 0
0 0
0


- 天花板级别的Python读取文件的方法——软件测试圈
序言
哈喽兄弟们,今天咱们来了解一下 fileinput 。
说到fileinput,可能90%的码农表示没用过,甚至没有听说过。
这不奇怪,因为在python界,既然open可以走天下,何必要fileinput呢?
但是,今天我还是要介绍fileinput这个方法,因为太奈斯了。
不止是香。是真香!
接下来,就跟着我,一起fileinput,对,就是这个feel。
正文
1、方法介绍
基本用法
先来看一下fileinput的基本功能:
fileinput.filename():返回当前被读取的文件名。
—>在第一行被读取之前,返回 None。
fileinput.fileno():返回以整数表示的当前文件“文件描述符”。
—>当未打开文件时(处在第一行和文件之间),返回 -1。
fileinput.lineno():返回已被读取的累计行号。
—>在第一行被读取之前,返回 0。在最后一个文件的最后一行被读取之后,返回该行的行号。
fileinput.filelineno():返回当前文件中的行号。
—>在第一行被读取之前,返回 0。
—>在最后一个文件的最后一行被读取之后,返回此文件中该行的行号。
进阶用法
fileinput.isfirstline():如果刚读取的行是其所在文件的第一行则返回 True,否则返回 False。
fileinput.isstdin():如果最后读取的行来自 sys.stdin 则返回 True,否则返回 False。
fileinput.nextfile():关闭当前文件以使下次迭代将从下一个文件(如果存在)读取第一行;不是从该文件读取的行将不会被计入累计行数。直到下一个文件的第一行被读取之后文件名才会改变。
—>在第一行被读取之前,此函数将不会生效;它不能被用来跳过第一个文件。
—>在最后一个文件的最后一行被读取之后,此函数将不再生效。
fileinput.close():关闭序列。
2、 默认读取
代码示例:
import fileinput
'当 Python 脚本没有传入任何参数时,fileinput 默认会以 stdin 作为输入源'
for line in fileinput.input():
print(f'{line}')运行结果:

你输入的内容,程序都会读取并再输出。
俗称:复读机
3、处理一个文件
代码示例:
import fileinput
'files 输入打开文件的名称即可'
with fileinput.input(files=('output.txt',)) as file:
for line in file:
print(f'{fileinput.filename()} 第{fileinput.lineno()}行:{line}',end='')运行结果:

解析:
fileinput 有且仅有这两种读取模式:‘r’,‘rb’;
fileinput.input() 默认使用 mode=‘r’ 的模式读取文件,如果你的文件是二进制的,可以使用mode=‘rb’ 模式。
4、处理批量文件
多文件序号连续排序
调用方法
·fileinput.lineno()方法
代码示例:
import fileinput
'files 输入打开文件的名称即可'
with fileinput.input(files=('output.txt','input.txt')) as file:
for line in file:
#fileinput.lineno() 把两个文件的整合陈一个文件对象file,需要排序输出
print(f'{fileinput.filename()} 第{fileinput.lineno()}行: {line}', end='')
# fileinput.filelineno()两个文件单独读取,需要单独排序
print(f'{fileinput.filename()} 第{fileinput.filelineno()}行: {line}', end='')运行结果:

多文件序号单独排序
调用方法
·fileinput.filelineno()方法
代码示例:
import fileinput
'files 输入打开文件的名称即可'
with fileinput.input(files=('test1.txt','test2.txt')) as file:
for line in file:
# fileinput.filelineno()两个文件单独读取,需要单独排序
print(f'{fileinput.filename()} 第{fileinput.filelineno()}行: {line}', end='')运行结果:

与glob配合用法
在颜值的时代,上面的输出样式,已经无法满足我们的需要了,于是乎,我们就想到了glob。
代码示例:
import fileinput
import glob
#glob 匹配te开头的txt文件
for line in fileinput.input(glob.glob("te*.txt")):
if fileinput.isfirstline():
#输出读取文件
print('='*10,f'读取文件{fileinput.filename()}','='*10)
#fileinput.filelineno()方法读取
print(str(fileinput.filelineno())+ ':'+line.upper(),end='')运行结果:

就这颜值,哪个小姐姐能不喜欢呢。
5、读取与备份
调用方法
·fileinput.input 的backup 参数,可以指定备份的后缀名,比如 .bak
代码示例:
import fileinput
#触发backup的动作,源文件内容被修改,对源文件进行backup
with fileinput.input(files=("test1.txt",), backup=".bak",inplace=1) as file:
for line in file:
print(line.rstrip().replace('111111', '222222'))
print(f'{fileinput.filename()} 第{fileinput.lineno()}行: {line}', end='')运行结果:

6、重定向替换
解析
上面的例子, 用到了 inplace参数,表示是否将标准输出的结果写回文件,默认不取代。
代码示例:
import fileinput
#触发backup的动作,源文件内容被修改,对源文件进行backup
with fileinput.input(files=("test2.txt",), inplace=True) as file:
print("[INFO] task is started...")
for line in file:
print(f'{fileinput.filename()} 第{fileinput.lineno()}行: {line}', end='')
print("[INFO] task is closed...")运行结果:

注
通过运行结果,可以看到:
在 for 循环体内的 print 内容会写回到原文件中了。
而在 for 循环体外的 print 则没有变化。
7、进阶
openhook含义解析
在 fileinput.input() 中有一个 openhook 的参数,它支持用户传入自定义的对象读取方法;
如果没有传入任何勾子,fileinput 默认使用的是 open 函数;
方法介绍
fileinput 内置了两种勾子:
1、fileinput.hook_compressed(filename, mode)
使用 gzip 和 bz2 模块透明地打开 gzip 和 bzip2 压缩的文件(通过扩展名 ‘.gz’ 和 ‘.bz2’ 来识别);
如果文件扩展名不是 ‘.gz’ 或 ‘.bz2’,文件会以正常方式打开(即使用 open() 并且不带任何解压操作);
使用示例: fi = fileinput.FileInput(openhook=fileinput.hook_compressed)
2、fileinput.hook_encoded(encoding, errors=None)
返回一个通过 open() 打开每个文件的钩子,使用给定的 encoding 和 errors 来读取文件。
使用示例: fi = fileinput.FileInput(openhook=fileinput.hook_encoded(“utf-8”, “surrogateescape”))
示例实战
假如我想要使用 fileinput 来读取网络上的文件,思路:
先使用 requests 下载文件到本地;
再使用 open 去读取它。
def online_open(url, mode):
import requests
r = requests.get(url)
filename = url.split("/")[-1]
with open(filename,'w') as f1:
f1.write(r.content.decode("utf-8"))
f2 = open(filename,'r')
return f2直接将这个函数传给 openhook 即可:
# -*- coding:utf-8 -*- # @Time : 2022-07-23 # @Author : carl_DJ import fileinput file_url = 'https://www.csdn.net/robots.txt' with fileinput.input(files=(file_url,), openhook=online_open) as file: for line in file: print(line, end="")
代码整合:
# -*- coding:utf-8 -*-
# @Time : 2022-07-23
# @Author : carl_DJ
def online_open(url, mode):
import requests
r = requests.get(url)
filename = url.split("/")[-1]
with open(filename,'w') as f1:
f1.write(r.content.decode("utf-8"))
f2 = open(filename,'r')
return f2
import fileinput
file_url = 'https://www.csdn.net/robots.txt'
with fileinput.input(files=(file_url,), openhook=online_open) as file:
for line in file:
print(line, end="")运行结果:

总结
关于fileinput的介绍,也就介绍到这里。
fileinput本身是对 open 函数的再次封装,所以在读取的cc部分,就比open显得更专业,更优雅,这也是仅限于读取的方面。
在写的方面,相对于open,就不是那么的强悍。
归根结底,fileinput还是一个不错的方法。值得你拥有。
作者:佚名
- -1.00 查看剩余0%
- 【留下美好印记】赞赏支持

热门文章
最新讲堂
- 推荐阅读
- 换一换
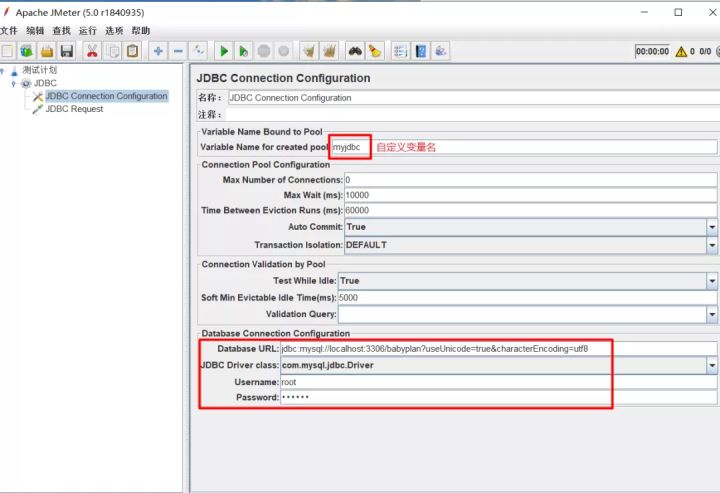
- 有部分数据直接插入数据库是不可以的,需要加密处理,例如密码都指定为加密后的数据字符串。今天我们来学习一下如何利用JMeter生成加密数据并写入MySQL数据库中。如何JMeter如何连接数据库,可以看我之前写的随笔,JMeter接口测试-JDBC测试。一:添加线程组,再添加JDBC Connection Configuration(右键测试计划-->配置元件-->JDBC Connection Configuration),并配置数据库连接信息二:导入mysql驱动包,下载好mysql的驱动包(mysql-connector-java-5.1.22-bin.jar),放到jmete...
-
- Jmeter接口测试方法——软件测试圈05-20Jmeter脚本编写一般分为五个步骤:添加线程组添加http请求在http请求中写入接入url、路径、请求方式和参数添加查看结果树调用接口、查看返回值设置HTTP请求默认值在有多个请求时,每个请求都需要选择http协议,填写服务器名称或者服务器ip地址,比较重复和麻烦,所以可以定义一个http请求默认值,设置所有的请求默认使用http协议,默认服务器名称或服务器ip地址。在线程组–添加–配置元件–HTTP请求默认值,然后进行配置,并把该元件放置到请求前面。协议:http服务器名称或ip:httpbin.org断言设置针对每个请求的响应进行断言,设置步骤:选中一个请求–添加–断言–响应断言参数设...
- 银行金融容器云基础设施创新实践——软件测试圈09-26【摘要】随着互联网金融的兴起,互联网企业依托互联网,特别是移动互联网为公众提供越来越多方便快捷、稳定高效的金融类服务,对传统的银行业务带来了很大冲击。作为应对,传统银行也在业务上不断创新,带来对IT基础设施和应用架构方面进行转型升级的要求,譬如银行内部的业务系统在开发、测试、部署、以及运维还以传统模式为主,无法满足业务创新要求的快速、弹性、敏捷等特性,同时也缺少整合、高效的基础设施平台支撑。近年云计算技术发展和云原生技术的不断迭代演进,云原生产品能力也在不断成熟和完善,云原生架构逐渐成为传统银行的IT架构选型方向。传统银行基于云原生技术建设并推广适合自身的容器云平台,实现传统应用迁移上云和云原...
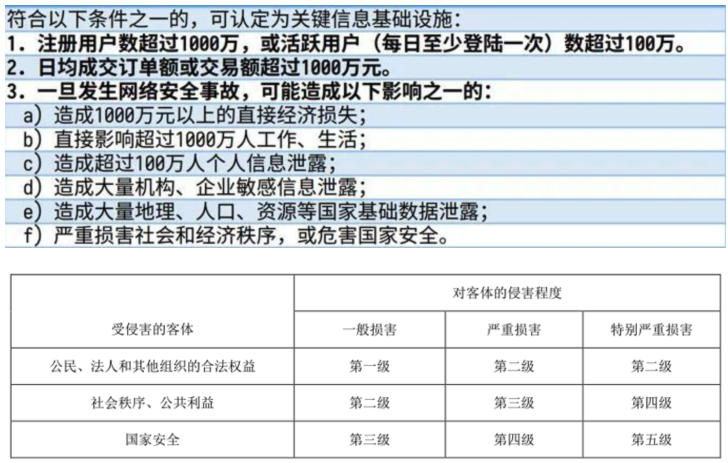
- 一.背景介绍 继自动提交bug到jira文章之后,这时候就会有人有疑问了,我每天都在跑自动化测试(美其名曰每日构建),也每天都在自动提交bug,可能昨天提交的bug尚未解决,今天又重新提了一遍,一周下来累计的bug好几千了,怎么办?一个个去手动过滤,有木有感觉直接崩溃了?那么为了解决这个问题,今天我们就来介绍一个自动化过滤的方案及其实践。 二.测试需求分析 此方案也主要使用python/pytest实现,主要针对于jira上bug的处理,当然也可以使用过滤重复需求,重复任务等等均可以。 准备工作: 1.在处理之前,你首先需要了解部门的jira流转图(不同公司或部门都可能不一样),...
-
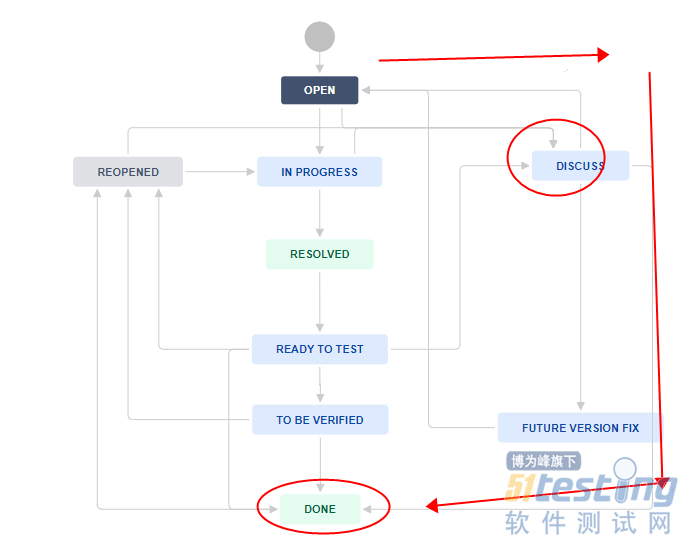
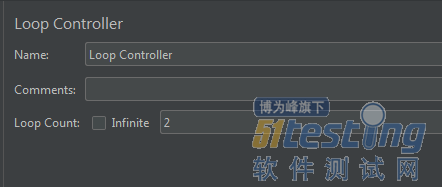
- 在真实的压测过程中,我们不可能是录制完脚本直接就设置虚拟用户进行压测,通常为了使压测结果更加真实,我们还需要做一些修改,其中就用到了逻辑控制器,下面具体来讲一下几种常用的逻辑控制器的使用。 Loop Controller(循环控制器) 使用场景:如果录制的一个脚本中,我只想对其中的一个或者几个请求进行循环操作,但是登录请求只想执行一次,那么应该怎么办? 添加循环控制器即Loop Controller: 在这里设置Controller里请求的循环次数: 这样我们在执行脚本的时候,该循环控制器下面的所有请求都会请求两遍,而登录操作只会执行一遍,执行结果如下: While Contr...
-


,并配置数据库连接信息二:导入mysql驱动包,下载好mysql的驱动包(mysql-connector-java-5.1.22-bin.jar),放到jmete...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=145538&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=145538&pic=http://quan.51testing.com/ueditor/php/upload/image/20221031/1667193154282911.jpg){kind=link}
{kind=link}
,也每天都在自动提交bug,可能昨天提交的bug尚未解决,今天又重新提了一遍,一周下来累计的bug好几千了,怎么办?一个个去手动过滤,有木有感觉直接崩溃了?那么为了解决这个问题,今天我们就来介绍一个自动化过滤的方案及其实践。 二.测试需求分析 此方案也主要使用python/pytest实现,主要针对于jira上bug的处理,当然也可以使用过滤重复需求,重复任务等等均可以。 准备工作: 1.在处理之前,你首先需要了解部门的jira流转图(不同公司或部门都可能不一样),...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=144282&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=144282&pic=http://quan.51testing.com/ueditor/php/upload/image/20211126/1637891112721602.png){kind=link}
详解——软件测试圈》& 在真实的压测过程中,我们不可能是录制完脚本直接就设置虚拟用户进行压测,通常为了使压测结果更加真实,我们还需要做一些修改,其中就用到了逻辑控制器,下面具体来讲一下几种常用的逻辑控制器的使用。 Loop Controller(循环控制器) 使用场景:如果录制的一个脚本中,我只想对其中的一个或者几个请求进行循环操作,但是登录请求只想执行一次,那么应该怎么办? 添加循环控制器即Loop Controller: 在这里设置Controller里请求的循环次数: 这样我们在执行脚本的时候,该循环控制器下面的所有请求都会请求两遍,而登录操作只会执行一遍,执行结果如下: While Contr...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=143864&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=143864&pic=http://quan.51testing.com/ueditor/php/upload/image/20210713/1626140826188190.png){kind=link}
- 关于我们 联系我们 版权声明 广告服务 站长统计
- 建议使用IE 11.0以上浏览器,800×600以上分辨率,法律顾问:上海兰迪律师事务所 项棋律师
- 版权所有 上海博为峰软件技术股份有限公司 Copyright©51testing.com 2003-2024, 沪ICP备05003035号
- 投诉及意见反馈:webmaster@51testing.com; 业务联系:service@51testing.com021-64471599-8017

- 51testing软件测试圈微信