 0
0 0
0


- 时间减少90%以上!分布式系统的性能优化实战——软件测试圈
1 背景
分布式批量系统指的是采用分布式数据库架构,主体功能由批量程序实现的系统。分布式系统批量程序的性能测试,除了和联机交易性能测试一样关注服务器资源使用率是否合理、是否存在性能异常外,在测试执行阶段需要关注是否因数据分布不均衡导致部分并发子程序执行时间过长,成为整体批量程序的“短板”,从而影响批量程序的整体时间。
下面我主要介绍一种分布式系统批量程序性能优化的思路,并结合实际测试效果说明。
2 分布式系统分片和批量并发规则
被测系统数据库为分布式数据库,存储并处理某公司各个机构的业务数据,包括若干个数据库分片、500多个分片键(分布式表的一个主键字段,用来区分数据存放的分片),分片键值是由机构ID号(以下简称机构号)按照一定规则映射而来。每个分片包含若干分片键,某个分片键对应若干机构的数据。
批量程序执行时,根据系统相关配置表中的静态配置,500多个子程序并发分别处理对应分片键下的业务数据。各个子程序处理逻辑相同,所以当某些子程序待处理的数据量相对其他子程序过多时(即该分片键下机构数据明显多于其他分片键下数据),这些耗时长的子程序会拖慢整体程序的效率。

图1 分片与分片键对应关系
3 抢任务方式优化数据分布不均衡的批量程序
3.1 由静态并发改造抢任务模式
根据系统按分片键静态并发的特点,当批量程序子程序间处理数据分布不均衡时,部分子程序执行时间过长,成为整体批量程序的“短板”,从而影响批量的整体时间。为解决上述问题,本系统采取了“抢任务”的动态并发优化方法。

图2 抢任务改造前后批量程序逻辑对比
1)将待处理表中的所有数据,按照一定的维度(如机构号+该表的某个参数值)划分成若干个任务,单个任务就是某个机构下某参数值对应的数据。
2)在实际处理数据程序执行之前,添加一个生成任务程序,执行该程序就会在任务表中添加全部任务的记录,所有任务当前处于初始化状态。
3)生成任务程序执行后,自动调起数据处理程序,改造后的程序不再按照静态并发,而是去查询任务表中状态为初始化且数据量大(优先级高)的任务,任务结束时,处理状态改为已完成,子程序查找下一个未处理的任务,直到任务表没有状态为初始化的任务,所有子程序成功执行完成。
实际测试场景执行时采用1600万条数据对某批量程序(该程序处理的业务数据,各个分片键下的数据极不均衡,经分析适用于本优化方法)进行测试数据准备,按照优先级处理任务300个子程序动态并发执行,按当前维度共生成11万个任务,所有子程序均在33分钟内完成,无明显过长的子程序,总体执行时间32分21秒,系统资源和数据库资源利用率均正常。
3.2 优化任务处理数据量
按前述优化的生成任务维度,有个别任务处理数据量仍然很大,如果不进行进一步拆分还是存在一定“短板”,且生成的任务过多,大量任务都是小数据量任务,处理数据程序频繁抢“小任务”并更新数据的效率较低。为解决上述问题,程序进行了第二次优化。
1)生成任务时增加限制任务处理数据量的参数,该参数作用是规定单个任务的最大数据处理数,当同一分片键维度的任务处理数据量未达到这个值时,将这几个任务合并为一个更大的任务,如果分片键发生了切换,则生成下一个任务。
2)对于原有维度拆分出来的大任务,通过增加维度的字段,使单个维度的处理数据量降低,这样一个维度包含的数据更小,同时也参照上述参数限定任务最大数据处理数。
上述优化主要目标即控制个别“大任务”的处理数据量,合并多数“小任务”,使任务总量变少,减少抢任务造成的时间成本,并且任务之间处理数据量更均衡。
按上述策略优化的生成任务程序和数据处理程序,并发数不变,仍然采用同样数据进行准备并执行测试,由于生成任务的规则变化,生成的任务量由原来的10万以上降低到1000以内,生成任务时间增为2分40秒,执行数据处理程序时间降低为12分33秒,生成任务和处理数据的总执行时间比第一次优化明显提升。下表是两次优化执行性能测试执行时间对比。

该批量程序按上述策略两次优化后,生产环境中处理时间由优化前的近4小时缩短到15分钟左右,时间减少90%以上,且系统资源运行平稳,无性能瓶颈。
4 总结及展望
通过分布式系统的性能测试实践,我们根据系统特点在批量程序性能优化方面积累了一定经验。抢任务性能优化方式解决了批量程序不同分片键处理数据量不均衡导致的执行时间过长问题,在项目测试中取得了明显的优化效果。
未来我还将持续探索分布式系统的批量测试技术和测试方法,加强系统分析与调优能力,为提升分布式批量系统效率及可靠性继续努力。
作者:王谦
- -1.00 查看剩余0%
- 【留下美好印记】赞赏支持

热门文章
最新讲堂
- 推荐阅读
- 换一换
- 1、引言面试官:小鱼,你来说说自动化测试架构是啥,怎么理解自动化测试架构?小鱼心想:挖草~ ~ 你这个坑,你这一个问题,我都能写一篇文章了。奈何心里这样想的,也不能就这样表达出来,于是乎,小鱼就说:嗯,这问题,我可以从以下几点来慢慢说。2、架构是个啥东西软件架构(software architecture)是一系列相关的抽象模式,用于指导大型软件系统各个方面的设计。软件架构是一个系统的草图。软件架构描述的对象是直接构成系统的抽象组件。各个组件之间的连接则明确和相对细致地描述组件之间的通讯。在实现阶段,这些抽象组件被细化为实际的组件,比如具体某个类或者对象。在面向对象领域中,组件之间的连接通常用...
-
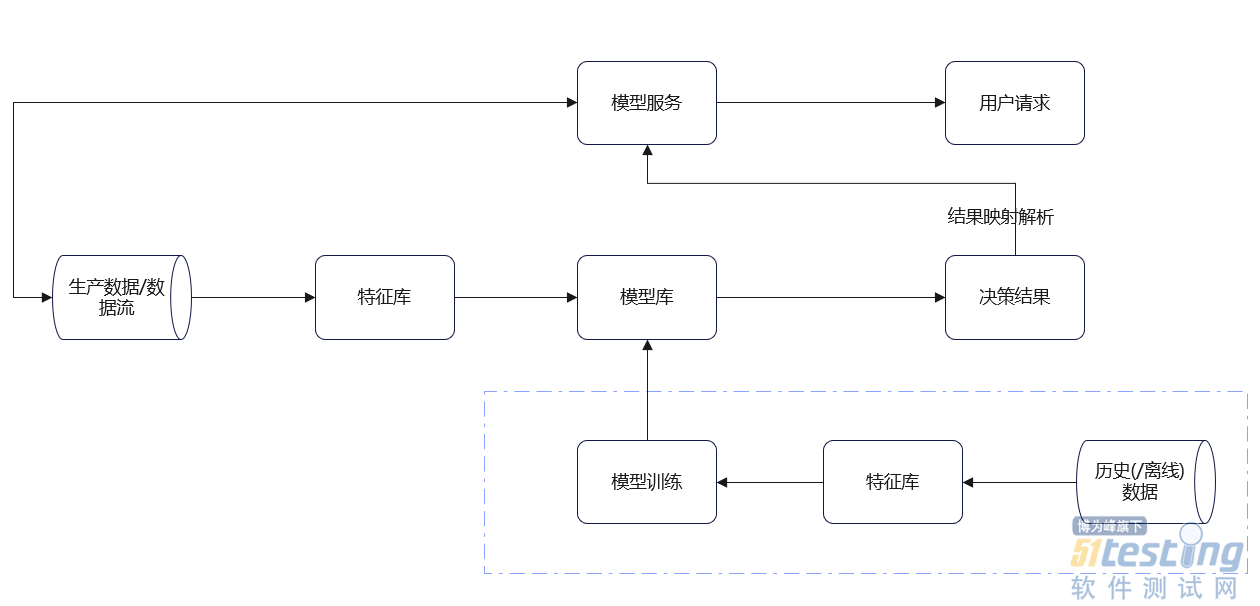
- 1、引言 在上一篇中,我们聊到了《AI测试技能卷起来!目标检测算法测试流程与方法总结》,反响还不错。但是,也有测试同学给我留言:“能不能讲一讲模型工程的测试流程和方法”。这当然没问题了, 因为在整个工程中,算法模型只是其中的一个环节,我们模型测试完成后,需要部署到系统中,这样才能让模型真正的应用于业务中。 为了更好的让你们理解模型在系统中的流程,我以我的工作为例(当然,处于职业操守,部分内容进行脱敏),以流程图的形式给大家展示。 通过上图,大家可以了解到模型的整体架构。 这里说两点: 1)数据流:即数据解析,保证数据的质量; 2)特征库:即数据处理,提取数据特征进行...
-
- 软件测试的岗位会越来越少吗?——软件测试圈05-21对这个问题只想说:裁员不可怕,岗位少也不可怕,可怕的是,软件测试行业已经发生巨变,而你却原地踏步! 经济寒冬放大了软件测试工程师职业危机,也加速推动了行业发展 经济大环境不好,投资和业务盈利预期收紧,企业出于生存本能,会勒紧裤腰带,减员增效,即裁掉多数低端人才,保留或重新招募少数高端人才,让公司的运营成本、人力效率和业务质量达到最佳平衡点。尤其是,前些年互联网热潮红利造成 IT 技术人才平均薪资有溢价水分,企业人力成本高企,也让裁员成为过冬最直接有效的手段。 在软件测试领域,这一现象或许更为明显。为了降低人力成本,企业会更多的使用外包测试服务,而外包市场的发展壮大,又会进一步推动企业...
- 加速 Selenium 测试执行最佳实践07-24性能测试是软件开发和应用过程中至关重要的环节。它是评估系统性能、稳定性和可扩展性的有效手段,可以确保软件在真实环境中高效运行。在现代技术快速发展的时代,性能测试的重要性愈发显著。性能测试在软件开发和应用过程中的重要性不可低估。它是保障用户体验、发现潜在问题、提高系统可靠性的关键手段。同时,遵循性能测试的最佳实践,能够确保测试的准确性和可靠性,提高测试效率,为软件开发和应用提供有力的保障。只有重视性能测试,并遵循最佳实践,我们才能构建稳定、高效的应用,满足用户对技术的不断追求和挑战。下面分享几个性能测试中最佳实践,以供参考。# 设定明确的性能目标在开始性能测试之前,首要任务是设定明确的性能目标。...
- 接口性能测试方案——软件测试圈07-05性能测试术语解释1.响应时间响应时间即从应用系统发出请求开始,到客户端接收到最后一个字节数据为止所消耗的时间。响应时间按软件的特点再可以细分,如对于一个C/S软件的响应时间可以细分为网络传输时间、应用服务器处理时间、数据库服务器处理时间。另外客户端自身也存在着解析时间、界面绘制呈现时间等。响应时间主要站在客户端角度来看的一个性能指标,它是用户最关心、并且容易感知到的一个性能指标。2.吞吐率吞吐率指单位时间内系统处理用户的请求数,从业务角度看,吞吐率可以用每秒请求数、每秒事务数、每秒页面数、每秒查询数等单位来衡量。从网络角度看,吞吐率也可以用每秒字节数来衡量。吞吐率主要站在服务端的角度来看的一个...





,以流程图的形式给大家展示。 通过上图,大家可以了解到模型的整体架构。 这里说两点: 1)数据流:即数据解析,保证数据的质量; 2)特征库:即数据处理,提取数据特征进行...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=147167&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=147167&pic=http://quan.51testing.com/ueditor/php/upload/image/20240816/1723794323886606.png){kind=link}
{kind=link}
{kind=link}
- 关于我们 联系我们 版权声明 广告服务 站长统计
- 建议使用IE 11.0以上浏览器,800×600以上分辨率,法律顾问:上海兰迪律师事务所 项棋律师
- 版权所有 上海博为峰软件技术股份有限公司 Copyright©51testing.com 2003-2024, 沪ICP备05003035号
- 投诉及意见反馈:webmaster@51testing.com; 业务联系:service@51testing.com021-64471599-8017

- 51testing软件测试圈微信