 0
0 0
0


- 十年测试大神聊聊什么是基准测试——软件测试圈
基准测试属于性能测试的一种,用于评估和衡量软件的性能指标。我们可以在软件开发的某个阶段通过基准测试建立一个已知的性能水平,称为"基准线"。当系统的软硬件环境发生变化之后再进行一次基准测试以确定那些变化对性能的影响。 这是基准测试最常见的用途。
Donald Knuth在1974年出版的《Structured Programming with go to Statements》提到:
毫无疑问,对效率的片面追求会导致各种滥用。程序员会浪费大量的时间在非关键程序的速度上,实际上这些尝试提升效率的行为反倒可能产生很大的负面影响,特别是当调试和维护的时候。我们不应该过度纠结于细节的优化,应该说约97%的场景:过早的优化是万恶之源。
当然我们也不应该放弃对那关键3%的优化。一个好的程序员不会因为这个比例小就裹足不前,他们会明智地观察和识别哪些是关键的代码;但是仅当关键代码已经被确认的前提下才会进行优化。对于很多程序员来说,判断哪部分是关键的性能瓶颈,是很容易犯经验上的错误的,因此一般应该借助测量工具来证明。
虽然经常被解读为不需要关心性能,但是的少部分情况下(3%)应该观察和识别关键代码并进行优化。
基准(benchmarking)测试工具
python中提供了非常多的工具来进行基准测试。
为了使演示的例子稍微有趣,我们来随机生成一个列表,并对列表中数字进行排序。
import random def random_list(start, end, length): """ 生成随机列表 :param start: 随机开始数 :param end: 随机结束数 :param length: 列表长度 """ data_list = [] for i in range(length): data_list.append(random.randint(start, end)) return data_list def bubble_sort(arr): """ 冒泡排序: 对列表进行排序 :param arr 列表 """ n = len(arr) for i in range(n): for j in range(0, n - i - 1): if arr[j] > arr[j + 1]: arr[j], arr[j + 1] = arr[j + 1], arr[j] return arr if __name__ == '__main__': get_data_list = random_list(1, 99, 10) ret = bubble_sort(get_data_list) print(ret)
运行结果如下:
python .\demo.py [8, 16, 22, 31, 42, 58, 66, 71, 73, 91]
timeit
timeit是python自带的模块,用来进行基准测试非常方便。
if __name__ == '__main__':
import timeit
get_data_list = random_list(1, 99, 10)
setup = "from __main__ import bubble_sort"
t = timeit.timeit(
stmt="bubble_sort({})".format(get_data_list),
setup=setup
)
print(t)运行结果:
python .\demo.py 5.4201355
以测试bubble_sort()函数为例。timeit.timeit() 参数说明。
· stmt:需要测试的函数或语句,字符串形式.
· setup: 运行的环境,本例子中表示if __name__ == '__main__':.
· number: 执行的次数,省缺则默认是1000000次。所以你会看到运行bubble_sort() 耗时 5秒多。
pyperf
pyperf 的用法与timeit比较类似,但它提供了更丰富结果。(注:我完全是发现了这个库才学习基准测试的)
if __name__ == '__main__':
get_data_list = random_list(1, 99, 10)
import pyperf
setup = "from __main__ import bubble_sort"
runner = pyperf.Runner()
runner.timeit(name="bubble sort",
stmt="bubble_sort({})".format(get_data_list),
setup=setup)运行结果:
python .\demo.py -o bench.json ..................... bubble sort: Mean +- std dev: 5.63 us +- 0.31 us
测试结果会写入bench.json 文件。可以使用pyperf stats命令分析测试结果。
python -m pyperf stats bench.json Total duration: 15.9 sec Start date: 2021-04-02 00:17:18 End date: 2021-04-02 00:17:36 Raw value minimum: 162 ms Raw value maximum: 210 ms Number of calibration run: 1 Number of run with values: 20 Total number of run: 21 Number of warmup per run: 1 Number of value per run: 3 Loop iterations per value: 2^15 Total number of values: 60 Minimum: 4.94 us Median +- MAD: 5.63 us +- 0.12 us Mean +- std dev: 5.63 us +- 0.31 us Maximum: 6.41 us 0th percentile: 4.94 us (-12% of the mean) -- minimum 5th percentile: 5.10 us (-9% of the mean) 25th percentile: 5.52 us (-2% of the mean) -- Q1 50th percentile: 5.63 us (+0% of the mean) -- median 75th percentile: 5.81 us (+3% of the mean) -- Q3 95th percentile: 5.95 us (+6% of the mean) 100th percentile: 6.41 us (+14% of the mean) -- maximum Number of outlier (out of 5.07 us..6.25 us): 6
pytest-benchmark
pytest-benchmark是 pytest单元测试框架的一个插件。 单独编写单元测试用例:
from demo import bubble_sort def test_bubble_sort(benchmark): test_list = [5, 2, 4, 1, 3] result = benchmark(bubble_sort, test_list) assert result == [1, 2, 3, 4, 5]
需要注意:
1. 导入bubble_sort() 函数。
2. benchmark 作为钩子函数使用,不需要导入包。前提是你需要安装pytest和pytest-benchmark。
3. 为了方便断言,我们就把要排序的数固定下来了。
运行测试用例:
pytest -q .\test_demo.py . [100%] ------------------------------------------------ benchmark: 1 tests ----------------------------------------------- Name (time in us) Min Max Mean StdDev Median IQR Outliers OPS (Kops/s) Rounds Iterations ------------------------------------------------------------------------------------------------------------------- test_bubble_sort 1.6000 483.2000 1.7647 2.6667 1.7000 0.0000 174;36496 566.6715 181819 1 ------------------------------------------------------------------------------------------------------------------- Legend: Outliers: 1 Standard Deviation from Mean; 1.5 IQR (InterQuartile Range) from 1st Quartile and 3rd Quartile. OPS: Operations Per Second, computed as 1 / Mean 1 passed in 1.98s
加上 --benchmark-histogram 参数,你会得到一张图表:
pytest -q .\test_demo.py --benchmark-histogram . [100%] ------------------------------------------------ benchmark: 1 tests ----------------------------------------------- Name (time in us) Min Max Mean StdDev Median IQR Outliers OPS (Kops/s) Rounds Iterations ------------------------------------------------------------------------------------------------------------------- test_bubble_sort 1.6000 53.9000 1.7333 0.3685 1.7000 0.0000 1640;37296 576.9264 178572 1 ------------------------------------------------------------------------------------------------------------------- Generated histogram: D:\github\test-circle\article\code\benchmark_20210401_165958.svg
图片如下:

作者:虫师
- -1.00 查看剩余0%
- 【留下美好印记】赞赏支持

热门文章
最新讲堂
- 推荐阅读
- 换一换
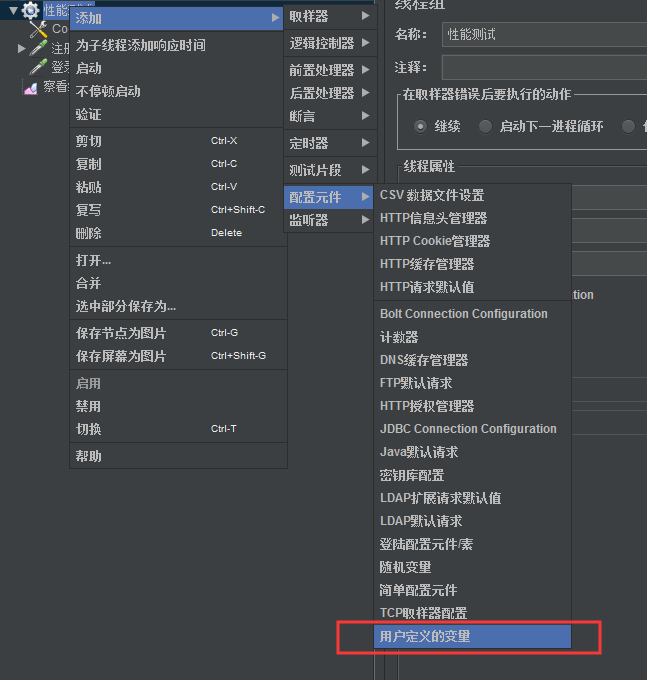
- 1、用户定义的变量 当我们每次去调用接口都要手动修改手机号码,并且注册和登录接口都要同步修改,这样操作相当繁琐,针对这个问题我们使用用户定义的变量的工具进行优化。 添加:在线程组上:右键—>添加—>配置元件—>用户定义的变量 用户自定义变量是固定的,与下面的“用户参数”有点不同(比如:${__Random(1000,9999,)},多个虚拟用户请求时,生成的四位数都是固定同一个) 我们把注册和登录的手机号和密码都提取出来放到这里。 定义了之后,我们需要调用该参数,调用方式是在对应的取样器里,使用${key}的格式替换取样器请求体里的值,这样我们就可以每次只修改一...
-
- 【测试设计】如何评估版本修改范围07-28作为测试人员,日常最频繁的活动便是对修改进行验证,不管是新功能增加还是bug修改都会动代码,有的代码修改不单单只影响当前功能,为了确保验证全面,不会出现遗留问题,在测试之前,需要对修改进行评估,确认修改范围。修改范围可通过如下两种方式判断:1、产品的需求原型文档其实产品需求文档属于明面上的一些可圈可点的,可以获得依据的地方,他可以明确告诉你修改哪些页面和哪些功能,只需要按照需求原型把测试点细化即可。2、转测文件中,开发给出的测试建议在版本转测的时候,开发也应该在转测文件中指出修改影响的范围和测试建议,测试人员需要把这些涉及点纳入测试设计中,如果还有不明白的地方需要及时找对应的开发人员进行沟通,...

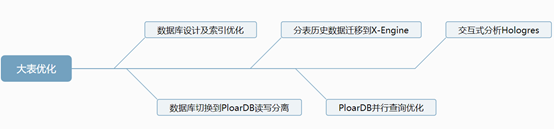
- MySQL大表优化方案——软件测试圈01-20背景 阿里云RDS FOR MySQL(MySQL5.7版本)数据库业务表每月新增数据量超过千万,随着数据量持续增加,我们业务出现大表慢查询,在业务高峰期主业务表的慢查询需要几十秒严重影响业务方案概述一、数据库设计及索引优化 MySQL数据库本身高度灵活,造成性能不足,严重依赖开发人员的表设计能力以及索引优化能力,在这里给几点优化建议时间类型转化为时间戳格式,用int类型储存,建索引增加查询效率建议字段定义not null,null值很难查询优化且占用额外的索引空间使用TINYINT类型代替...
- MySQL数据增删改和基本查询——软件测试圈09-09一、DMLDML是Data Manipulation Language英文缩写,数据操作语言包括:INSERT ( 添加语句 )UPDATE ( 更新语句 )DELETE ( 删除语句 )1、INSERT语法:INSERT [INTO] 表名 [(列名)] VALUES (值列表);实例:INSERT INTO goods (name) VALUES ('饼干');1.1 插入单行数据注意:字段名是可选的,如省略依次插入所有字段。INSERT INTO goods VALUES (8,'肥皂',DEFAULT,'2...
- 淘宝秒杀系统内幕——软件测试圈06-09导读:最初的秒杀系统的原型是淘宝详情上的定时上架功能,由于有些卖家为了吸引眼球,把价格压得很低。但这给的详情系统带来了很大压力,为了将这种突发流量隔离,才设计了秒杀系统,文章主要介绍大秒系统以及这种典型读数据的热点问题的解决思路和实践经验。一些数据大家还记得2013年的小米秒杀吗?三款小米手机各11万台开卖,走的都是大秒系统,3分钟后成为双十一第一家也是最快破亿的旗舰店。经过日志统计,前端系统双11峰值有效请求约60w以上的QPS,而后端cache的集群峰值近2000w/s、单机也近30w/s,但到真正的写时流量要小很多了,当时最高下单减库存tps是红米创造,达到1500/s。热点隔离秒杀系统...


},多个虚拟用户请求时,生成的四位数都是固定同一个) 我们把注册和登录的手机号和密码都提取出来放到这里。 定义了之后,我们需要调用该参数,调用方式是在对应的取样器里,使用${key}的格式替换取样器请求体里的值,这样我们就可以每次只修改一...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=146633&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=146633&pic=http://quan.51testing.com/ueditor/php/upload/image/20231127/1701075677287393.png){kind=link}
{kind=link}
数据库业务表每月新增数据量超过千万,随着数据量持续增加,我们业务出现大表慢查询,在业务高峰期主业务表的慢查询需要几十秒严重影响业务方案概述一、数据库设计及索引优化 MySQL数据库本身高度灵活,造成性能不足,严重依赖开发人员的表设计能力以及索引优化能力,在这里给几点优化建议时间类型转化为时间戳格式,用int类型储存,建索引增加查询效率建议字段定义not null,null值很难查询优化且占用额外的索引空间使用TINYINT类型代替...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=1348&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=1348&pic=http://quan.51testing.com/ueditor/php/upload/image/20210120/1611107682537409.png){kind=link}
UPDATE ( 更新语句 )DELETE ( 删除语句 )1、INSERT语法:INSERT [INTO] 表名 [(列名)] VALUES (值列表);实例:INSERT INTO goods (name) VALUES ('饼干');1.1 插入单行数据注意:字段名是可选的,如省略依次插入所有字段。INSERT INTO goods VALUES (8,'肥皂',DEFAULT,'2...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=144083&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=144083&pic=http://quan.51testing.com/ueditor/php/upload/image/20210909/1631164600956365.jpg){kind=link}
{kind=link}
- 关于我们 联系我们 版权声明 广告服务 站长统计
- 建议使用IE 11.0以上浏览器,800×600以上分辨率,法律顾问:上海兰迪律师事务所 项棋律师
- 版权所有 上海博为峰软件技术股份有限公司 Copyright©51testing.com 2003-2024, 沪ICP备05003035号
- 投诉及意见反馈:webmaster@51testing.com; 业务联系:service@51testing.com021-64471599-8017

- 51testing软件测试圈微信