 0
0 0
0


- Java 中 N+1 问题的集成测试——软件测试圈
N+1问题:N+1问题是指在使用关系型数据库时,在获取一组对象及其关联对象时,产生额外的数据库查询的问题。其中N表示要获取的主对象的数量,而在获取每个主对象的关联对象时,会产生额外的1次查询。
N+1问题是很多项目中的通病。遗憾的是,直到数据量变得庞大时,我们才注意到它。不幸的是,当处理 N + 1 问题成为一项难以承受的任务时,代码可能会达到了一定规模。
在这篇文章中,我们将开始关注以下几点问题:
N + 1 问题的一个例子
假设我们正在开发管理动物园的应用程序。在这种情况下,有两个核心实体:Zoo和Animal。请看下面的代码片段:
@Entity
@Table(name = "zoo")
public class Zoo {
@Id
@GeneratedValue(strategy = IDENTITY)
private Long id;
private String name;
@OneToMany(mappedBy = "zoo", cascade = PERSIST)
private List<Animal> animals = new ArrayList<>();
}
@Entity
@Table(name = "animal")
public class Animal {
@Id
@GeneratedValue(strategy = IDENTITY)
private Long id;
@ManyToOne(fetch = LAZY)
@JoinColumn(name = "zoo_id")
private Zoo zoo;
private String name;
}现在我们想要检索所有现有的动物园及其动物。看看ZooService下面的代码。
@Service
@RequiredArgsConstructor
public class ZooService {
private final ZooRepository zooRepository;
@Transactional(readOnly = true)
public List<ZooResponse> findAllZoos() {
final var zoos = zooRepository.findAll();
return zoos.stream()
.map(ZooResponse::new)
.toList();
}
}此外,我们要检查一切是否顺利进行。简单的集成测试:
@DataJpaTest
@AutoConfigureTestDatabase(replace = NONE)
@Transactional(propagation = NOT_SUPPORTED)
@Testcontainers
@Import(ZooService.class
class ZooServiceTest {
@Container
static final PostgreSQLContainer<?> POSTGRES = new PostgreSQLContainer<>("postgres:13");
@DynamicPropertySource
static void setProperties(DynamicPropertyRegistry registry) {
registry.add("spring.datasource.url", POSTGRES::getJdbcUrl);
registry.add("spring.datasource.username", POSTGRES::getUsername);
registry.add("spring.datasource.password", POSTGRES::getPassword);
}
@Autowired
private ZooService zooService;
@Autowired
private ZooRepository zooRepository;
@Test
void shouldReturnAllZoos() {
/* data initialization... */
zooRepository.saveAll(List.of(zoo1, zoo2));
final var allZoos = assertQueryCount(
() -> zooService.findAllZoos(),
ofSelects(1)
);
/* assertions... */
assertThat(
...
);
}
}测试成功通过。但是,如果记录 SQL 语句,会注意到以下几点:
-- selecting all zoos
select z1_0.id,z1_0.name from zoo z1_0
-- selecting animals for the first zoo
select a1_0.zoo_id,a1_0.id,a1_0.name from animal a1_0 where a1_0.zoo_id=?
-- selecting animals for the second zoo
select a1_0.zoo_id,a1_0.id,a1_0.name from animal a1_0 where a1_0.zoo_id=?
如所见,我们select对每个 present 都有一个单独的查询Zoo。查询总数等于所选动物园的数量+1。因此,这是N+1问题。
这可能会导致严重的性能损失。尤其是在大规模数据上。
自动跟踪 N+1 问题
当然,我们可以自行运行测试、查看日志和计算查询次数,以确定可行的性能问题。无论如何,这效率很低。。
有一个非常高效的库,叫做datasource-proxy。它提供了一个方便的 API 来javax.sql.DataSource使用包含特定逻辑的代理来包装接口。例如,我们可以注册在查询执行之前和之后调用的回调。该库还包含开箱即用的解决方案来计算已执行的查询。我们将对其进行一些改动以满足我们的需要。
查询计数服务
首先,将库添加到依赖项中:
implementation "net.ttddyy:datasource-proxy:1.8"
现在创建QueryCountService. 它是保存当前已执行查询计数并允许您清理它的单例。请看下面的代码片段。
@UtilityClass
public class QueryCountService {
static final SingleQueryCountHolder QUERY_COUNT_HOLDER = new SingleQueryCountHolder();
public static void clear() {
final var map = QUERY_COUNT_HOLDER.getQueryCountMap();
map.putIfAbsent(keyName(map), new QueryCount());
}
public static QueryCount get() {
final var map = QUERY_COUNT_HOLDER.getQueryCountMap();
return ofNullable(map.get(keyName(map))).orElseThrow();
}
private static String keyName(Map<String, QueryCount> map) {
if (map.size() == 1) {
return map.entrySet()
.stream()
.findFirst()
.orElseThrow()
.getKey();
}
throw new IllegalArgumentException("Query counts map should consists of one key: " + map);
}
}在那种情况下,我们假设_DataSource_我们的应用程序中有一个。这就是_keyName_函数否则会抛出异常的原因。但是,代码不会因使用多个数据源而有太大差异。
将SingleQueryCountHolder所有QueryCount对象存储在常规ConcurrentHashMap.
相反,_ThreadQueryCountHolder_将值存储在_ThreadLocal_对象中。但是_SingleQueryCountHolder_对于我们的情况来说已经足够了。
API 提供了两种方法。该get方法返回当前执行的查询数量,同时clear将计数设置为零。
BeanPostProccessor 和 DataSource 代理
现在我们需要注册QueryCountService以使其从 收集数据DataSource。在这种情况下,BeanPostProcessor 接口就派上用场了。请看下面的代码示例。
@TestComponent
public class DatasourceProxyBeanPostProcessor implements BeanPostProcessor {
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) {
if (bean instanceof DataSource dataSource) {
return ProxyDataSourceBuilder.create(dataSource)
.countQuery(QUERY_COUNT_HOLDER)
.build();
}
return bean;
}
}我用注释标记类_@TestComponent_并将其放入_src/test_目录,因为我不需要对测试范围之外的查询进行计数。
如您所见,这个想法很简单。如果一个 bean 是DataSource,则将其包裹起来ProxyDataSourceBuilder并将QUERY_COUNT_HOLDER值作为QueryCountStrategy.
最后,我们要断言特定方法的已执行查询量。看看下面的代码实现:
@UtilityClass
public class QueryCountAssertions {
@SneakyThrows
public static <T> T assertQueryCount(Supplier<T> supplier, Expectation expectation) {
QueryCountService.clear();
final var result = supplier.get();
final var queryCount = QueryCountService.get();
assertAll(
() -> {
if (expectation.selects >= 0) {
assertEquals(expectation.selects, queryCount.getSelect(), "Unexpected selects count");
}
},
() -> {
if (expectation.inserts >= 0) {
assertEquals(expectation.inserts, queryCount.getInsert(), "Unexpected inserts count");
}
},
() -> {
if (expectation.deletes >= 0) {
assertEquals(expectation.deletes, queryCount.getDelete(), "Unexpected deletes count");
}
},
() -> {
if (expectation.updates >= 0) {
assertEquals(expectation.updates, queryCount.getUpdate(), "Unexpected updates count");
}
}
);
return result;
}
}该代码很简单:
1. 将当前查询计数设置为零。
2. 执行提供的 lambda。
3. 将查询计数给定的Expectation对象。
4. 如果一切顺利,返回执行结果。
此外,您还注意到了一个附加条件。如果提供的计数类型小于零,则跳过断言。不关心其他查询计数时,这很方便。
该类Expectation只是一个常规数据结构。看下面它的声明:
@With
@AllArgsConstructor
@NoArgsConstructor
public static class Expectation {
private int selects = -1;
private int inserts = -1;
private int deletes = -1;
private int updates = -1;
public static Expectation ofSelects(int selects) {
return new Expectation().withSelects(selects);
}
public static Expectation ofInserts(int inserts) {
return new Expectation().withInserts(inserts);
}
public static Expectation ofDeletes(int deletes) {
return new Expectation().withDeletes(deletes);
}
public static Expectation ofUpdates(int updates) {
return new Expectation().withUpdates(updates);
}
}最后的例子
让我们看看它是如何工作的。首先,我在之前的 N+1 问题案例中添加了查询断言。看下面的代码块:
final var allZoos = assertQueryCount( () -> zooService.findAllZoos(), ofSelects(1) );
不要忘记
_DatasourceProxyBeanPostProcessor_在测试中作为 Spring bean 导入。
如果我们重新运行测试,我们将得到下面的输出。
Multiple Failures (1 failure) org.opentest4j.AssertionFailedError: Unexpected selects count ==> expected: <1> but was: <3> Expected :1 Actual :3
所以,确实有效。我们设法自动跟踪 N+1 问题。是时候用 替换常规选择了JOIN FETCH。请看下面的代码片段。
public interface ZooRepository extends JpaRepository<Zoo, Long> {
@Query("FROM Zoo z LEFT JOIN FETCH z.animals")
List<Zoo> findAllWithAnimalsJoined();
}
@Service
@RequiredArgsConstructor
public class ZooService {
private final ZooRepository zooRepository;
@Transactional(readOnly = true)
public List<ZooResponse> findAllZoos() {
final var zoos = zooRepository.findAllWithAnimalsJoined();
return zoos.stream()
.map(ZooResponse::new)
.toList();
}
}让我们再次运行测试并查看结果:

这意味着正确地跟踪了 N + 1 个问题。此外,如果查询数量等于预期数量,则它会成功通过。
结论
事实上,定期测试可以防止 N+1 问题。这是一个很好的机会,可以保护那些对性能至关重要的代码部分。
作者:MobotStone
- -1.00 查看剩余0%
- 【留下美好印记】赞赏支持

热门文章
最新讲堂
- 推荐阅读
- 换一换
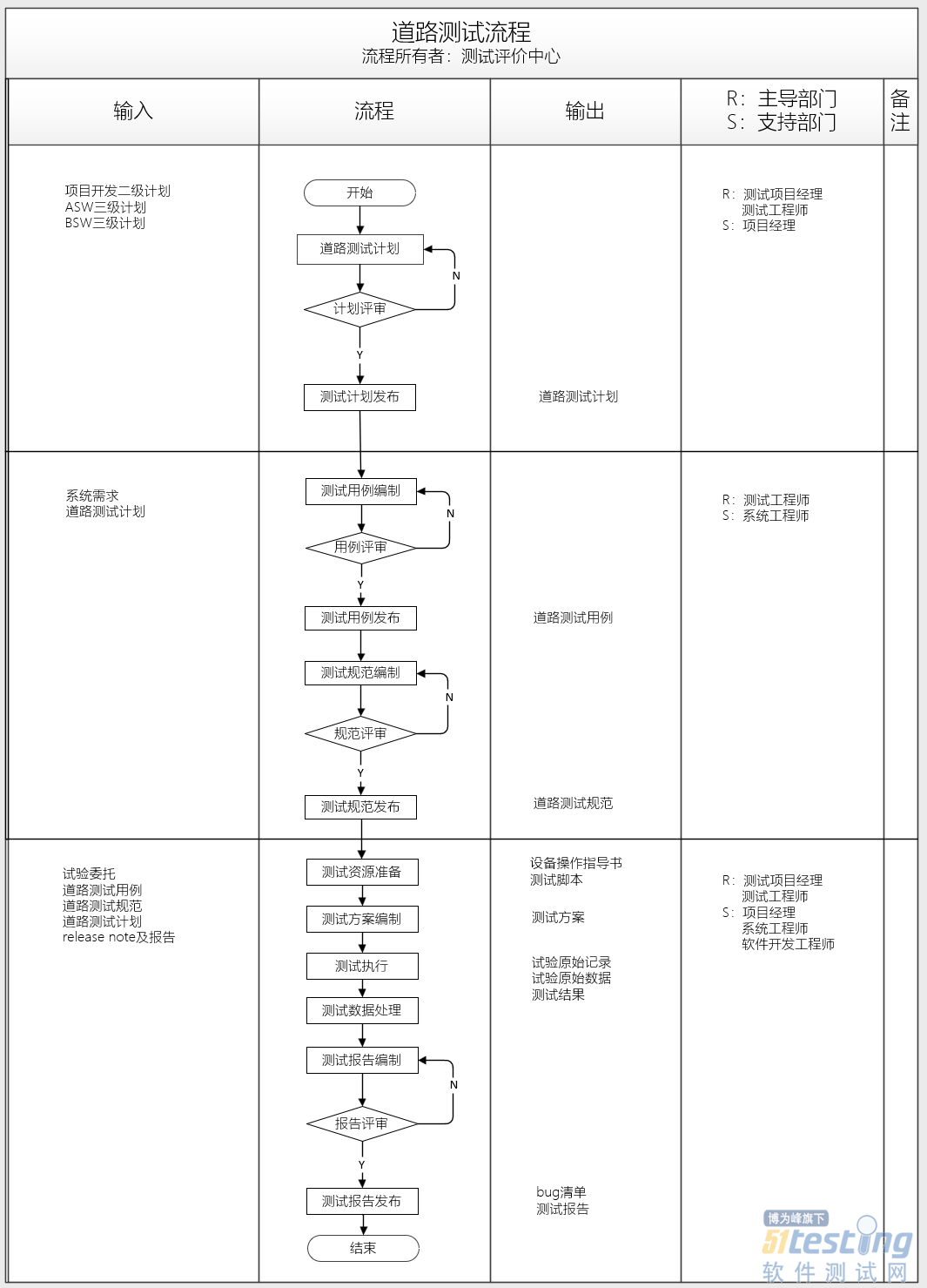
- 1.道路测试流程 测试场地 1.测试场地有哪些? 对于一些要求不太高/简单的测试场景可以找一些封闭的场地,如断头路或者是城市所在地当地政府提供的诸如智能网联专用道路之类的测试道路,对于复杂或相对要求高一些的测试场景可以到专业的国家智能网联汽车试点测试场进行测试,以下提供了国内常用的示范区: ①国家智能网联汽车(上海)试点示范区封闭测试区 ②国家智能商用车检验检测(泰兴)基地 ③中汽中心(盐城)汽车试验场 ④国家智能交通综合测试基地(无锡) ⑤浙江5G车联网应用示范区(杭州云栖小镇&桐乡乌镇) ⑥中汽中心智能网联汽车测试(北京)基地 ⑦中国汽研智能网联汽车(重庆)...
-
- 软件测试工程师必知必会!——软件测试圈08-18一、等待的作用等待的作用在实际自动化实现过程中,都会添加等待来完善自动化测试的代码。自动化测试,是交由机器来执行的一种测试手段,用于提升测试效率,意味着每一次的自动化测试都 需要有非常高的成功率,才可以达到提升效率的作用。在自动化测试中,其实就是通过代码,来执行测试的流程,也就意味着机器知己对页面元素来进行操 作,如果说因为页面加载速度过慢,导致元素无法被第一时间找到,则报错,停止本次自动化测试, 通过添加等待的方法,让代码在运行时,会进行等待页面加载的操作,以便于更好的进行元素查找。我们平常用到的有三种等待方式:强制等待隐式等待显示等待二、三种等待方式1:强制等待第一种也是使用最简单的一种办...
- 需求评审对于一个测试人员有多重要!——软件测试圈08-25我们都知道对于测试人员来说最重要的两个评审会议是需求评审和用例评审。需求评审需求会议评审的最根本有以下几个目的:第一,评审需求中产品设计的功能中有问题的地方,和没有量化的地方,比如功能设计的字段的类型和限制长度,规则等等。第二,评审需求中有问题的地方我们肯定都要推动产品进行修改最终达成一致。第三,我强调为什么要量化,只有量化之后,测试才能后期的用例编写,开发才能进行一些程序设计包括数据库设计。什么是量化?我举个简单的例子:比如某软件登录是手机号登录,产品设计的文档中写的是输入规范的手机号。这句话就是有问题的,没办法量化,什么是规范的手机号?如果说手机号为首位为1,11位数字,这样的需求才是没问...
- 前一段时间“24届秋招”一度刷屏,招聘信息显示各大厂都在疯狂的招人。 · 京东发布题为“京东为在校学生提供超1.5万个岗位”的消息。 · 美团预计招募6000人,覆盖技术、产品、商业分析、运营、金融、供应链、职能、市场营销、设计、销售、客服和支持等10大类职位、100余种岗位。 · 腾讯今年的校招覆盖北上广深成等多个城市。 · 阿里巴巴单一个淘天就招2000人,从年龄来看,这次招聘面向的毕业生将以00后为主。 根据一些行业的观察和预测,随着国内经济的恢复,实体经济和线下消费回暖,招聘需求也在增多。虽然就业形势依旧严峻,但薪资水平...

-
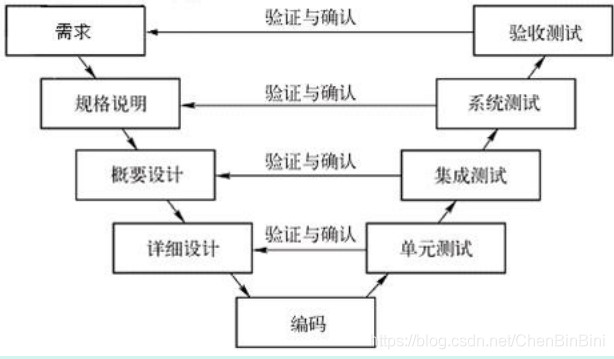
- 软件测试基础知识10-151、单元、集成、系统、验收、回归测试介绍答:单元测试:完成最小的软件设计单元(模块)的验证工作,目标是确保模块被正确的编码,使用过程设计描述作为指南,对重要的控制路径进行测试以发现模块内的错误,通常情况下是白盒的,对代码风格和规则、程序设计和结构、业务逻辑等进行静态测试,及早的发现和解决不易显现的错误。集成测试:通过测试发现与模块接口有关的问题。目标是把通过了单元测试的模块拿来,构造一个在设计中所描述的程序结构,应当避免一次性的集成(除非软件规模很小),而采用增量集成。自顶向下集成:模块集成的顺序是首先集成主模块,然后按照控制层次结构向下进行集成,隶属于主模块的模块按照深度优先或广度优先的方式...


试点示范区封闭测试区 ②国家智能商用车检验检测(泰兴)基地 ③中汽中心(盐城)汽车试验场 ④国家智能交通综合测试基地(无锡) ⑤浙江5G车联网应用示范区(杭州云栖小镇&桐乡乌镇) ⑥中汽中心智能网联汽车测试(北京)基地 ⑦中国汽研智能网联汽车(重庆)...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=146350&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=146350&pic=http://quan.51testing.com/ueditor/php/upload/image/20230717/1689583390152883.png){kind=link}
{kind=link}
{kind=link}
{kind=link}
的验证工作,目标是确保模块被正确的编码,使用过程设计描述作为指南,对重要的控制路径进行测试以发现模块内的错误,通常情况下是白盒的,对代码风格和规则、程序设计和结构、业务逻辑等进行静态测试,及早的发现和解决不易显现的错误。集成测试:通过测试发现与模块接口有关的问题。目标是把通过了单元测试的模块拿来,构造一个在设计中所描述的程序结构,应当避免一次性的集成(除非软件规模很小),而采用增量集成。自顶向下集成:模块集成的顺序是首先集成主模块,然后按照控制层次结构向下进行集成,隶属于主模块的模块按照深度优先或广度优先的方式...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=801&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=801&pic=http://quan.51testing.com/ueditor/php/upload/image/20201015/1602747865548343.png){kind=link}
- 关于我们 联系我们 版权声明 广告服务 站长统计
- 建议使用IE 11.0以上浏览器,800×600以上分辨率,法律顾问:上海兰迪律师事务所 项棋律师
- 版权所有 上海博为峰软件技术股份有限公司 Copyright©51testing.com 2003-2024, 沪ICP备05003035号
- 投诉及意见反馈:webmaster@51testing.com; 业务联系:service@51testing.com021-64471599-8017

- 51testing软件测试圈微信