 0
0 0
0
分享


- OpenAI 的 GPT-4o 道德推理能力胜过人类专家——软件测试圈
近期的一项研究表明,OpenAI 最新的聊天机器人 GPT-4o 能够提供道德方面的解释和建议,且质量优于“公认的”道德专家所提供的建议。
据 The Decoder 当地时间周六报道,美国北卡罗莱纳大学教堂山分校和艾伦 AI 研究所的研究人员进行了两项研究,将 GPT 模型与人类的道德推理能力进行比较,以探讨大语言模型是否可被视为“道德专家”。
汇总研究内容如下:
研究一
501 名美国成年人对比了 GPT-3.5-turbo 模型和其他人类参与者的道德解释。结果表明,人们认为 GPT 的解释比人类参与者的解释更符合道德、更值得信赖、更周到。
评估者也认为人工智能的评估比其他人更可靠。虽然差异很小,但关键发现是 AI 可以匹配甚至超越人类水平的道德推理。

研究二
将 OpenAI 最新的 GPT-4o 模型生成的建议与《纽约时报》“伦理学家”专栏中著名伦理学家 Kwame Anthony Appiah 的建议进行了比较。900 名参与者对 50 个“伦理困境”的建议质量进行了评分。
结果表明,GPT-4o 在“几乎每个方面”都胜过人类专家。人们认为 AI 生成的建议在道德上更正确、更值得信赖、更周到、更准确。只有在感知细微差别方面,人工智能和人类专家之间没有显著差异。

研究人员认为,这些结果表明 AI 可以通过“比较道德图灵测试”(cMTT)。而文本分析显示,GPT-4o 在提供建议时使用的道德和积极语言比人类专家更多。这可以部分解释为什么 AI 的建议评分更高 —— 但不是唯一因素。
需要注意的是,这项研究仅仅针对美国参与者进行,后续仍需进一步研究人们如何看待 AI 生成的道德推理的文化差异。
作者:清源
原文链接:IT之家(ithome.com)
- -1.00 查看剩余0%
- 【留下美好印记】赞赏支持
登录 后发表评论
恬恬圈51Testing测试圈官方编辑
+ 关注
热门文章
最新讲堂
温馨提示
- 推荐阅读
- 换一换
- 从普通测试到测试管理岗的四个习惯——软件测试圈01-06总结和整理 很多同学会觉得,我平时也就根据业务需求啊,做完一个接着一个,哪有什么好总结的。或者是,需求分析、测试设计、性能测试就是这样做的啊,大家都清楚,哪有什么好分享的。对测试工程师来说,总结和整理很重要。不论是大项目还是小需求,项目中踩坑地点、某个公共的测试方法、业务流程、甚至是一个棘手问题的解决过程等都可以记录下来。对自己而言,通过总结大家能发现自己做的好和做的不好的点,加深印象,了解自己的知识体系,对不足之处制定改进计划并定期跟进,才能不断进步;对他人而言,学习他人的经验也是一种成长的方式,同时避免下次有同学踩同样的坑;对公司而言,有详细的业务和技术文档可以降低大家的学习成本和犯...
- 微信小程序之直播功能使用详解——软件测试圈02-19前言小程序直播功能,分为使用官方自带的直播组件( live-player-plugin ,无需二次开发,开箱即用),另一种就是使用自己服务器的流,自定义直播组件(live-player、live-pusher),这里主要讲述,第一种的使用一、准备第一要了解是否满足 直播开通条件基本满足开头直播条件的功能里会有直播,然后去申请开通一下就行了创建直播间这个直播码就是主播开启直播的入口,主播扫码就可以进入基本信息点击后选择手机直播推流直播创建时需要核实身份 同时开播时间必须在12小时内 第一次开通需要人脸识别验证样式配置二、开发使用引入插件原生引入在app.jison1. 主包引入 &nb...

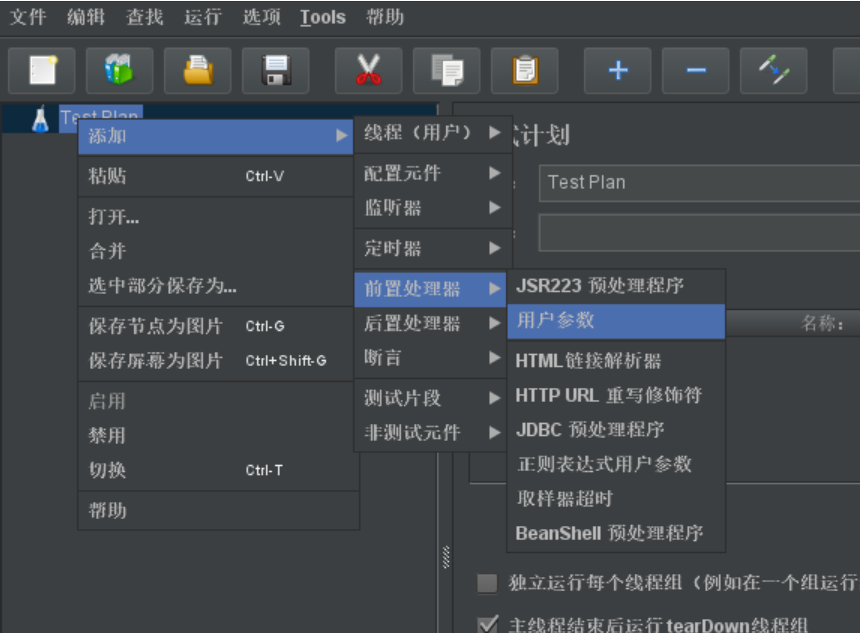
- 参数化概念 测试工作中,通常会使用不同的数据发送请求测试不同的场景来实现测试的全面性,这就需要对一些字段进行参数化,以使每次迭代都使用不同的数据来满足我们的测试需求。 Jmeter做为常用的功能、性能测试工具之一,其参数化方式也是相对比较灵活,主要分为4种:用户参数、用户自定义变量、CSV数据文件、函数助手,下面将详细介绍这4种参数化方式的使用方法。 参数化方式 一、用户参数 1.使用场景 适用于参数取值范围很小的场景,例如测试模拟较少用户登陆某系统交易。 2.操作步骤 (1)添加用户参数功能模块 (2)设置参数变量、用户值 注意勾选每次迭代更新一次,否则每次都使用同样...
-
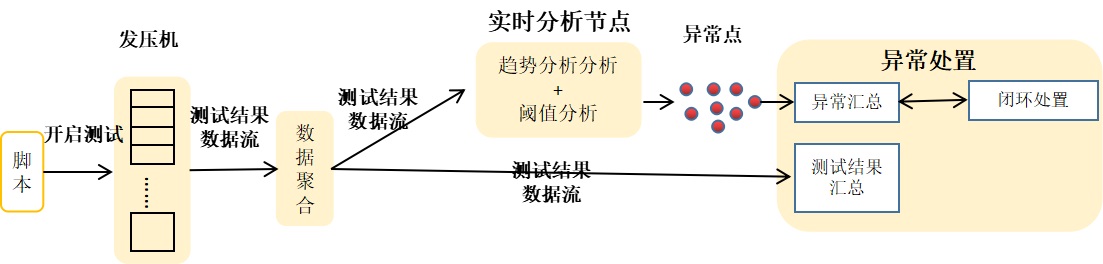
- 性能压测是一种评估系统运行效率和稳定性的方法,通过模拟真实的使用场景和负载条件,对系统进行压力测试和负载测试,并对测试结果进行分析,以评估系统的性能,其中性能压测结果分析是性能压测的重要环节。以往的性能压测,测试执行和分析是分开的,分析的结果具有滞后性,且依赖于测试人员经验,存在分析标准不统一的问题。为解决上述问题,笔者探索了一个基于指标趋势和阈值规则的自动化异常分析方法,并将方法嵌入性能压测执行过程,实现实时、自动的捕获测试异常,帮助测试人员分析和评估系统在特定条件下的表现。 一、优化压测执行过程 性能压测执行过程一般由系统自动完成,无需人工参与,主要包含发压、数据聚合、结果汇总三个...
-
- 深聊性能测试,从入门到放弃之:性能测试基准与阶段08-291、引言关于性能测试的话题,在小鱼的博客中,没有三位数,也有个位数。虽然写的不少,但是能记住的不多…这习惯性的喝点咖啡,然后就…(不喝咖啡睡眠质量也不咋地),索性就再唠点。我们都知道,性能测试的目的就是获取系统响应时间、吞吐量、稳定性、容量等信息。那么,我到底改如何去做或者如何发现这些缺陷?跟着小鱼往下捋~~2、性能测试内容关于性能测试,从以下几个方面入手就可以。2.1 基准测试Benchmark或者Baseline测试。一般为单用户测试,或者是零数据量环境下的测试。目的目的在于建立一个可度量的参考标准,为其他测试场景或者调优过程提供对比参考。也可认为是最基础的性能测试,如果基准测试的结果都不...



,另一种就是使用自己服务器的流,自定义直播组件(live-player、live-pusher),这里主要讲述,第一种的使用一、准备第一要了解是否满足 直播开通条件基本满足开头直播条件的功能里会有直播,然后去申请开通一下就行了创建直播间这个直播码就是主播开启直播的入口,主播扫码就可以进入基本信息点击后选择手机直播推流直播创建时需要核实身份 同时开播时间必须在12小时内 第一次开通需要人脸识别验证样式配置二、开发使用引入插件原生引入在app.jison1. 主包引入 &nb...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=50046&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=50046&pic=http://quan.51testing.com/ueditor/php/upload/image/20210219/1613698850954930.png){kind=link}
添加用户参数功能模块 (2)设置参数变量、用户值 注意勾选每次迭代更新一次,否则每次都使用同样...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=1358&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=1358&pic=http://quan.51testing.com/ueditor/php/upload/image/20210122/1611298707562353.png){kind=link}
{kind=link}
温馨提示
打开微信 扫一扫
温馨提示
设置支付密码
- 关于我们 联系我们 版权声明 广告服务 站长统计
- 建议使用IE 11.0以上浏览器,800×600以上分辨率,法律顾问:上海兰迪律师事务所 项棋律师
- 版权所有 上海博为峰软件技术股份有限公司 Copyright©51testing.com 2003-2024, 沪ICP备05003035号
- 投诉及意见反馈:webmaster@51testing.com; 业务联系:service@51testing.com021-64471599-8017

- 51testing软件测试圈微信