表扫描,而是同样使用了索引,这说明以上三条的索引使用准则适用于大部分情况,但仍有少数情况需视数据库类型、版本、优化策略、数据等而定。

图5 条件查询时(a)返回数据量占比高和(b)返回数据量占比低时的索引使用情况
以上就是近期Oracle数据库性能测试过程中关于索引使用问题的分享,欢迎批评指正。
作者:张东宇、陈明坤
来源:51Testing软件测试网原创
- 0.00 查看剩余0%
- 【留下美好印记】赞赏支持

热门文章
最新讲堂
- 推荐阅读
- 换一换
- 据路透社报道,马斯克旗下的脑机接口公司 Neuralink 在完成首次人体试验后,公司估值大幅上涨,引发内部员工趁热出售股票的热潮。知情人士透露,部分员工正在积极筹备出售手中的股票。 对于初创公司 Neuralink 来说,股票期权是吸引人才的重要手段。然而,这些股票并不在公开市场交易,员工若想出售必须通过复杂的私人市场交易。 消息人士称,Neuralink 最快可能在下个月启动股票回购计划,允许希望出售股份的员工套现。 自今年 1 月启动首次人体试验以来,Neuralink 的估值显著提升,这一点从二级市场的交易数据可见一斑。虽然交易量较小,无法准确反映当前估值,但普遍认为该公司估...
-
- 测试工程师如何规划自己的职业生涯——软件测试圈08-12很多人的职业规划是到了工作以后才开始进行的,其实,这样做,有很大的局限性。凡是工作过的人,都有一个体会,就是自己的第一份工作,会影响到5~10年的发展轨迹,甚至会对一生产生影响。因此,选择一份合适的工作作为起点,是必须要在校园内思考清楚的问题。由于中国的教育基本是理论教育,大家在工作前的实践能力大多比较弱,固然有其不足,但也有好的一面,那就是可塑性比较好。可塑性好代表了选择的余地可以很大,因此,大家在选择第一份工的时候,要充分结合自己的教育背景、个人能力、兴趣爱好、长期目标等等,作出理性的决策。软件测试,特别是黑盒软件测试是一种入门起点较低、上手迅速、且发展空间比较大的职业,因此,对于很多学生...
- 金牌面试官,看简历时都注意些什么?——软件测试圈04-25摘要:金三银四, 是求职者蠢蠢欲动的季节,亦是企业摩拳擦掌的季节。 今年是疫情开放后,第一个金三银四, 所以,很多求职者和企业都很期待,也很重视。 为什么这样说?因为作为企业的一名金牌面试官,我收到的内推简历的数量, 就比平时多了不少,更别说社招投递简历了。同时,就整个大环境而言,除了近期某森哲的裁员消息之外,其他的互联网大厂相对来说还算稳定,也是复苏的节奏。 尤其是在OpenAI的加持下,以及国家对人工智能领域的推广,在整个人工智能领域的需求还是蛮大的。 所以,为了能让求职者更快找到工作, 今天我们就来聊一聊面试官的心理。也就是从面试官的角度,如何筛选简历、如何挑选求职者。 面...
- 2022年早已过半,来个迟到的年中总结,说实话,2022,很迷茫,然后过的非常不如意,倒不是上一年的职业目标没达到,而是接下来的路根本不知道如何走。在没解决这个问题之前,或者说没搞清楚自己的方向之前,是迟迟不能落笔的,啊不,应该是落键盘。 下班后花了几天的时间研究了下测试的职业生涯规划,在许许多多的文章之中穿梭,结合前阵子和某公司t3级的大大面试,对自己接下来的几年职业规划,总算有了眉目,让恍惚的心总算有了着落。 先说我这三年坎坷的经历 刚毕业,计算机专业的我进入了软件测试这个行业,然后外包到了某bat公司,在今天看来,这间公司应该是学习资源最丰富的公司,可悲哀的是,基础能力薄弱,资...
-
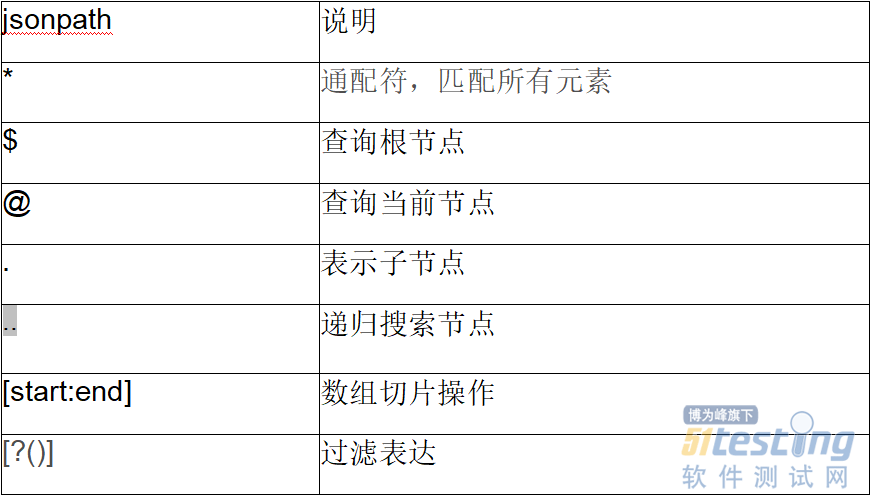
- 摘要:我们在做接口测试时,大多数返回的都是json属性,我们需要通过接口返回的json提取出来对应的值,然后进行做断言或者提取想要的值供下一个接口进行使用。 但是如果返回的json数据嵌套了很多层,通过查找需要的词,就很不方便,小编今天介绍一种python的第3方库jsonpath。 jsonpath jsonpath是使用一种简单的方法来提取给定JSON内容。在我们做接口测试时,目前流行的数据格式就是JSON格式的,当碰到复杂JSON格式时,我们可以使用JsonPath快速提取数据或者更新数据。 安装:pip install jsonpath。 小编先通过正常的接口,获取一段j...
-

{kind=link}
- 关于我们 联系我们 版权声明 广告服务 站长统计
- 建议使用IE 11.0以上浏览器,800×600以上分辨率,法律顾问:上海兰迪律师事务所 项棋律师
- 版权所有 上海博为峰软件技术股份有限公司 Copyright©51testing.com 2003-2024, 沪ICP备05003035号
- 投诉及意见反馈:webmaster@51testing.com; 业务联系:service@51testing.com021-64471599-8017

- 51testing软件测试圈微信