 0
0 0
0


- 文本 Embedding 基本概念和应用实现原理
作者:何文斯 - Vince,LLM 应用研究者,Dify 团队产品经理,对 LLM 应用、Embedding、LangChian 等保持持续关注和深度研究。
大语言模型之上的应用层面有三项技术需要理解:提示词工程(Prompt Engineering);嵌入(Embedding);微调(Fine-tuning)。其中 Embedding 作为大语言模型理解文本语义的重要技术,在搜索引擎、构建私有知识问答系统、内容推荐系统等都有相当广泛的应用。本文作为我的一篇个人技术笔记在整理了一周后分享到公众号内。
Embedding 的基本概念
什么是 Embedding,OpenAI 官方文档中是这样解释的:
Embeddings are numerical representations of concepts converted to number sequences, which make it easy for computers to understand the relationships between those concepts.
Embedding 是将概念转换为数字序列的数值表示,这使得计算机能够轻松理解这些概念之间的关系。

Embedding 也是文本语义含义的信息密集表示,每个嵌入都是一个浮点数向量,使得向量空间中两个嵌入之间的距离与原始格式中两个输入之间的语义相似性相关联。例如,如果两个文本相似,则它们的向量表示也应该相似,这一组向量空间内的数组表示描述了文本之间的细微特征差异。
简单来说,Embedding 帮助计算机来理解如人类信息所代表的“含义”,Embedding 可以用来获取文本、图像、视频、或其他信息的特征“相关性”,这种相关性在应用层面常用于搜索、推荐、分类、聚类。
Embedding 是如何工作的?
举例来讲,这里有三句话:
“The cat chases the mouse” “猫追逐老鼠”
“The kitten hunts rodents” 小猫捕猎老鼠。
“I like ham sandwiches” 我喜欢火腿三明治。
如果是人类来将这三个句子来分类,句子 1 和句子 2 几乎是同样的含义,而句子 3 却完全不同。但我们看到在英文原文句子中,句子 1 和句子 2 只有“The”是相同的,没有其他相同词汇。计算机该如何理解前两个句子的相关性?
Embedding 将离散信息(单词和符号)压缩为分布式连续值数据(向量)。如果我们将之前的短语绘制在图表上,它可能看起来像这样:

我们可以看到,在文本被 Embedding 压缩到计算机可以理解的多维向量化空间之后,由于句子 1 和 2 的含义相似,它们会被绘制在彼此附近。句子 3 却距离较远,因为它与它们没有关联。如果我们有第四个短语 “Sally 吃了瑞士奶酪”,它可能存在于句子 3(奶酪可以放在三明治上)和句子 1(老鼠喜欢瑞士奶酪)之间的某个地方。
在这个例子中,我们只有 2 个维度:X 轴和 Y 轴。实际上,Embedding 模型会提供更多的维度来表示人类语言的复杂度。比如 OpenAI 的 Embedding 模型 text-embedding-ada-002 会输出 1536 个维度。这足以让计算机来理解文本语义的细微差别。对于相似文本的分类,在三维空间内看可能是这样的(见下图),动物、运动员、电影、交通工具、村庄这些文本在空间中的距离是相近的。

Embedding 的优势是什么?
ChatGPT 虽然擅长回答问题,但可以回答的范围仅限于它在训练数据中记忆的数据。GPT 不擅长回答的问题包括:
2021 年 9 月之后的问题
特定领域知识,如医疗、法律、金融等
个人或组织内部的非公开数据
GPT 有两种办法可以学习新知识:
通过模型权重(即在训练集上对模型微调)
通过模型输入(即将知识做为少样本提示词插入到消息中)
尽管微调可能感觉更自然,毕竟数据训练是 GPT 学习所有知识的方式,但微调在事实回忆方面并不可靠。类比一下,把大模型比作一个参加考试的学生,模型权重就像长期记忆,当你对模型微调时,就像提前一周准备考试,当考试来临时,模型可能会遗漏掉之前学习过的知识或者错误地回答出从未教授给他的知识。
而使用 Embedding 的方式,这个学生在考试前什么都不需要准备,在考试时带着一份小抄进了考场,需要回答的问题的时候,就低头看下准备好的小抄,照着小抄来答题相比于记忆(微调)肯定更准确。并且考完试就直接把小抄丢掉,也不用占用任何记忆,整个过程简单易行(对技术实现来讲也是如此)。
不过这种临时翻看小抄的方式也有限制,每次参加考试,这个学生只能带进几页小抄,不可能把所有教材笔记带进考场。这是由于大模型单次输入的词数限制(max tokens)。GPT3.5 的单词输入词数上限是 4K(5 页纸),GPT4 发布之后将这个上限扩大了 8 倍,最高可支持 32K(40 页)。
所以当数据量远远超过这个词数限制的时候怎么办呢?这就要引入基于 Embedding 的语义检索(Search)+上下文注入提问(Ask)的策略。
我在上一篇《为什么整合了 GPT4 的微软新必应没有想象中好用?》中也简单解释了 Embedding 在搜索引擎中的应用,接下来就再举例如何构建一个基于 Embedding 的本地知识问答系统,原理上有很多相似之处,简单来说分为三个步骤:
第一步:准备数据
收集:准备一个本地知识库,提供需要的文本,如文章、报告、日记、博文、网页、论文等等;
分块:将整篇的文档切分成小的文本片段(Chunk);
嵌入:将文本片段使用 OpenAI API 或者本地 Embedding 模型来将文本向量化为多维向量数组;
存储:对于大型数据集,需要将向量数组存储,以便于以后调用。对于小型数据集可以选择临时存储的方式;
第二步:语义检索
将用户问题使用 OpenAI Embedding API 或者本地 Embedding 模型来将问题生成 Embedding 嵌入;
通过向量值之间的相似度检索(如余弦相似度或欧式距离算法),查询与问题最相似的文本片段;
第三步:文本注入和回答
将用户问题和查询到的最相似的文本片段(TopK)作为提问消息上下文注入到大模型中;大模型根据用户问题和注入的少样本提示回答出问题;以下是原理实现流程图:

Embedding 的语义检索方式对比关键词检索的优势:
语义理解:基于 Embedding 的检索方法通过词向量来表示文本,这使得模型能够捕捉到词汇之间的语义联关系,相比之下,基于关键词的检索往往关注字面匹配,可能忽略了词语之间的语义联系。
容错性:由于基于 Embedding 的方法能够理解词汇之间的关系,所以在处理拼写错误、同义词、近义词等情况时更具优势。而基于关键词的检索方法对这些情况的处理相对较弱。
多语言支持:许多 Embedding 方法可以支持多种语言,有助于实现跨语言的文本检索。比如你可以用中文输入来查询英文文本内容,而基于关键词的检索方法很难做到这一点。
语境理解:基于 Embedding 的方法在处理一词多义的情况时更具优势,因为它能够根据上下文为词语赋予不同的向量表示。而基于关键词的检索方法可能无法很好地区分同一个词在不同语境下的含义。
对于语境理解来讲,人类使用词语和符号来交流语言,但是孤立的单词大多没有意义,我们需要从共享的知识和经验中汲取,才能理解它们。比如“你应该谷歌一下”这句话,只有在你知道谷歌是一个搜索引擎,并且人们一直在使用它作为动词时才有意义。同样地,对于有效的自然语言模型来说,也要能够以理解每个单词、短语、句子或段落在不同语境下可能的含义。
Embedding检索存在哪些限制?
输入词数限制:即使通过 Embedding 的方式将最相似的文本片段给到大模型,仍旧要面临这个问题,当检索涉及到的文本较多时,为了限制注入上下文的词数,往往也限定了 TopK 的 K 值,也就还是会导致信息丢失的问题。
仅支持文本数据:目前的 GPT3.5 和众多大模型暂时还不具备图像识别能力,但对于检索知识而言,有大量的知识仍需要通过结合内容中的图片才能更好理解,如学术文献中的插图,财务报告中报表插图。
大模型的胡编乱造:当检索到的相关文档内容不足以支持大模型来回答问题时,大模型为了能够尽力完成问题回答,会存在一定的“自我发挥”。
不过针对以上的几个问题,也都会有相应的解决方法:
1.词数限制:Scaling Transformer to 1M tokens and beyond with RMT 这篇论文提到可以通过循环记忆技术,在保持高精度的同时,可以将模型有效上下文长度提到到 200 万。除此之外,在 LangChain 这类中间应用层,也有通过工程化的方式来绕过词数限制的办法。

2.多模态理解:除了已知的 GPT4 的图像理解之外,也已经出现了 Mini-GPT4 这样的开源项目,结合 BLIP-2 可以实现简单的图像理解。这个问题在不远的将来就可以得到解决。

3.胡编乱造问题:这个问题可以在提示词(Prompt)层面上优化,一般都会加一句,“如果你不知道答案,请说不知道,不用试图编造答案。”

实际应用开发和落地依然有大量问题需要解决:
比如大模型能力限制导致提问环节概括信息丢失问题;
比如相似度算法的选择在不同应用场景的选择问题;
比如文档传递时文本可信度的打分策略问题;
比如不同模型在 Prmopt template 层的工程处理问题;
比如文档的切分方法对于上下文注入之后的问答影响问题,等等。
以下是 Embedding 相关的一些资源分享:
向量数据库:
为了快速搜索许多向量,我们建议使用向量数据库。您可以在我们在 GitHub 上的 Cookbook 中找到有关与向量数据库和 OpenAI API 一起工作的示例。
可用的向量数据库选项包括:
Pinecone,一个完全托管的向量数据库
PGVector,一个免费可用的向量数据库
Weaviate,一个开源矢量搜索引擎
Qdrant,一个矢量搜索引擎
Milvus,专为可扩展相似性搜索而构建的矢量数据库
Chroma,一个开源嵌入存储库
Typesense,快速开源矢量搜索引擎
Zilliz,由 Milvus 提供支持的数据基础设施
文本向量化工具:
Text2vec:https://github.com/shibing624/text2vec
文本相似度比较算法
余弦相似度(Cosine distance)
欧式距离(L2-Squared distance)
点积距离(Dot Product distance)
汉明距离(Hamming distance)
相关案例推荐:
FinChat:一款金融领域的对话工具,覆盖了 700 多家美国上市公司的基本财报信息;
Supabase:云数据库服务商 Supabase,支持向量化检索数据库内容;
ChatPDF:一款支持本地上传 PDF 对话的工具;
Semantra:一款开源的面向本地文档(PDF、TXT)的语义检索工具,只针对精准检索场景;
Defog.ai:一款基于自然语义对话方式跟数据库和文档交互的应用。
参考引用:
https://github.com/openai/openai-cookbook
https://openai.com/blog/introducing-text-and-code-embeddings
https://platform.openai.com/docs/guides/embeddings
https://weibo.com/1727858283/MDI5fnKQH(推荐宝玉老师的微博)
https://arxiv.org/pdf/2304.11062.pdf
https://mp.weixin.qq.com/s/A8LfEDhL7GlqJdttgNfeJA
- -1.00 查看剩余0%
- 【留下美好印记】赞赏支持

热门文章
最新讲堂
- 推荐阅读
- 换一换
- 送你一套免费的性能测试框架搭建的课程!省下的300块,去吃一顿热气腾腾的火锅吧!点击下方链接,答问卷,领课程~链接:http://vote.51testing.com/ 作为开软件开发从业者,接口调试是必不可少的一项技能,在这方面 Postman 做的非常出色。但是在整个软件开发过程中,接口调试只是其中的一部分,还有很多事情 Postman 无法完成,或者无法高效完成,比如:接口文档定义、Mock 数据、接口自动化测试等等。Apifox 就是为了解决这个问题而生的。 接口管理现状 一、常用解决方案 1、使用 Swagger 管理接口文档 2、使用 Postman 调试接...
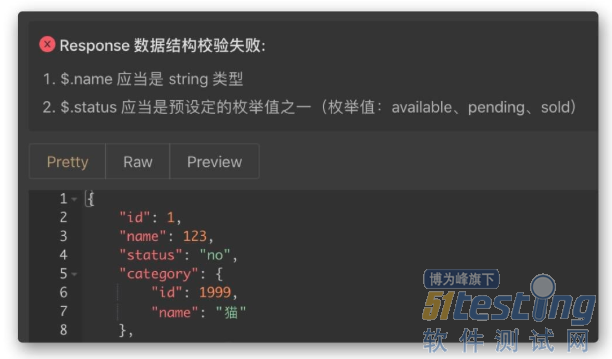
-
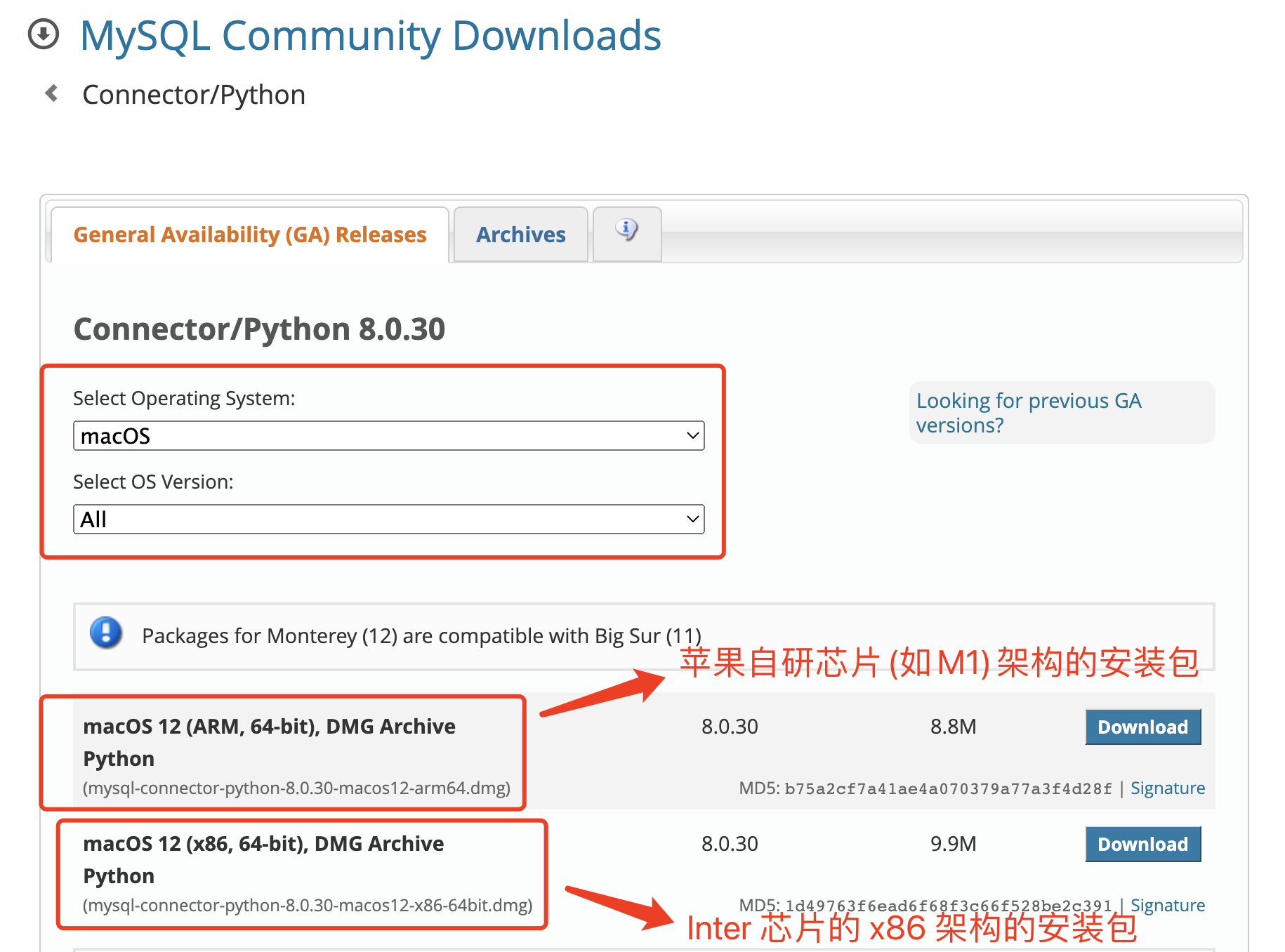
- MySQL 官方驱动模块在 Python 语言里,有很多连接 MySQL 数据库的模块,且都能执行 SQL 语句,完成数据的增删改查操作。MySQL Connector 是 MySQL 官方的驱动模块,在兼容性上特别的好;不会有数据乱码的情况的发生,对 MySQL 8.0 的支持也很好。有很多的第三方的模块对 MySQL 8.0 这个版本兼容性非常的不好,特别是 MySQL 8.0 引入的新的安全机制。不少第三方模块由于没有更新,所以是没有办法连接到最新版本的 MySQL上面的,所以这里推荐大家使用 “MySQL Connector” 这个 MySQL 官方的驱动模块,毕竟是官方,更新的速度还...
-
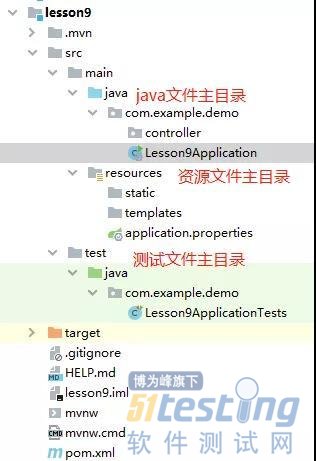
- junit是一个优秀的开源的java单元测试框架,也是目前比较流行且使用频率比较高的一款,今天我们就来讲讲junit怎么用。 junit主要用于白盒测试、回归测试、单元测试。 首先我们来新建工程,还是跟原来一样建立。建立之后看看pom.xml文件,已经默认的加入了junit的依赖 <dependency> <groupId>org.springframework.boot</groupId> <artifactId&...
-
- 美国的制裁可能已经将华为的智能手机业务逼到了绝境,但这家中国公司依然坚持不懈,并设法通过生产麒麟 9000S 绕过了这些贸易限制,这是其在短暂停滞后推出的这款定制 SoC被应用于新发布的 Mate 60 Pro 5G。 媒体对新发布的华为Mate 60 Pro 5G 进行了拆解,揭示了全新的麒麟 9000S 芯片 / 图片来源 - 彭博社 虽然在进行性能和效率比较时,麒麟 9000S 并不是能力最强的芯片组,但它的诞生标志着华为未来不再依赖高通等公司的意图,据一位分析师称,高通可能会因为这款新芯片而损失数十亿美元。 尽管华为受到贸易制裁,但仍是高通公司最大的客户之一,2022 年和 ...
-
- 测试工程师定位bug思路——软件测试圈10-14作为测试人员,和我们最常打交道的,莫属bug。当你发现bug后,会采取什么样的行动?是直接报出来,亦或找找问题原因?不管是我们自己找到的,亦或是开发修复后告诉我们的,知道问题之所在总是好的。在本篇文章中,笔者试图带领大家一起梳理下,为什么测试人员定位问题很重要,以及我们可以使用什么样的定位方法。NO1.定位问题的重要性很多测试人员可能会说,我的职责就是找到bug,至于找原因并修复,那是开发的事情,关我什么事?好,我的回答是,如果您只想做一个测试人员最基本最本分的事情,那么可以这么想。但是,如果您想要在测试甚至开发的道路上长足发展,就要知其所以然。那么,为什么定位问题如此重要?1、可以明确一个问...



{kind=link}
{kind=link}
{kind=link}
- 关于我们 联系我们 版权声明 广告服务 站长统计
- 建议使用IE 11.0以上浏览器,800×600以上分辨率,法律顾问:上海兰迪律师事务所 项棋律师
- 版权所有 上海博为峰软件技术股份有限公司 Copyright©51testing.com 2003-2024, 沪ICP备05003035号
- 投诉及意见反馈:webmaster@51testing.com; 业务联系:service@51testing.com021-64471599-8017

- 51testing软件测试圈微信