 0
0 0
0
分享


- Python+Jinja2实现接口数据批量生成工具
在做接口测试的时候,我们经常会遇到一种情况就是要对接口的参数进行各种可能的校验,手动修改很麻烦,尤其是那些接口参数有几十个甚至更多的,有没有一种方法可以批量的对指定参数做生成处理呢。
答案是肯定的!
python的jinja2模板库可以很好的满足我们的需求,通过维护一个原始数据模板,将我们想要动态生成的变量模板化,就可以实现需求。
现在我们有这样的一个请求数据
{
"abc":"123",
"p2p":"123",
"smid":"20180807220733939b66d80092eea34ce9e77f30bedff12345b7d5a3faa11b",
"test":{
"test1":"1",
"test2":"2"
},
"test3":"3"}如果想对其中的smid字段进行批量修改并生成新的请求数据就可以进行如下操作:
1、首先新建一个名为fp_template.txt的文本文件;
2、将上面的接口请求数据复制粘贴进这个txt文件中,我们以此作为“模板文件”;
3、新建一个predata文件夹用来存放生成后的数据文件;
4、对smid字段进行模板化(模板格式可以参考jinja2的语法,这里不做赘述),于是上面的请求参数就变成了下面这样:
{
"abc":"123",
"p2p":"123",
"smid":"{{ smid }}",
"test":{
"test1":"1",
"test2":"2"
},
"test3":"3"}实现代码代码如下:
# -*- coding: UTF-8 -*-from jinja2 import Environment,FileSystemLoaderimport osclass DataTemplateFaker:
def __init__(self):
self.aesPath = os.getcwd()#获取启动路径
self.resultPath = self.aesPath + "/predata/"#指定用来保存生成数据的路径
self.templateFile = "fp_template.txt"
#修改我们要批量生成smid的格式
def init_smid(self,start,end):
smidArg = [x for x in range(start, end)]
re = []
for n in smidArg:
re.append("20180807220733939b66d80092eea34ce9e77f30bedff" + str(n) + "b7d5a3faa11b")
return re #操作模板文件
def preContent(self,arg):
env = Environment(loader=FileSystemLoader('./'))
tpl = env.get_template(self.templateFile)
renderContent = tpl.render(smid=arg)
return renderContent #通过修改的smid列表批量替换模板文件并写入指定文件中
def makeContent(self,preList):
x = 0
for i in preList:
x = x + 1
filename = str(self.resultPath) + 'data_' + str(x) + '.txt' #用以区分存放新生成的请求数据(也可以写到一个文件中)
renderContent = self.preContent(i)
with open(filename, 'w') as f:
f.writelines(renderContent)
f.close()if __name__ == "__main__":
AT = DataTemplateFaker()
reList = AT.init_smid(1,10)#控制生成数据的范围
AT.makeContent(reList)运行程序,就能得到新生成的数据
当然,我们也可以对其他的参数进行指定修改,如修改p2p,只需要修改模板文件:
{ "abc":"123",
"p2p":"{{ p2p }}",
"smid":"20180807220733939b66d80092eea34ce9e77f30bedff12345b7d5a3faa11b",
"test":{
"test1":"1",
"test2":"2"
},
"test3":"3"}然后在代码中加入一个方法init_p2p()
# -*- coding: UTF-8 -*-from jinja2 import Environment,FileSystemLoaderimport osclass DataTemplateFaker:
def __init__(self):
self.aesPath = os.getcwd()#获取启动路径
self.resultPath = self.aesPath + "/predata/"#指定用来保存生成数据的路径
self.templateFile = "fp_template.txt"
#修改我们要批量生成smid的格式
def init_smid(self,start,end):
smidArg = [x for x in range(start, end)]
re = []
for n in smidArg:
re.append("20180807220733939b66d80092eea34ce9e77f30bedff" + str(n) + "b7d5a3faa11b")
return re #修改我们要批量生成p2p的格式
def init_p2p(self,start,end):
p2pArg = [x for x in range(start, end)]
return p2pArg #操作模板文件
def preContent(self,arg):
env = Environment(loader=FileSystemLoader('./'))
tpl = env.get_template(self.templateFile)
renderContent = tpl.render(smid=arg)
return renderContent #通过修改的smid列表批量替换模板文件并写入指定文件中
def makeContent(self,preList):
x = 0
for i in preList:
x = x + 1
filename = str(self.resultPath) + 'data_' + str(x) + '.txt' #用以区分存放新生成的请求数据(也可以写到一个文件中)
renderContent = self.preContent(i)
with open(filename, 'w') as f:
f.writelines(renderContent)
f.close()if __name__ == "__main__":
AT = DataTemplateFaker()
reList = AT.init_p2p(1,10)#控制生成数据的范围
AT.makeContent(reList)这只是一个很简单的demo,当然还有很多可优化的地方,比如多字段同时修改、引入faker库进行关联生成伪造数据等,越是复杂且参数繁多的接口越适用,其他的方法就可以天马行空,任君发挥了。
本文为51Testing经授权转载,转载文章所包含的文字来源于作者:复现。如因内容或版权等问题,请联系51Testing进行删除。原文链接:https://www.jianshu.com/p/2321f4942b10。
- 0.00 查看剩余0%
- 【留下美好印记】赞赏支持
登录 后发表评论
恬恬圈51Testing测试圈官方编辑
+ 关注
热门文章
最新讲堂
温馨提示
- 推荐阅读
- 换一换
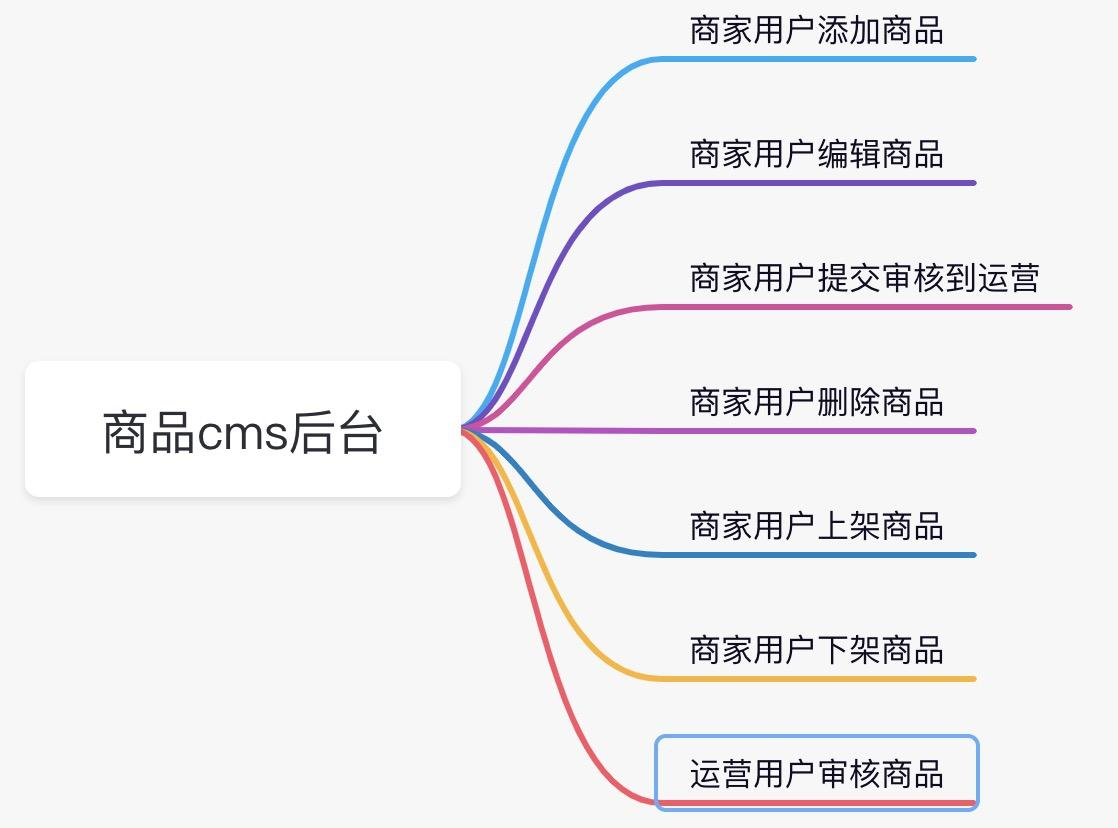
- 随着开发模式的迭代更新,前后端分离已不是新的概念,现在大部分的项目都采用这种开发模式;当我们拿到待测试需求时,可能后端已开发完成,但前端还未完成,我们需要进行接口验证,那如何进行接口测试?就这个话题,进行一个探讨,我们先去做接口测试,从结果上来分析到底需不需要做接口测试,测试哪些内容等等。开始之前,先虚拟一个产品需求:需求描述:假设我们要做一个全新的后台项目,商品CMS管理平台(这里抛去复杂逻辑,因为需求无限拓展下去,势必大家对需求认知产生分歧,从而对测试内容产生分歧)。第一期的功能,商家用户可以在平台上进行商品的创建,编辑,删除,查询,上下架等操作;运营用户可以审核商家的商品;我们来简单描述...
-
- 面试题总结之接口测试篇(一)08-03# 前言一直以来都有人问我,有没有面试题的总结。面试题积累了很多,但没有时间去汇总。这次拿出时间整理一下接口测试相关的面试题,并给出详细参考答案!!!# 第一篇 基础问答(上)### 1. 你测试的接口是如何添加验证点的?接口测试的验证点,也就是接口的断言,通过接口断言,可以实现脚本对程序运行结果的自动验证,输出成功或失败的状态,省去人为判断的过程。对于接口的验证点,我们可以根据任务紧急度和测试目的,粒度上由粗到细,从以下几个角度去依次添加。1) 验证接口响应状态码为200。这是接口测试的最基本要求,响应状态码200代表了该接口能接收请求,能返回响应。如果测试任务比较重,时间比较紧,应该首先针...
- 测试用例好难写怎么办?——软件测试圈04-19在说怎么写测试用例之前呢,先来聊聊为什么要写测试用例。理由有5点:理顺思路,避免漏测和重复测试帮助预估测试排期,把控进度方便bug回归验证便于发现、记录并复现问题标记测试结果,即对于测试结果有个交代知道了写用例目的之后,你还需要知道,什么样的测试用例才是好的!优秀测试用例的特征:包含基本信息,包括测试人/开发/产品/需求文档链接地址/技术文档链接地址,等等你测试过程中需要的物料。每一条用例,有很明显的突出测试预期和测试目的。所有用例都是可执行的。逻辑脉络清晰,几乎不存在重复的用例,简约而不简单。用例做到分级分层。待测功能点覆盖全面。同时还是想要强调2个观点:不要纠结测试用例的格式或形式!测试用...

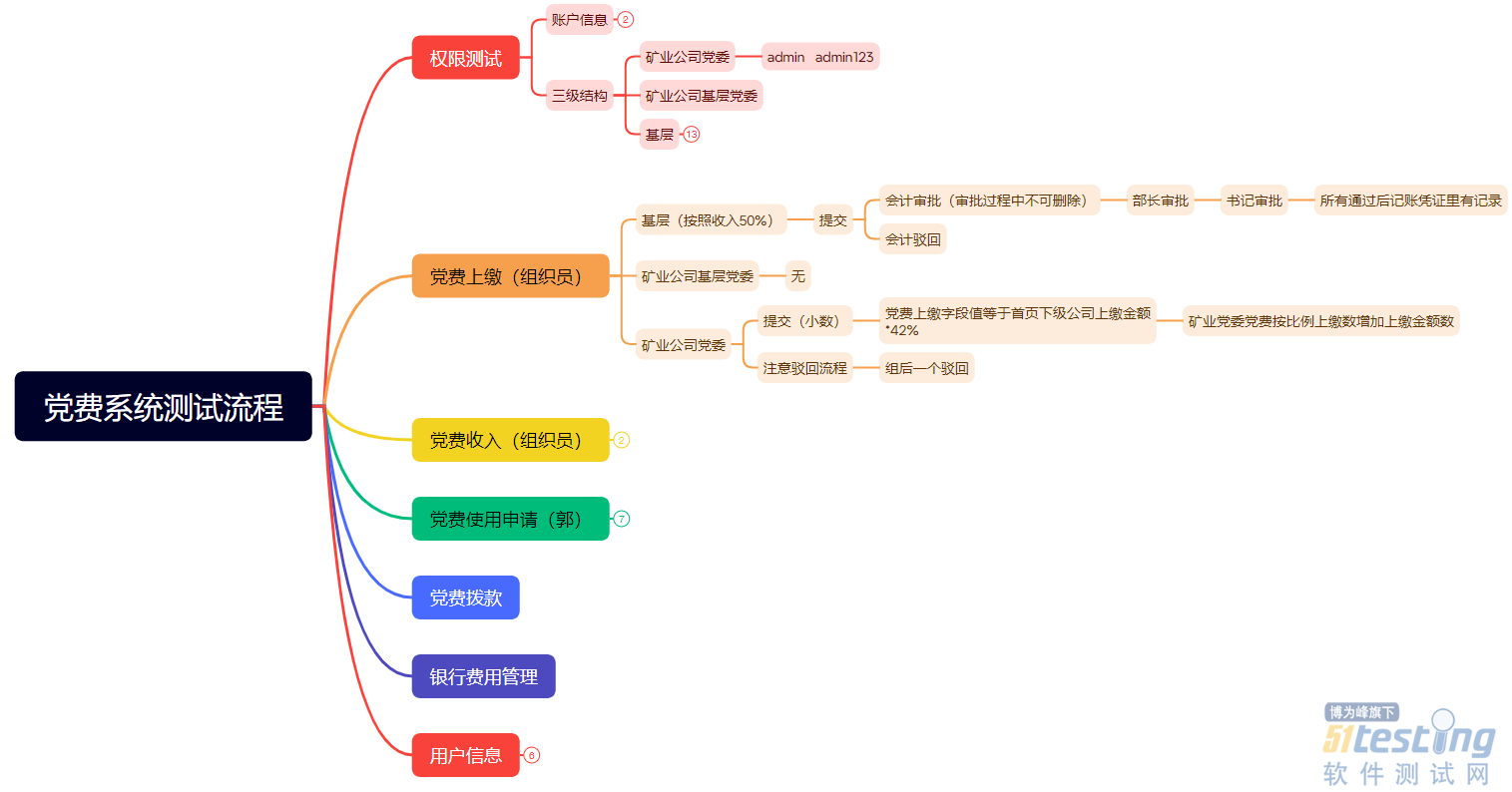
- 背景 最近在测试一个党费系统,项目节点临近,几乎没有测试时间,和PM沟通确认后本次测试主要以找Bug为主,将问题控制在内部,后期再进行用例补充及用例报告编写。这样既能达到给客户一个可控的版本,同时写文档时间也不至于那么紧张。接下来分享下我的应对方案。 内容列表: · 开会熟悉业务 · 常用功能测试 · 业务测试 · 财务业务知识 一 开会熟悉业务 首先我们举行了一次业务分享会议,主要介绍了这是一个党费管理系统,主要包括收入、上缴、支出、拨款、统计等功能及每个功能的主要使用场景,通过这次会议我确定了3个主要关注点,分别为权限测试即3 个类别组织,...
-
- 据业内人士透露,苹果已经包下台积电今年几乎所有3nm制程产能,而且是增强版N3E,或者说第二代3nm。预计芯片将在二季度末试产,三季度量产。N3E相比N5,在同等性能和密度下功耗降低34%、同等功耗和密度下性能提升18%,或者可以将晶体管密度提升60%。 据悉,首先采用这款芯片的将是iPhone 15系列的A17处理器,尽管苹果刚刚遭遇7年来首次iPhone营收下滑,但并未影响推进先进工艺的步伐。另外,苹果用于15寸MacBook Air、iPad Pro/Air的M3处理器也将基于N3E制造。 相比之下,其他两大智能手机芯片厂商高通和联发科,今年的新品依然会停留在4nm。不过,得益于...
-



。第一期的功能,商家用户可以在平台上进行商品的创建,编辑,删除,查询,上下架等操作;运营用户可以审核商家的商品;我们来简单描述...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=145653&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=145653&pic=http://quan.51testing.com/ueditor/php/upload/image/20221201/1669863746389617.png){kind=link}
{kind=link}
{kind=link}
温馨提示
打开微信 扫一扫
温馨提示
设置支付密码
- 关于我们 联系我们 版权声明 广告服务 站长统计
- 建议使用IE 11.0以上浏览器,800×600以上分辨率,法律顾问:上海兰迪律师事务所 项棋律师
- 版权所有 上海博为峰软件技术股份有限公司 Copyright©51testing.com 2003-2024, 沪ICP备05003035号
- 投诉及意见反馈:webmaster@51testing.com; 业务联系:service@51testing.com021-64471599-8017

- 51testing软件测试圈微信