 0
0 1
1


- 当一个数不是数字时:随机测试生成器的好处
摘要:
我们希望在划分我们的测试时,我们将考虑所有的场景,但是太容易忽略不常用的用例。这就是随机测试生成器的好处。我们可能在测试几十个测试用例后感觉很舒适;这些工具能生成几百个。随着更多的东西被扔到墙上,一些有趣的东西更有可能被粘在墙上。
在第一个尝试FsCheck和基于属性的测试后,我恼火了。
Haskell编程语言已经存在一段时间了,然而我从来不用它。吸引我注意的是一个名为QuickCheck的工具和它引进的算法。因为我一直工作在.NET领域,我采选用FsCheck做研究,一个F#端口的QuickCheck。我的恼火来自于演示list集合的属性。
当我们反转一个列表,然后再反转一次,我们希望得到初始列表,对吗?在不考虑这个列表有多长或者包含什么,这个属性应该是真的。想象一下当我第一次用FsCheck测试失败时,我有多么惊讶。第一次带有整数列表的测试通过了,但是当我把它变成持有浮点型时,它失败了。
FSCheck生成随机值填入列表,然后检查属性是否被测试持有。它做了很多很多次测试,为了查找失败的值的组合。在整数的用例中,它不仅仅是我们首先考虑到的1、2、3……,还有会被存储成固定浮点整数、零和负数的最大和最小整数值。我们也需要考虑空列表。FsCheck所有这些都做了。为什么当我考虑浮点数时,它失败了?
解释来自于对浮点值的定义。他们采用一种位的模式,并将该模式解释为一个带有小数点的数字。无论如何,并不是所有可能的比特组合都可以用这种方式进行有意义的解释。我们把这些麻烦的模式NaN定义为:不是一个数。令我惊讶的是,NaN变量可以是逐位相同的,但不相等。让他们明白这一点。这似乎合情合理,但却有违直觉——而且很容易被忽视。
我们希望在设计测试的时候,考虑所有这样的病态情况,但是很容易忽略像NaN这样的东西。这就是像FsCheck这样的随机测试生成器的好处。我们在测试几十个测试用例后可能感觉很舒服。FsCheck生成几百个。随着更多的东西被扔到墙上,一些有趣的东西更有可能粘在墙上。
在FsCheck发现故障之后,它将采取第二步:它试图减少引发问题所需的数据量。我不详细讨论这第二步,因为我的观点是,看到像我刚才用NaN描述的那样的错误有助于我们更深入地思考代码库在做什么——尤其是在将它的测试缩减到最小的形式之后。
在浮点值列表的情况下,我们可能认为NaN业务是假的。我们这样做甚至可能是正确的。但是运行测试的目的是让我们考虑代码库。也许我们应该在系统的边缘添加一些东西来使NaN值出现在系统之外,或者我们应该确保NaN不能从系统内部的任何转换中产生。
我们的代码有缺陷,因为我们对它的思考存在盲点。即使是世界上最大的自动测试用例生成器也会有盲点。令人高兴的是,机器和人类有不同的盲点。
像FsCheck或QuickCheck这样的工具利用了一种不同的测试范例,利用机器的优势来弥补我们的不足。机器可以通过算法制定出大量的测试数据集,这些数据集手工组装起来既昂贵又枯燥。但是他们需要基于属性的测试来消耗所有的数据。
当我还是一名新程序员时,我并不欣赏这一点。我正在研究一个统计应用程序,它严重依赖于贝叶斯统计和概率。有一些事情你可以依靠条件概率。首先,概率总是在0到1之间。另一方面,当我们总结所有条件时,我们应该得到一个。无论我们在代码中添加什么,这些属性是我们可以自动检查的。
同样,我最近与一些朋友进行了一次对话,他们正在构建一个计费系统。我问了一些问题:所有的项目都是正数的吗?我们是否知道许多行项目的小计将超过更少项目的小计?在不考虑求和顺序的情况下,总数是否会发生变化?我问,还有哪些属性是不变的,我们可以断言。每个这样的不变量都可以作为基于属性的测试的基础。跟你打赌,我肯定会给这个系统一些负的价格。
广泛的属性测试可以教会我们很多关于代码库的知识。测试从不确定代码库是无错误的,但是测试确实缩小了错误可以隐藏的范围。为了学得更多,我们必须理解测试的作用和它们所显示的内容。这可能意味着我们应该更多地关注理解我们的测试,而不是仅仅增加少量理解的测试的乘法。就像FsCheck将大型失败测试简化为更简单的表单一样,我们也应该定期检查我们的测试套件。
是否每个测试告诉我们的不仅仅是重现过去几年bug报告的环境?这些测试是否可以重新组织以阐明我们为什么关心它们?我们的目标应该是策划测试,以最大限度地从每个测试的成功或失败中得到理解。
当我对浮点的基于属性的测试失败时,NaN让我感到惊讶。这并不是由于列表倒转的故障;它失败的原因是测试中固有的关于如何比较浮点数的假设。这提醒我们寻找与我们的假设相矛盾的数据。我们在测试中加入的惊喜越多,我们的系统就会变得越健壮。这需要结合多种不同的范例和功能来利用每种范例和功能的优势。
被NaN吓到似乎是个坏消息。它让我们陷入了一个失败的测试,这个测试只与我们正在测试的代码间接相关。但是这样做会让我们想起一些我们可能已经忘记的软件。这样的提醒会把惊喜变成好消息。
本文未经授权禁止转载,如需转载请于51Testing小编联系。
- 0.00 查看剩余0%
- 【留下美好印记】赞赏支持
热门文章
最新讲堂
- 推荐阅读
- 换一换
- 背景技术: 随着IT行业的繁荣,当前的浏览器软件形势极为复杂。有各种类型的浏览器和许多版本,这导致在测试网页时需要进行复杂的兼容性测试。目前正在进行兼容性, 两种测试方法是: 1)一台PC安装了多种型号的浏览器进行测试; 2)多台PC均安装了用于测试的浏览器。 由于自动网页测试将垄断整个过程,并且同一台PC上安装的多个浏览器容易发生环境冲突,因此上述兼容性测试方法1)并不理想,但上述测试方法2)不理想将消耗大量的硬件资源。 技术实现要素: 本发明克服了现有技术的不足,提供了一种浏览器兼容性测试系统和方法,用于解决兼容性测试过程中环境隔离和资源浪费的问题。 考虑到现有技术的上述...

-
- 软件测试的发展与定义08-08读者提问:软件测试行业是如何发展起来的,软件测试的定义是什么呢 ?阿常回答:从软件开发一开始就有软件测试了,起初的软件测试严格来说,不能算作真正的软件测试,是由开发人员完成的 “调试”。1975年《软件数据选择的原理》将软件测试定义为 :“ 证明软件测试工作是正确 ” 的活动,即 “ 证实 ”。1979年《软件测试艺术》将软件测试定义为 :“ 发现错误而执行的活动 ”,即 “ 证伪 ”。1983年《软件测试完全指南》将软件测试定义为:“ 测试是以评价一个程序或者系统属性为目标的任一活动,测试是对软件质量的度量。”,即 “ 预防 ”。2002年《系统的软件测试》将软件测试定义为:“ 测...
- 一、cookie的处理方式 1、准备:两个接口:一个登录、一个充值 2、登录接口 3、充值接口:会失败 4、处理的两种方法 第一种方法,直接添加HTTPCookie管理器,移动到线程组最上面 第二种方法:有的时候Cookie会变,我们就需要,先使用正则表达式提取器获取到cookie(JSESSIONID),再在需要Cookie的接口下添加HTTPCookie管理器(填写名称、值、域、路径)即可 第一种方法 添加:HTTPCookie管理器,放到最上面。 位置: 再次运行:就会充值成功。 第二种方法 1、登录的时候会有set_Cookie存在。 2、添加后置处理器&...

-
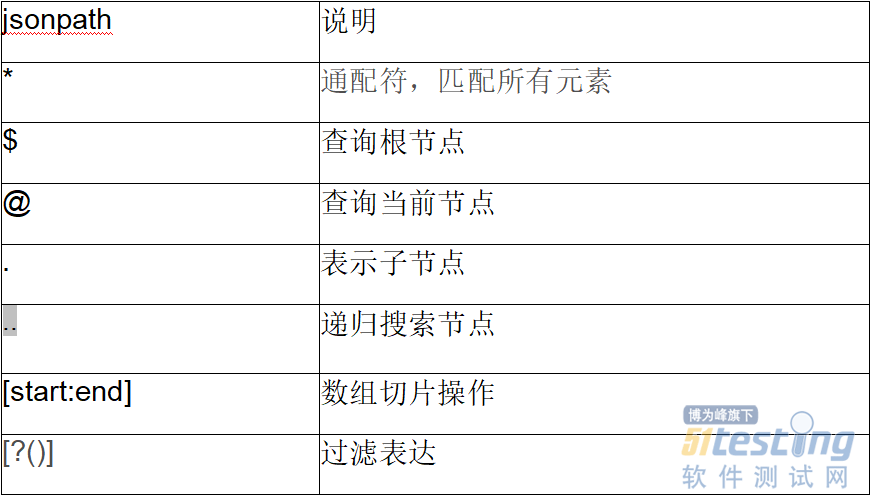
- 摘要:我们在做接口测试时,大多数返回的都是json属性,我们需要通过接口返回的json提取出来对应的值,然后进行做断言或者提取想要的值供下一个接口进行使用。 但是如果返回的json数据嵌套了很多层,通过查找需要的词,就很不方便,小编今天介绍一种python的第3方库jsonpath。 jsonpath jsonpath是使用一种简单的方法来提取给定JSON内容。在我们做接口测试时,目前流行的数据格式就是JSON格式的,当碰到复杂JSON格式时,我们可以使用JsonPath快速提取数据或者更新数据。 安装:pip install jsonpath。 小编先通过正常的接口,获取一段j...
-
- 〇、为什么要讲测试用例设计08-03课程背景大家好,今天,我给大家带来的分享是:《测试工程师需要掌握的核心基础——如何设计测试用例》。随着科技的快速发展,越来越多的信息技术产品进入了我们的生活,给我们的生活带来巨大便利。而这些便利的背后,就是一款款经过测试的软件、硬件产品。我们——测试工程师——作为这些产品的质量守护者,在其中的作用不言而喻。很多次血淋淋的事故都在告诉着我们测试质量的重要性。当年红极一时的FPS游戏「CSonline」因为一个小小的bug,导致游戏最终走向破产;某券商交易系统因为一个小小的bug,致多名客户透支十余亿元……通过这些例子,我们看到了测试的重要性,而如何能让我们我们负责的产品(这里主要指的是软件产品)...



一台PC安装了多种型号的浏览器进行测试; 2)多台PC均安装了用于测试的浏览器。 由于自动网页测试将垄断整个过程,并且同一台PC上安装的多个浏览器容易发生环境冲突,因此上述兼容性测试方法1)并不理想,但上述测试方法2)不理想将消耗大量的硬件资源。 技术实现要素: 本发明克服了现有技术的不足,提供了一种浏览器兼容性测试系统和方法,用于解决兼容性测试过程中环境隔离和资源浪费的问题。 考虑到现有技术的上述...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=144787&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=144787&pic=http://quan.51testing.com/ueditor/php/upload/image/20220610/1654832762796419.gif){kind=link}
,再在需要Cookie的接口下添加HTTPCookie管理器(填写名称、值、域、路径)即可 第一种方法 添加:HTTPCookie管理器,放到最上面。 位置: 再次运行:就会充值成功。 第二种方法 1、登录的时候会有set_Cookie存在。 2、添加后置处理器&...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=146537&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=146537&pic=http://quan.51testing.com/ueditor/php/upload/image/20231012/1697094010620239.png){kind=link}
{kind=link}
- 关于我们 联系我们 版权声明 广告服务 站长统计
- 建议使用IE 11.0以上浏览器,800×600以上分辨率,法律顾问:上海兰迪律师事务所 项棋律师
- 版权所有 上海博为峰软件技术股份有限公司 Copyright©51testing.com 2003-2024, 沪ICP备05003035号
- 投诉及意见反馈:webmaster@51testing.com; 业务联系:service@51testing.com021-64471599-8017

- 51testing软件测试圈微信