 0
0 1
1


- 五个简单的SQL查询性能测试题,只有40%及格率,你敢来挑战吗?
下面是 5 个关于索引和 SQL 查询性能的测试题;其中 4 个题目都是答案二选一,1 个题目是三选一。只要答对 3 个就算及格,是不是貌似很简单?但实际上只有 40% 的人能够及格。我们在测试题的后面会给出答案解析,不过建议你先尝试一下,看看答对几个!
测试题
问题 1:以下查询语句有没有性能问题?
CREATE TABLE t1 ( id INT NOT NULL, dt DATE, PRIMARY KEY (id) ); CREATE INDEX idx1 ON t1(dt); SELECT * FROM t1 WHERE TO_CHAR(dt, 'YYYY') = '2019'; -- Oracle、PostgreSQL -- WHERE YEAR(dt) = '2019'; -- MySQL -- WHERE datepart(yyyy, dt) = '2019'; -- SQL Server
选项 A:没问题;选项 B:有问题。
问题 2:以下查询语句有没有性能问题?
CREATE TABLE t2 ( id INT NOT NULL, i INT dt DATE, v VARCHAR(50), PRIMARY KEY (id) ); CREATE INDEX idx2 ON t2(i, dt); SELECT * FROM t2 WHERE i = 99 ORDER BY dt DESC FETCH FIRST 5 ROW ONLY; -- Oracle、SQL Server、PostgreSQL -- OFFSET 0 ROWS FETCH FIRST 5 ROW ONLY; -- SQL Server -- LIMIT 5; -- MySQL
选项 A:没问题;选项 B:有问题。
问题 3:下表中的索引有没有问题?
CREATE TABLE t3 ( id INT NOT NULL, col1 INT, col2 INT, col3 VARCHAR(50), PRIMARY KEY (id) ); CREATE INDEX idx3 ON t3(col1, col2); SELECT * FROM t3 WHERE col1 = 99 AND col2 = 10; SELECT * FROM t3 WHERE col2 = 10;
选项 A:没问题;选项 B:有问题。
问题 4:以下查询语句有没有性能问题?
CREATE TABLE t4 ( id INT NOT NULL, col1 INT, col2 VARCHAR(50), PRIMARY KEY (id) ); CREATE INDEX idx4 ON t4(col2); SELECT * FROM t4 WHERE col2 LIKE '%sql%';
选项 A:没问题;选项 B:有问题。
问题 5:假如存在以下表和两个查询语句,哪个查询更快?
CREATE TABLE t5 ( id INT NOT NULL, col1 INT, col2 INT, col3 VARCHAR(50), PRIMARY KEY (id) ); CREATE INDEX idx5 ON t5(col1, col3); SELECT col3, count(*) FROM t5 WHERE col1 = 99 GROUP BY col3; SELECT col3, count(*) FROM t5 WHERE col1 = 99 AND col2 = 10 GROUP BY col3;
选项 A:第一个查询更快;选项 B:第二个查询更快;选项 C:两个查询性能差不多。
解析:
问题1:答案是B,性能有问题。
因为在索引字段上使用函数或者表达式,会导致索引失效。
你可以使用 EXPLAIN 命令查看该语句的执行计划,最好先执行一次表的统计分析:
-- Oracle
EXPLAIN PLAN FOR
SELECT *
FROM t1
WHERE TO_CHAR(dt, 'YYYY') = '2019';
SELECT * FROM TABLE(dbms_xplan.display);
PLAN_TABLE_OUTPUT |
--------------------------------------------------------------------------|
Plan hash value: 3617692013 |
|
--------------------------------------------------------------------------|
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time ||
--------------------------------------------------------------------------|
| 0 | SELECT STATEMENT | | 1 | 22 | 2 (0)| 00:00:01 ||
|* 1 | TABLE ACCESS FULL| T1 | 1 | 22 | 2 (0)| 00:00:01 ||
--------------------------------------------------------------------------|
|
Predicate Information (identified by operation id): |
--------------------------------------------------- |
|
1 - filter(TO_CHAR(INTERNAL_FUNCTION("DT"),'YYYY')='2019') |
|
Note |
----- |
- dynamic statistics used: dynamic sampling (level=2) |Oracle 中是全表扫描,没有走索引。再看 MySQL:
-- MySQL EXPLAIN SELECT * FROM t1 WHERE YEAR(dt) = '2019'; id|select_type|table|partitions|type |possible_keys|key |key_len|ref|rows|filtered|Extra | --|-----------|-----|----------|-----|-------------|----|-------|---|----|--------|------------------------| 1|SIMPLE |t1 | |index| |idx1|4 | | 1| 100|Using where; Using index|
MySQL 虽然使用了索引,但是也需要对索引进行转换判断;并不是最优方案。
接下来是 SQL Server:
-- SQL Server SET STATISTICS PROFILE ON SELECT * FROM t1 WHERE datepart(yyyy, dt) = '2019'; Rows|Executes|StmtText |StmtId|NodeId|Parent|PhysicalOp|LogicalOp |Argument |DefinedValues |EstimateRows|EstimateIO |EstimateCPU |AvgRowSize|TotalSubtreeCost |OutputList |Warnings|Type |Parallel|EstimateExecutions| ----|--------|---------------------------------------------------------------------------------------------------------|------|------|------|----------|----------|----------------------------------------------------------------------------------------|----------------------------------------------|------------|---------------------|---------------------|----------|---------------------|----------------------------------------------|--------|--------|--------|------------------| 0| 1|SELECT * FROM t1 WHERE datepart(yyyy, dt) = '2019' | 1| 1| 0| | | | | 1| | | |0.0032830999698489904| | |SELECT | 0| | 0| 1| |--Index Scan(OBJECT:([hrdb].[dbo].[t1].[idx1]), WHERE:(datepart(year,[hrdb].[dbo].[t1].[dt])=(2019)))| 1| 2| 1|Index Scan|Index Scan|OBJECT:([hrdb].[dbo].[t1].[idx1]), WHERE:(datepart(year,[hrdb].[dbo].[t1].[dt])=(2019))|[hrdb].[dbo].[t1].[id], [hrdb].[dbo].[t1].[dt]| 1|0.0031250000465661287|1.5809999604243785E-4| 14|0.0032830999698489904|[hrdb].[dbo].[t1].[id], [hrdb].[dbo].[t1].[dt]| |PLAN_ROW| 0| 1|
SQL Server 使用了索引,但是也需要对索引进行转换判断;并不是最优方案。
最后看一下 PostgreSQL:
-- PostgreSQL EXPLAIN SELECT * FROM t1 WHERE TO_CHAR(dt, 'YYYY') = '2019'; QUERY PLAN | --------------------------------------------------------------------------------| Seq Scan on t1 (cost=0.00..49.55 rows=11 width=8) | Filter: (to_char((dt)::timestamp with time zone, 'YYYY'::text) = '2019'::text)|
PostgreSQL 使用的是全表扫描,没有使用索引。
正确做法是修改查询语句:
SELECT * FROM t WHERE dt BETWEEN DATE '2019-01-01' AND DATE '2019-12-31';
备注:使用函数索引并不是最优解决方法,它只能用于特定的查询条件;如果查询条件改成 TO_CHAR(dt, 'YYYY-MM-DD') = '2019-06-01'或者其他形式就无法使用该索引了。
问题2答案是:A,性能没有问题。
该语句的 WHERE 子句以及 ORDER BY 子句都可以使用索引(反向扫描),不需要对任何行进行额外的排序。可以使用上面的方法查看执行计划。
问题3答案是:B,索引有问题。
因为第二个查询无法使用索引或者效率不高。虽然有些数据库可能采用索引跳跃扫描,但是可以通过修改索引字段的顺序获得更好的性能:
CREATE INDEX idx3 ON t3(col2, col1);
将 col2 放在索引的最左端,两个查询都可以利用索引;也就是说,复合索引应该遵循最左前缀原则。另外,基于 col2 再创建一个索引会导致索引重复,不是好的方案。
问题4答案是:B,性能有问题。
因为在 LIKE 条件中以通配符 % 或者 _ 开始的字符串无法使用索引。不过,以下语句可以使用索引:
SELECT * FROM t4 WHERE col2 LIKE 'sql%';
对于 PostgreSQL 而言,还需要在创建索引时指定操作符类:
-- PostgreSQL CREATE INDEX idx4 ON t4(col2 varchar_pattern_ops);
问题5答案是:A,第一个查询更快。
因为它只需要通过扫描索引(Index-Only Scan)就可以得到结果;第二个查询虽然可能返回的数据更少,但是需要通过索引访问表,也就是回表。
你答对了几个?欢迎留言讨论!
本文为51Testing经授权转载,转载文章所包含的文字来源于作者:董旭阳TonyDong。如因内容或版权等问题,请联系51Testing进行删除。原文链接:https://blog.csdn.net/horses/article/details/103028340.
- 0.00 查看剩余0%
- 【留下美好印记】赞赏支持
热门文章
最新讲堂
- 推荐阅读
- 换一换
- 功能测试与性能测试区别——软件测试圈03-08功能测试主要根据产品的需求规格说明书和测试需求列表,验证产品的功能实现是否符合产品的需求规格。功能测试在测试工作中占的比例最大,功能测试也叫黑盒测试。是把测试对象看作一个黑盒子。利用黑盒测试法进行动态测试时,需要测试软件产品的功能,不需测试软件产品的内部结构和处理过程。采用黑盒技术设计测试用例的方法有:等价类划分、边界值分析、错误推测、因果图和综合策略。主要为了发现以下几类错误:A、是否有不正确或遗漏的功能;B、功能实现是否满足用户需求和系统设计的隐藏需求;C、能否正确接收输入,能否正确输出结果。需要非常熟悉的关键项(基于产品):A、规格说明;B、需求文档;C、业务功能。测试属于黑盒,主要方法...
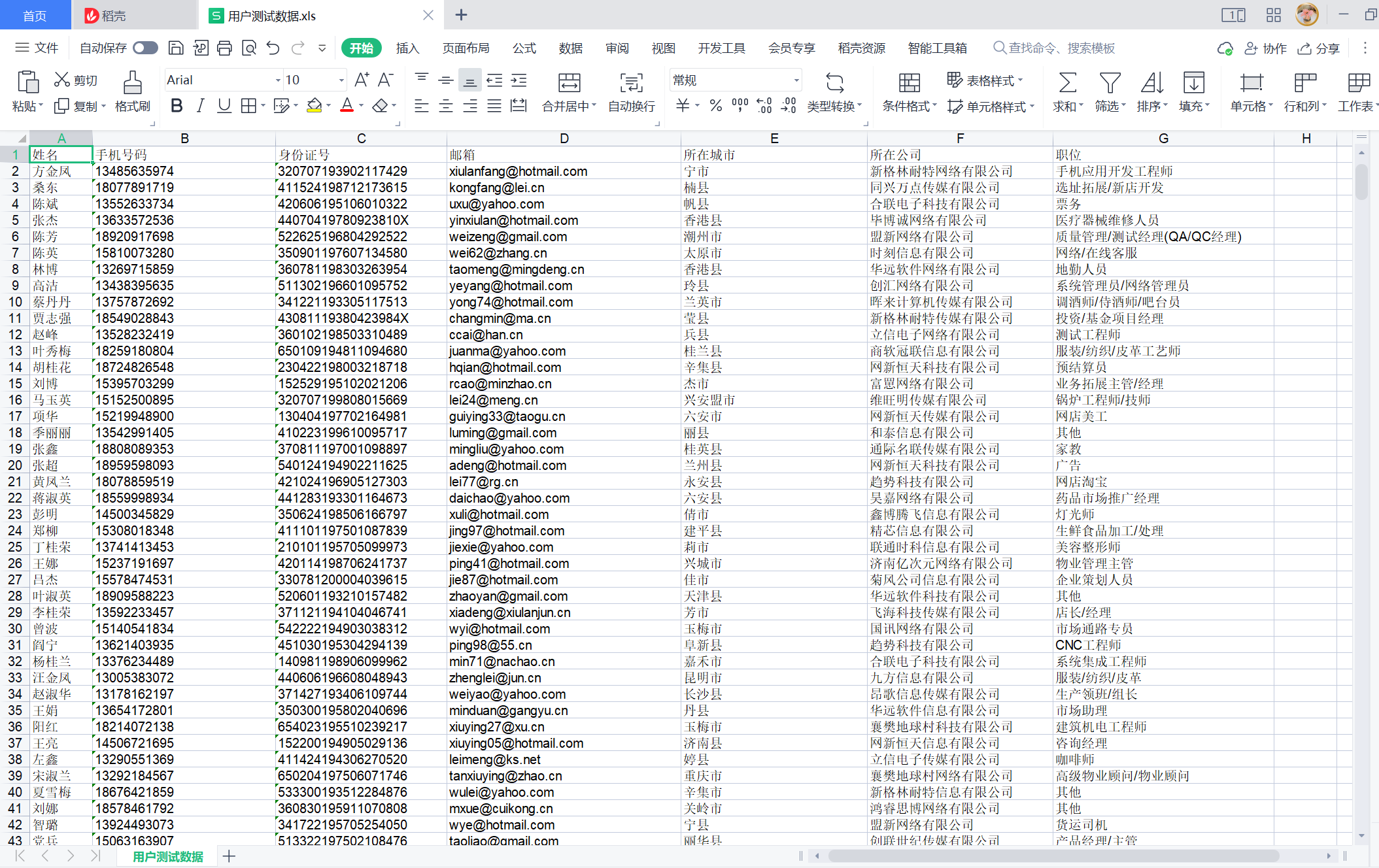
- 昨天的文章中给大家介绍到了批量生成企业数据,今天为大家贴上批量生成个人信息的代码。生成的个人信息数据如下截图: 批量生成个人信息的代码如下:from faker import Faker import xlwt faker = Faker('zh_CN') def add_user_info(number): work_book = xlwt.Workbook(...
-
- QA之评审底层测试——软件测试圈06-27QA评审底层测试的价值体现在这几个方面: 最重要的是利用QA的测试技能,可以发现Dev所写底层测试可能存在的问题,让测试更有效。 QA通过review底层测试,能够更好的了解测试覆盖情况,更清楚整体的测试状态。 QA看Dev写的测试,可以起到督促他们编写测试的作用。 但是,如果没做好,就会变成一种形式,Dev把测试给QA看一遍,QA就是稀里糊涂的过一遍,没有输入也没有反馈……这样的话,当然就没有价值了,而且还会浪费大家的时间。 虽然说的QA评审测试,其实是Dev和QA合作完成的事情,要想做好,对Dev和QA都有不同的要求。 首先,对Dev的要求: 自己要能清晰理解所有的测试,...
- 解析自动化测试对敏捷项目的意义与应用08-27摘要本文主要围绕自动化测试对敏捷开发的意义进行分析,对比自动化测试在传统瀑布项目和敏捷开发项目中的不同点,展开解析自动化测试在敏捷项目中的应用的各大要素,最后延伸到DevOps中的测试自动化,探讨在不同情况下这些因素对项目的影响和意义,以期正确合理的在采用敏捷模式的项目中组织规划自动化测试。1、背景Background前段时间在一次项目评审会议上,公司的一群大佬们(博士级别的高管、首席架构师,摩拜ing)进行了一些有意思的讨论,针对几个项目自动化测试到底能带来什么样的价值,是否值得做。省钱?未必!省时?未必!那为啥要做自动化?按理好像一目了然的答案却没有当场得出结论。什么样的自动化才是我们想要...
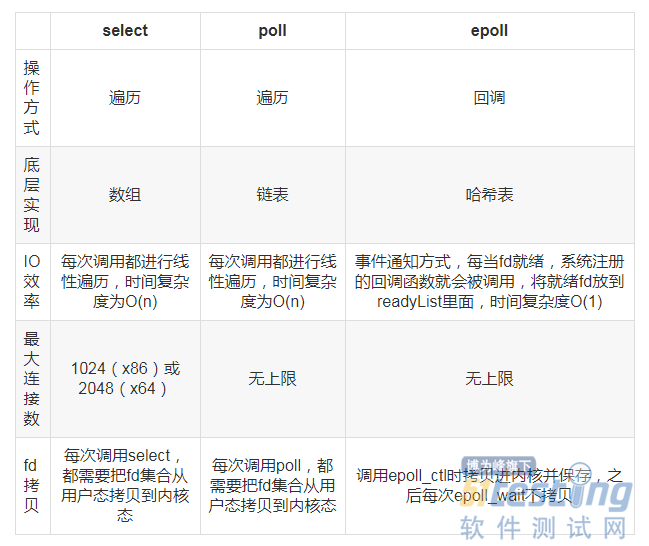
- I/O多路复用就是通过一种机制,可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知应用程序进行相应的读写操作。 1.select 基本原理:select 函数监视的文件描述符分3类,分别是writefds、readfds、和exceptfds。调用后select函数会阻塞,直到有描述符就绪(有数据 可读、可写、或者有except),或者超时(timeout指定等待时间,如果立即返回设为null即可),函数返回。当select函数返回后,可以通过遍历fdset,来找到就绪的描述符。 被监控的fd在select()后会发生改变,所以在下一次进入select()之前...
-





def add_user_info(number):
work_book = xlwt.Workbook(...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=144761&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=144761&pic=http://quan.51testing.com/ueditor/php/upload/image/20220601/1654080972719202.png){kind=link}
进行了一些有意思的讨论,针对几个项目自动化测试到底能带来什么样的价值,是否值得做。省钱?未必!省时?未必!那为啥要做自动化?按理好像一目了然的答案却没有当场得出结论。什么样的自动化才是我们想要...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=270&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=270&pic=http://quan.51testing.com/ueditor/php/upload/image/20190819/1566196919119261.png){kind=link}
,能够通知应用程序进行相应的读写操作。 1.select 基本原理:select 函数监视的文件描述符分3类,分别是writefds、readfds、和exceptfds。调用后select函数会阻塞,直到有描述符就绪(有数据 可读、可写、或者有except),或者超时(timeout指定等待时间,如果立即返回设为null即可),函数返回。当select函数返回后,可以通过遍历fdset,来找到就绪的描述符。 被监控的fd在select()后会发生改变,所以在下一次进入select()之前...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=143931&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=143931&pic=http://quan.51testing.com/ueditor/php/upload/image/20210726/1627263913827722.png){kind=link}
- 关于我们 联系我们 版权声明 广告服务 站长统计
- 建议使用IE 11.0以上浏览器,800×600以上分辨率,法律顾问:上海兰迪律师事务所 项棋律师
- 版权所有 上海博为峰软件技术股份有限公司 Copyright©51testing.com 2003-2024, 沪ICP备05003035号
- 投诉及意见反馈:webmaster@51testing.com; 业务联系:service@51testing.com021-64471599-8017

- 51testing软件测试圈微信