 0
0 0
0


- 3种SQL语句优化方法,测试人必知必会!——软件测试圈
关于SQL语句的优化,本质上就是尽量降低SQL语句的执行时间,对于如何降低SQL语句的执行时间,可以从以下几个方面入手。
一、降低SQL语句执行时的资源消耗
这是我们在数据库性能调优中常用的方法,该方法以分析SQL语句的执行计划为切入点,核心思路是找到执行计划中开销较高的操作,通过改写SQL语句或改变表访问方式调整执行计划,从而达到降低SQL语句执行消耗,缩短执行时间的目的。
对于改变表访问方式,常见的手段是使用索引替代开销较高的全表扫描,但这种方式不是万能的,是有一定的使用前提的,有时候,滥用索引反而会带来较高的性能开销。
以下列举一些适合采用访问索引的方式替代原有操作的案例。
1.使用索引替代全表扫描
如果查询结果集只占表中的一小部分数据,这时,可以采用索引访问的方式替代全表扫描,即使不能达到索引覆盖而产生回表操作,其开销也小于采用全表扫描操作。
例如,使用Oracle数据库存储,一个用户信息表user(userid,username,sex,tel,code),code列表示用户的社保号信息,系统运行之初允许社保号信息为非必填项,这就导致少部分code列的值为null,为了提高对code列检索的效率,我们为code列创建了普通B树索引inx_code(code),要查询所有未提供社保号的那部分用户信息,之后系统为这部分用户发送信息,提示补全社保号信息,语句如下:
select * from user where code is null;
语句执行后,用时20秒左右,user表中存在50万条左右的用户记录,返回的未提供社保号的用户记录有5000条左右。
通过分析执行计划,在查询执行时采用了全表扫描方式,这是造成查询执行时间较长的主要原因。
对于B树单列索引,null值将使得索引失效,所以优化器采用了全表扫描方式。
该查询实际返回记录5000条左右,表中共有记录50万条左右,实际返回的记录只占表总记录的1%,这时,可以采取使用索引扫描替代全表扫描。
如何使得包含null值的列在检索时可以使用索引呢,这就需要将基于B树的单列索引改为复合索引,将原有索引修改为inx_code(code,0),再次执行查询,对user表的访问方式由全表扫描改为索引范围扫描,执行时间降至1秒之下。
2.利用索引的有序性消除排序操作
在对数据库的访问中,排序是一种开销较搞的操作,数据库为了完成排序操作,需要扫描表中的所有记录,之后采取相应的算法对记录进行排序。如果表中的记录随系统的运行累积增加,那么排序操作的执行开销会逐渐变大,执行时间会越来越长。
索引是有序的,因为相应的索引键值已经事先按一定规则完成排序,如果SQL语句中需要按表中的某列进行排序,此时,可以为该列创建索引,从而达到通过索引扫描代替完成排序需要的全表扫描,达到降低访问开销,缩短执行时间的目的。
例如,在MySQL8.0数据库中,如果需要对多个列进行排序,且排序顺序有升有降,即:order by col1,col2 desc,此时,可以为两个排序列创建一个复合降序索引idx_col1_col2(c1,c2 desc)。
3.利用索引改变表关联方式
在执行表关联查询操作时,数据库的优化器可能选择了不合理的表关联方式,使得表关联查询开销较高,耗时较长。
例如,PostgreSQL数据库中有user、ure、org三个表,分别存储系统用户信息、已完成认证的用户信息和相应的组织信息。有如下的查询语句:
select * from user join ure on user.id=ure.id join on org on ure.oid=org.oid where org.pcode=’12012’ order by ure.update;
该查询的执行计划如下图所示:

查询执行用时32毫秒,开销为2206。
通过执行计划我们发现,user、ure和org三表关联均采用了Hash Join的关联方式,这种关联方式是最优的吗?
分析表连接方式,org表是第一个关联的驱动表,该表过滤后的结果集只有24条记录,结果集很小,所以,可以将org表与user表的连接方式调整为嵌套循环连接方式。此外,对org表的访问采用了全表扫描,可将其调整为索引扫描。
为查询org表的where条件列pcode列创建索引,同时为作为嵌套循环连接的被驱动表user表的关联条件列oid列创建索引,本次调优后的执行计划如下图所示。

改变org表与user表的连接方式后,执行时间降低为4.85ms,执行开销降低到273。
进一步分析调优后的执行计划,org表与user表连接后的结果集只有47条记录,该结果集与ure表的连接方式仍可以调整为嵌套循环连接,以该结果集作为驱动表,ure表作为被驱动表。为达到该目的,为ure表的连接条件列id设置索引即可。
最终的执行计划如下图所示。

由此可见,将表连接方式全部由Hash连接调整为嵌套循环连接后,执行时间最终降至1ms,执行开销降至30。
二、并行执行SQL语句
这种方式是通过增加额外的资源消耗来换取SQL执行时间的缩短,其意义类似于代码优化中的“以空间换时间”的策略。
增加的额外资源主要是指数据库服务器的处理器(CPU)、内存、I/O等硬件资源。
例如:在Oracle数据库中,对于一个查询操作,如果其所作的工作可以分割成多个互不相关的部分,则该查询可以由多个进程并发执行。可以并行执行的查询操作主要有全表扫描、快速索引全扫描、分区索引范围扫描、以及需要执行全表扫描完成的表连接。
三、避免不必要的资源争用导致SQL执行效率下降
有些SQL语句,其执行时间不定,时快时慢,这些语句的执行计划自身未存在问题。导致语句执行效率差的原因是语句执行时,数据库服务器在执行其他消耗资源的操作,出现资源争用的情况。
例如:某系统每日凌晨定时执行统计信息收集工作,如果这时对系统执行性能测试,涉及对该数据的查询操作将受到影响,导致性能测试结果不准确。因此,性能测试需要避开数据库执行统计信息收集的时间。
以上对SQL语句的优化方法做了简要的介绍,下面对SQL语句的优化步骤和方法做一个说明和总结。
1.找到执行时间较长、消耗资源较多的SQL语句。例如:MySQL数据库可从慢查询日志中获取,Oracle数据库可查看AWR报告。
2.分析以上获取的性能较差的SQL语句的执行计划,找到执行计划中开销较高的部分,评估执行计划是否合理,是否需要调整。
3.对于执行计划中开销较高的部分,采取相应的措施降低执行开销,缩短执行时间,例如如下方式:
(1)如果是统计信息不准确导致生成了错误的执行计划,需要首先重新收集统计信息;
(2)如果是SQL语句编写存在问题,可以在不改变业务逻辑的前提下对SQL语句进行适当的改写;
(3)对于不必要的全表扫描或排序,可以通过创建合适索引消除全表扫描和排序;
(4)如果因为某些原因导致SQL语句的执行计划不稳定,在条件允许的情况下,使用提示器(Hint)固定SQL语句的执行计划;
(5)如果因为表或索引本身设置不合理,导致执行开销较高,用时较长,则应该对表或索引重新设计,例如:表中记录过大,超过亿级,此时应考虑分表分库;
(6)对于具备并行执行的部分,考虑采用并行执行的方式;
(7)如果是业务设计不合理导致SQL语句执行效率低下,应考虑修改业务逻辑。
作者:fhh192
- -1.00 查看剩余0%
- 【留下美好印记】赞赏支持

热门文章
最新讲堂
- 推荐阅读
- 换一换
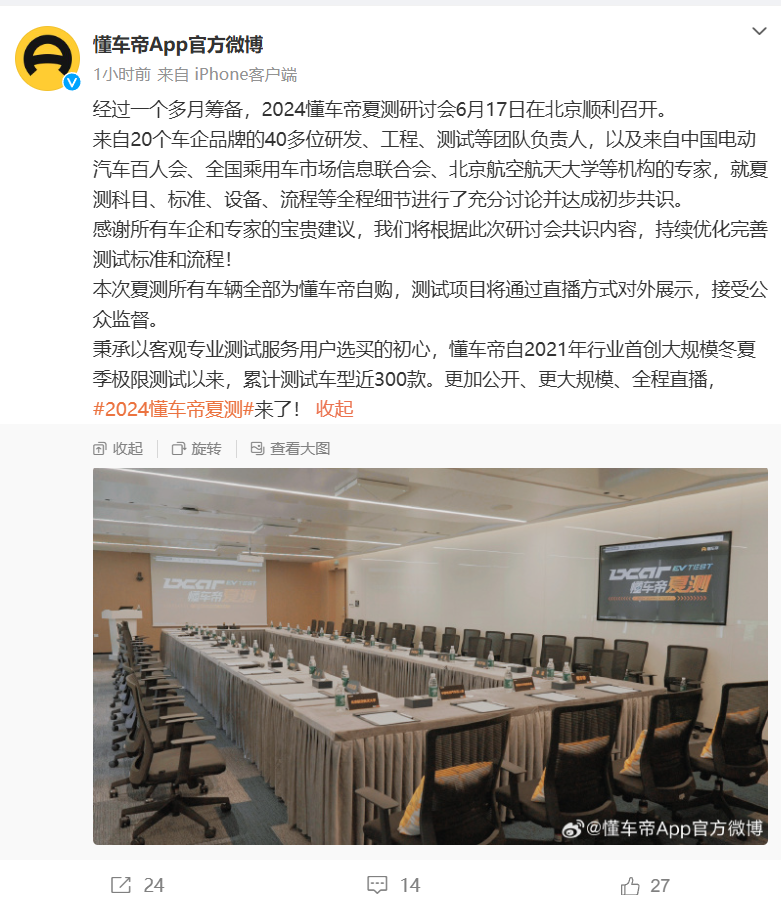
- 2023 年底,懂车帝“冬测”争议事件在全网引发热议,包括华为、长城汽车、吉利均对测试标准表示质疑。余承东还称“某些媒体的冬季测试非常具有随意性、创造性”,并称测试“不专业”。 时隔半年,懂车帝 App 官方微博今日宣布,经过一个多月筹备,2024 懂车帝夏测研讨会 6 月 17 日在北京顺利召开。“本次夏测所有车辆全部为懂车帝自购,测试项目将通过直播方式对外展示,接受公众监督。” 懂车帝还称:“来自 20 个车企品牌的 40 多位研发、工程、测试等团队负责人,以及来自中国电动汽车百人会、全国乘用车市场信息联合会、北京航空航天大学等机构的专家,就夏测科目、标准、设备、流程等全程细节进行...
-
- 测试环境和测试分类的介绍——软件测试圈12-23测试流程我们一般在项目进行开立项会(产品经理 项目经理 开发人员 测试人员)的时候进行参与,讨论需求并提出建议,在立项会中制定需求文档,由UI设计原型图,开发根据需求进行编码,我们测试会根据需求文档进行编写测试计划,根据模块的颗粒度划分并编写测试用例以及对用例的评审,开发结束后,测试对主要功能进行冒烟测试,执行测试用例,提交bug开发进行修改,修改成功后关闭bug,进行回归测试,在上线前进行测试总结。用例评审会:【测试人员 测试组长/项目经理 产品经理】 a:组内评审【测试人员 测试组长/项目经理 产品经理 客户】 b:组外评审冒烟测试:对主要功能进行测试回归测试:bug修改后,重新测试查看是...
- 一、引言对mysql数据库进行备份最近比较苦逼,拿着测试的钱,干着运维的活,估计这只有小屌丝能理解。。小屌丝表示 不服。。。。由于要做数据备份,所以就写了一个脚本,让它自己跑着吧~~二、代码实战代码示例# -*- coding:utf-8 -*- # @Time : 2022-07-29 # @Author : Carl_奕然 #DB基本信息 import os import time import datetime import glob...
-
- app测试原来是这样——软件测试圈05-13上期我们简单介绍APP测试 与web测试区别,本期我们将介绍APP测试中涉及的各种测试策略,以及后期将对各种测试策略进行逐一讲解。APP测试主要分为6种不同的测试策略,分别是功能测试、兼容适配测试、性能测试、安全测试、专项测试以及稳定性测试。首先我们一起来看看APP测试中的功能测试。不管是任何类型的测试,功能测试都是必须要进行,只有保证功能正常才可以进行后续各种测试,功能测试依然是围绕着需求进行。APP的 功能测试主要从以下几个方面进行:安装卸载测试、升级测试、业务逻辑测试、UI测试、异常测试。1. 安装卸载测试:在测试APP之前,首先就要进行APP的安装。而对安装测试进行测试用例设...

- 我叫缺陷,从被创建至关闭,到最后做缺陷分析,这是我的完整生命周期。我的整个生命周期贯穿着整个项目的项目周期,因此,掌握我的生命周期,不止是测试人员必修的课程,也是测试人员的灵魂。 缺陷的定义 对于软件的缺陷来说,一般人都把我说是Bug,但正确的来说,应该是Defect,这两者的区别是: Bug是编程错误的结果; Defact 是与需求的偏离。 Defect不一定表示代码中存在Bug,它可能是尚未实现但在软件要求中定义的功能。实际上,无论是测试人员还是开发人员,还是习惯把我叫为Bug。 缺陷的属性组成 我一般由标识(ID)、标题、类型、优先等级、严重程度、状态、指派人组成,这些...

-


{kind=link}
的时候进行参与,讨论需求并提出建议,在立项会中制定需求文档,由UI设计原型图,开发根据需求进行编码,我们测试会根据需求文档进行编写测试计划,根据模块的颗粒度划分并编写测试用例以及对用例的评审,开发结束后,测试对主要功能进行冒烟测试,执行测试用例,提交bug开发进行修改,修改成功后关闭bug,进行回归测试,在上线前进行测试总结。用例评审会:【测试人员 测试组长/项目经理 产品经理】 a:组内评审【测试人员 测试组长/项目经理 产品经理 客户】 b:组外评审冒烟测试:对主要功能进行测试回归测试:bug修改后,重新测试查看是...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=1186&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=1186&pic=http://quan.51testing.com/ueditor/php/upload/image/20201223/1608689615589047.png){kind=link}
{kind=link}
{kind=link}
、标题、类型、优先等级、严重程度、状态、指派人组成,这些...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=146362&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=146362&pic=http://quan.51testing.com/ueditor/php/upload/image/20230721/1689909855196001.png){kind=link}
- 关于我们 联系我们 版权声明 广告服务 站长统计
- 建议使用IE 11.0以上浏览器,800×600以上分辨率,法律顾问:上海兰迪律师事务所 项棋律师
- 版权所有 上海博为峰软件技术股份有限公司 Copyright©51testing.com 2003-2024, 沪ICP备05003035号
- 投诉及意见反馈:webmaster@51testing.com; 业务联系:service@51testing.com021-64471599-8017

- 51testing软件测试圈微信