 0
0 0
0


- 【优分享】JMeter源码解析之结果收集器
本文作者 优测性能测试专家高源。
简介:本文以最新的JMeter 5.5版本源代码为例详细介绍了单机模式和分布式模式下结果收集器的工作原理。通篇干货,还不快来了解一下!
一、JMeter结果收集器概述
JMeter是在压力领域中最常见的性能测试工具,由于其开源的特点,受到广大测试和开发同学的青睐。但是,在实际应用过程中,JMeter存在的一些性能瓶颈也凸显出来,经常会遇到大并发下压不上去的情况。笔者通过深入分析其源码实现,找到JMeter存在的瓶颈问题及根本原因,为以后更好地使用工具提供一些思路。
结果收集器:在JMeter中担任报告数据收集的重任,无论是单机模式还是master-slave模式,每一个请求的结果都是通过相应的结果收集器进行数据采集的。在单机模式下用Result Collector这个监听器去采集,在分布式(master-slave)场景下通过配RemoteSampleListenerWrapper下的指定sender进行收集,具体配置jmeter.property文件的mode属性和队列长度实现。下面我们以当前最新的JMeter 5.5版本的源代码为例详细介绍下单机模式和分布式模式下结果收集器的工作原理。
二、单机模式
1、初始化
在命令行模式下,JMeter会根据用户的logfile配置选择是否添加Result Collector,一般在实际测试的时候,我们都是需要有详细统计报告生成的,所以都会添加Result Collector,收集器放在了整个hashtree的第一个节点,代码如下:
void runNonGui(String testFile, String logFile, boolean remoteStart, String remoteHostsString, boolean generateReportDashboard){
....
ResultCollector resultCollector = null;
if (logFile != null) {
resultCollector = new ResultCollector(summariser);
resultCollector.setFilename(logFile);
clonedTree.add(clonedTree.getArray()[0], resultCollector);
}
else {
// only add Summariser if it can not be shared with the ResultCollector
if (summariser != null) {
clonedTree.add(clonedTree.getArray()[0], summariser);
}
}
....
}
2、加载流程
添加完结果收集器后,执行脚本过程中,JMeter会根据jmx的编排,按照如下的执行顺序进行调用:

每一个线程都是按照以上的顺序循环反复执行,直到压测停止。具体代码如下(相应的关键点已增加注释):
private void executeSamplePackage(Sampler current,
TransactionSampler transactionSampler,
SamplePackage transactionPack,
JMeterContext threadContext) {
threadContext.setCurrentSampler(current);
// Get the sampler ready to sample
SamplePackage pack = compiler.configureSampler(current);
runPreProcessors(pack.getPreProcessors());//运行前置处理器
// Hack: save the package for any transaction controllers
threadVars.putObject(PACKAGE_OBJECT, pack);
delay(pack.getTimers());//定时器timer
SampleResult result = null;
if (running) {
Sampler sampler = pack.getSampler();
result = doSampling(threadContext, sampler);
}
// If we got any results, then perform processing on the result
if (result != null) {
if (!result.isIgnore()) {
...
runPostProcessors(pack.getPostProcessors());//运行后置处理器
checkAssertions(pack.getAssertions(), result, threadContext);//运行断言处理器
// PostProcessors can call setIgnore, so reevaluate here
if (!result.isIgnore()) {
// Do not send subsamples to listeners which receive the transaction sample
List<SampleListener> sampleListeners = getSampleListeners(pack, transactionPack, transactionSampler);
notifyListeners(sampleListeners, result);//执行监听器,此处为执行报告收集器的sampleOccurred方法
}
compiler.done(pack);
...
}
收集器Result Collector执行的具体代码:
@Override
public void sampleOccurred(SampleEvent event) {
SampleResult result = event.getResult();
if (isSampleWanted(result.isSuccessful())) {
sendToVisualizer(result);
if (out != null && !isResultMarked(result) && !this.isStats) {
SampleSaveConfiguration config = getSaveConfig();
result.setSaveConfig(config);
try {
if (config.saveAsXml()) {
SaveService.saveSampleResult(event, out);
} else { // !saveAsXml
CSVSaveService.saveSampleResult(event, out);
}
} catch (Exception err) {
log.error("Error trying to record a sample", err); // should throw exception back to caller
}
}
}
if(summariser != null) {
summariser.sampleOccurred(event);
}
}
以上主要实现了将每个请求的结果数据存储到日志文件中(CSV /XML),为后续的报告生成提供数据文件。
3、性能瓶颈分析
从以上的流程不难看出,由于每个线程的每个请求后都会频繁调用Result Collector的sample Occurred方法,即会频繁读写文件,有可能导致IO瓶颈。一旦存储的速度下降,必然导致线程循环发包的速度下降,从而导致压不上去的情况出现。所以单机模式下不建议设置超过200以上的并发,若非必须,尽量关闭日志采集和html报告生成,以免报告置信度存在问题。
三、分布式模式
为了应对单机的各种瓶颈问题,JMeter采用了分布式(master-slave)模式。加载执行流程与单机基本一致,不再赘述,区别在于监听器换成了Remote Sample ListenerImpl收集器。
1、发送模式指定方法
下面我们重点看下Remote Sample ListenerImpl监听器的代码:
@Override
public void processBatch(List<SampleEvent> samples) {
if (samples != null && sampleListener != null) {
for (SampleEvent e : samples) {
sampleListener.sampleOccurred(e);
}
}
}
@Override
public void sampleOccurred(SampleEvent e) {
if (sampleListener != null) {
sampleListener.sampleOccurred(e);
}
}
从以上代码可以看出,这个监听器里又调用了sample Listener的sample Occurred方法,而sample Listener是通过用户在jmeter.property文件中指定的。

2、AsynchSampleSender源码解析
下面我们以Asynch Sample Sender为例进行源码详细介绍:
public class AsynchSampleSender extends AbstractSampleSender implements Serializable {
protected Object readResolve() throws ObjectStreamException{
int capacity = getCapacity();
log.info("Using batch queue size (asynch.batch.queue.size): {}", capacity); // server log file
queue = new ArrayBlockingQueue<>(capacity);
Worker worker = new Worker(queue, listener);
worker.setDaemon(true);
worker.start();
return this;
}
@Override
public void testEnded(String host)
log.debug("Test Ended on {}", host);
try {
listener.testEnded(host);
queue.put(FINAL_EVENT);
} catch (Exception ex) {
log.warn("testEnded(host)", ex);
}
if (queueWaits > 0) {
log.info("QueueWaits: {}; QueueWaitTime: {} (nanoseconds)", queueWaits, queueWaitTime);
}
}
@Override
public void sampleOccurred(SampleEvent e)
try {
if (!queue.offer(e)){ // we failed to add the element first time
queueWaits++;
long t1 = System.nanoTime();
queue.put(e);
long t2 = System.nanoTime();
queueWaitTime += t2-t1;
}
} catch (Exception err) {
log.error("sampleOccurred; failed to queue the sample", err);
}
}
private static class Worker extends Thread {
@Override
public void run()
try {
boolean eof = false;
while (!eof) {
List<SampleEvent> l = new ArrayList<>();
SampleEvent e = queue.take();
// try to process as many as possible
// The == comparison is not an error
while (!(eof = e == FINAL_EVENT) && e != null) {
l.add(e);
e = queue.poll(); // returns null if nothing on queue currently
}
int size = l.size();
if (size > 0) {
try {
listener.processBatch(l);
} catch (RemoteException err) {
if (err.getCause() instanceof java.net.ConnectException){
throw new JMeterError("Could not return sample",err);
}
log.error("Failed to return sample", err);
}
}
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
log.debug("Worker ended");
}
}
}
从以上代码可以看出,Asynch SampleSender的sample Occurred方法里只进行入列的操作,而采集上报工作是启动了一个work线程实现的,相当于异步处理所有请求数据。这样设计不会阻塞发包的流程,性能上要优于单机模式。但是,在一定情况下,也是会出现性能瓶颈的。
这个队列采用的是Array Blocking Queue(阻塞队列),这个队列有如下特点:
·Array Blocking Queue是有界的初始化必须指定大小,队列满了后,无法入列。
·Array Blocking Queue实现的队列中的锁是没有分离的,即添加操作和移除操作采用的同一个Reenter Lock锁。
3、性能瓶颈分析
瓶颈点一:队列大小问题
当我们实际压测过程中,如果队列大小(asynch.batch.queue.size)设置过小,入列速度大于出列速度,就会导致队列满而阻塞整个发压流程,而如果队列设置过大,一旦请求的包体比较大,很容易造成内存溢出。
瓶颈点二:单一锁问题
在压测过程中,入列出列是非常频繁的,而同一个Reenter Lock锁也可能造成入列和出列过程中,因无法获得锁而入列或者出列延迟,继而影响发压效率。
四、总结
JMeter因其完善的社区和开源特点,在日常压测中可广泛使用。JMeter适合进行小规模的压测。但是在大规模的压测过程中,受本地机器性能、带宽等限制,不宜进行单机压测,可以使用JMeter的master-slave的方式进行分布式压测。但是需提前设置好结果收集器和队列的大小,并进行预先演练评估出上限qps,防止出现压不上去的情况。此外,master-slave通信方式是远程RMI的双向通信方式,连接数过多也会造成master的瓶颈出现,需要做好量级的提前评估。
*版权声明:本文作者 优测性能测试专家高源。
- -1.00 查看剩余0%
- 【留下美好印记】赞赏支持

热门文章
最新讲堂
- 推荐阅读
- 换一换
- 材料收集 你服务于一个数据库查询业务,某次客户现场反馈查询某个语句长时间未返回结果,耗时已经远远超过项目对外提供的性能报告承诺给用户最长查询时间。 问题和相关日志已经传递回来,开发人员进行原因分析和故障修复,测试人员进行故障复盘和测试改进。 这一切看起来都在正常的进行下去,但是作为测试人员的你是不是会不自主地冒出这么一句:为什么我没有测试出来呢? 那么,为什么会没有测试出来呢? 故障复盘 “没有测试出来”剖析最根本的原因无非可能有两点: 1、缺少对应的测试用例; 2、具有相应的测试用例,但测试环境与客户现场相差太大。 那么,你可能还会继续问自己:为什么会缺少对应的测试用例...
-
- 要时刻牢记自己擅长什么,不擅长什么,不要什么都想要。说起来简单,做起来难啊~记得小时候,我太姥姥经常说,“难活的人,难活的人哪~”那个时候不太理解,也不认同,只是牢记了这么句话,现在随着年龄的增长,人生阅历的累积,慢慢越来越认识到太姥姥的智慧啊~老太太活到100多岁哪~人为什么难活?我觉得就是生活的环境中,人心最复杂,最多变,最善变。尤其是自己的心,最难守。经常会忘了自己为什么出发,到底要到哪里去。经常忘记自己最擅长什么,最不擅长什么,什么都想要。以为世界之大,自己什么都能改变。慢慢碰壁多了,就知道自己什么都改变不了,能改变的,只有自己,也只能是自己。对别人的影响,就留给别人去把握吧。别以为自...
-
- 1、添加线程组2、配置http信息头管理;使用json格式传递数据时,必须配置此项;3、添加httpcookie管理器,根据具体情况配置cookie信息,本例中未配置4、配置http请求默认值;同一个项目的接口请求放在一个线程组中,可配置请求默认值,这样无需在各接口请求中单独配置;5、配置http请求,就是具体请求的接口;本例中参数格式为json格式,使用bodydata;6、添加查看结果树,可查看接口执行情况整体的可看聚合报告Label:每个JMeter的element(例如HTTPRequest)都有一个Name属性,这里显示的就是Name属性的值#Samples:表示你这次测试中一共发出...
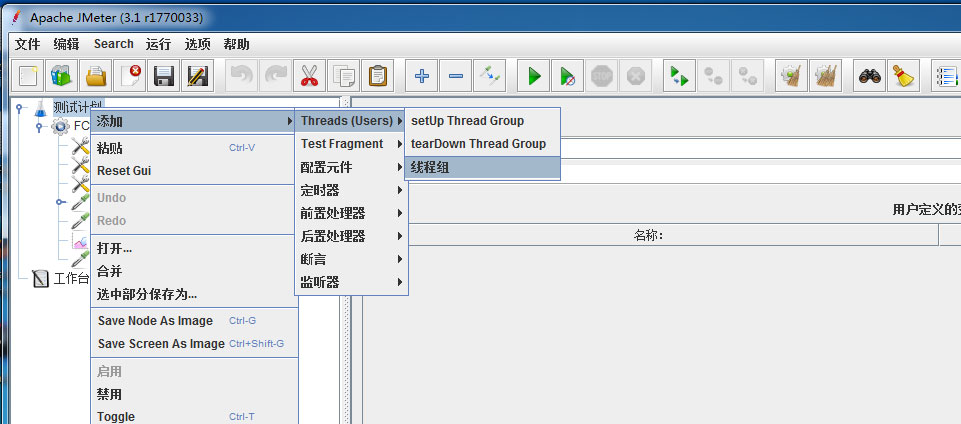
-
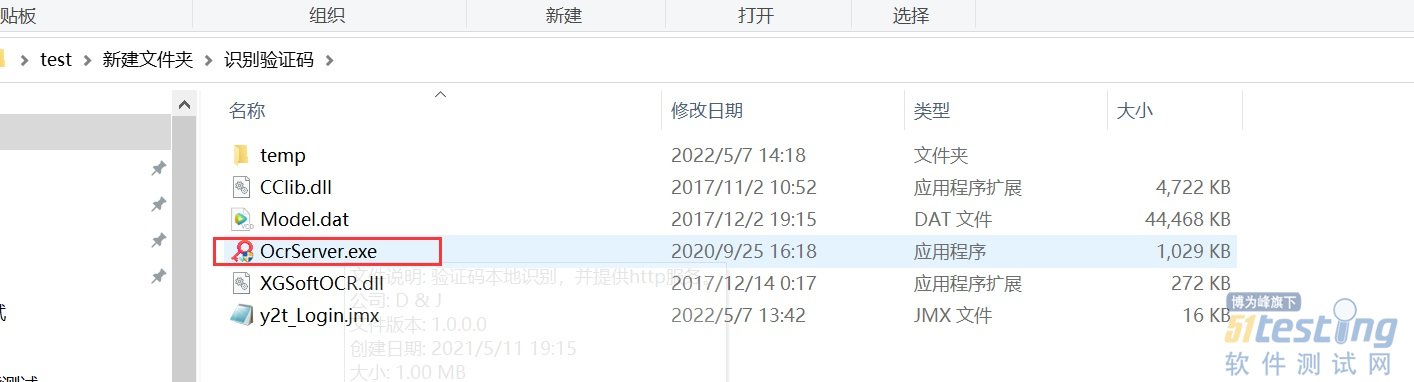
- Jmeter对图片验证码的处理——软件测试圈06-13jmeter对图片验证码的处理 在web端的登录接口经常会有图片验证码的输入,而且每次登录时图片验证码都是随机的;当通过jmeter做接口登录的时候要对图片验证码进行识别出图片中的字段,然后再登录接口中使用; 通过jmeter对图片验证码的识别方法 1、通过ocrserver工具识别图片验证码 如下图:解压后双击OcrServer.exe;然后电脑的右下角会显示该服务的IP和端口。 2、在jmeter中发送获取该验证码图片的接口;如下图 3、在获取验证码图片的接口下面添加监听器》保存响应到文件;如下图: 4、再取样器中再添加JSR223 Sampler;注释一下该...
- 浅谈一下前端单元测试——软件测试圈08-19关于单元测试这个概念,我想很多前端的小伙伴都知道,但是却并不一定能描述清楚。由于我开始接触单元测试还是在四个月前,当时也只是做了一些纯函数的单元测试。所以在这里只能说浅谈一下前端单元测试。什么是单元测试?我理解的单元测试就是用于测试一个模块能否到达预期效果。通过代码来定义一个可用的衡量标准,并且可以快速检验。为什么要做单元测试?随着前端的快速发展,各类框架层出不穷,前端实现的业务逻辑也越来越复杂,这时单元测试的作用就凸显出来了。其实目前为止还是有很多代码是缺少单测的,只是现在单测的重视程度越来越高了而已。单测的好处不言而喻,首先可以提高代码的正确性,在上线前做到心里有底。其次当代码需要重构时,...





》&1、添加线程组2、配置http信息头管理;使用json格式传递数据时,必须配置此项;3、添加httpcookie管理器,根据具体情况配置cookie信息,本例中未配置4、配置http请求默认值;同一个项目的接口请求放在一个线程组中,可配置请求默认值,这样无需在各接口请求中单独配置;5、配置http请求,就是具体请求的接口;本例中参数格式为json格式,使用bodydata;6、添加查看结果树,可查看接口执行情况整体的可看聚合报告Label:每个JMeter的element(例如HTTPRequest)都有一个Name属性,这里显示的就是Name属性的值#Samples:表示你这次测试中一共发出...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=144027&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=144027&pic=http://quan.51testing.com/ueditor/php/upload/image/20210824/1629785249154756.jpg){kind=link}
{kind=link}
{kind=link}
- 关于我们 联系我们 版权声明 广告服务 站长统计
- 建议使用IE 11.0以上浏览器,800×600以上分辨率,法律顾问:上海兰迪律师事务所 项棋律师
- 版权所有 上海博为峰软件技术股份有限公司 Copyright©51testing.com 2003-2024, 沪ICP备05003035号
- 投诉及意见反馈:webmaster@51testing.com; 业务联系:service@51testing.com021-64471599-8017

- 51testing软件测试圈微信