 0
0 0
0


- 测试用例的一些“真相”与“事实”——软件测试圈
测试用例存在一些真相与事实,有些广为人知,有些却很隐蔽。正是基于这些真相与事实,可以对我们的手工测试、自动化测试、甚至规模化的自动化测试(数以万计的用例)带来不同的启发。
真相1:不能提前确定所需要的所有测试用例
测试领域有一个几乎是共识的结论,我们不能完全测试(Complete Test)。除了这个结论本身,其原因也有很大的参考价值:
软件系统本质也是一系统,是由一层层依赖组成的,当我们想测某一点时,总会有假设,但是这个假设本身有时也需要另外的用例来覆盖。而哪一层的假设是可靠、不需要再测试的判断往往是凭个人经验决定的,也许离真实很远。
瀑布流程中的测试用例规划通常是基于规格的,较少考虑“人”的因素。现在我们已经知道,针对同一个需求,由不同的开发实现后质量是不一样的,从而用来验证和评估软件的质量的用例集也应该是不一样的,这也是探索性测试的切入点之一。
客观规律是,对事物的认知需要一个过程,也就是哪怕将测试问题锁定在某一个层次、用例大小确定在某一粒度,我们也不一定能一次性确定需要的用例集。曾经有一个尝试,让不同的测试专家对三角形测试问题给出用例(即给出的a、b、c的长度能否组成三角形),实际结果是得到的用例数从几十到上百不等。
给我们的启示就是测试设计基本不可能“一劳永逸”,我们需要时刻对待测系统出错的方式保持警惕、以及针对性的测试设计。
真相2:不一定能“如实”地写下所想到的用例
想象你给某片树林拍了一张照片,聚焦在其中的某一颗树。现在请回忆并描述你的照片,大概率你会比较准确地刻画出那颗树的形态,同时也会大概率不知道它的旁边还有多少其它树、树下的草地的颜色、是否有鸟等信息。同样地,我们在设计用例时,通常也是在关注其中一个测试点的同时,就也会忽略其它一些信息。有时即使想“面面俱到”地测试这整个风景,但信息量的膨胀也会使我们妥协、甚至放弃,导致最终写下来的用例只是设想的一部分,即那一顆树。一个用例能记录下来的信息量通常并不能反映测试设计人员脑海中全部的信息,信息丢失在此不可避免。
真相3:不一定能“如实”地执行所写下的用例
如果细分,用例其实有两种形态:抽象用例、实例化用例。简单来讲,抽象用例是以抽象的方式描述了前提条件、步骤与结果,里面涉及的测试数据比如用户都只是一个抽象表达,暂时与某测试环境没有关联。实例化用例则是在执行时,用例里面的数据与场景与实际的测试环境发生了关联,比如用户的id将不再是抽象表达,而是实实在在的系统存在值,比如某UUID值。
根据经验,抽象用例并不一定能转化为实例化用例,业务可能的变化、真实测试环境的限制等都可能是导致转化失败的因素。从而可能的后果就是实际执行的用例、用例集与设计时的用例、覆盖期望存在差距。
真相4:用例的设计人员、执行人员分开,可能会带来虚假的安全感
更进一步,如果用例设计人员与执行人员不是同一人会发生些什么呢?根据上面的真相2、真相3的讨论,信息的丢失会一定程度地存在着。但是比这个问题更严重的是,设计人员认为他已经完成针对问题的测试分析、设计工作,理论上的覆盖率已经达到。同时设计人员不参与后续的执行工作,则对软件可能的变化将得不到及时的反馈,时间一长,设计的用例集也许和产品需要的用例集相差会很大。另一方面,对执行人员来说,因为有一个用例集存在,他们的第一要务是完整地执行它们。过去的实践表明,专注于执行的测试人员评估自己的工作是以已执行完成的用例百分比来衡量的。他们对当前用例集是否是合适的,是否需要根据实际情况在某方面增加新的用例等思考却相对较少。
从而我们看到,如果用例设计人员、执行人员分开,由于他们评估自己的工作的方式的不同特点,将导致的一种可能状况就是,他们对各自的工作都比较满意,可是最终映射到产品、系统的测试效果并不理想。
真相5:从用例设计到用例执行的间隔越长,效果越差
我们可以说用例本身只是一个计划、一个意图,只有基于它与待测系统真正交互后才算完成一个测试闭环。周期越长,反馈环就越长,从而单位时间内通过用例得到的信息就可能更少。从上面的讨论我们还看到,用例从在脑海中构思、到记录、到实际执行,存在着信息损失。尽可能地加快整个测试环,才能一程度弥补用例生命周期中各环节的信息损失。
真相6:客户(最终用户)给出的用例(场景)价值很高
开发、测试团队通常基于BA整理的需求和场景分析、设计用例是一个很自然的选择。QA会实施各类分析技术得到用例集,但这通常也是基于BA的业务输入和基于开发的技术选型,实践上会存在认识偏差和识别用例优先级排序困难等。而这恰恰是客户用例、场景输入的有价值的地方,尤其一些场景是客户自身的“痛的领悟”。对一个已经生产运维的系统,客户测试团队的用例集、甚至运维团队的缺陷集都是高价值输入。
真相7:用例的“前提条件”的满足是需要代价的
在真相3里我们提到抽象用例和实例化用例,以及一个用例所包含的基本元素:前提条件、测试步骤、期望结果。比如一个场景,用户搜索产品、添加到购物车、提交订单、取消订单,如果一个用例关注在订单的取消,其前提条件是一个已提交的订单待取消。那么问题来了,这个已提交的订单是怎么来的呢?在写用例时我们可以以几秒钟的代价写下“前提:系统存在已提交的订单待取消”。可是到了实际执行时,尤其是手工执行,也许这个取消测试步骤本身只需要1分钟,但是这个前提却需要10分钟,即前提的准备代价数倍于当前用例的主要执行点 。
给了我们什么启示呢?主要是提醒测试人员,请注意“想得到却做不到”的陷阱。虽然在设计用例时,我们可以基于逻辑写下这个用例,但却不一定真的能测它或者测试它的代价非常大。尤其是一些负向的测试,比如网络状态模拟等。同时这个现实给了我们另外的思考契机,就是怎么去平衡这个代价。考虑上面的订单例子,前提条件至少有以下几种方式得到满足:
· 用SQL的方式向数据库插入(但数据不一定合法)
· 生产环境数据脱敏后Copy至测试环境,从中寻找合适的订单
· 直接通过UI,按照用户真实的流程生成订单并提交(合法但效率不高)
· 通过API的方式,调用对应的API生成订单并提交
显然,它们各有优缺点,我们需要考虑它的效率、以及对真实业务过程的还原程度。
真相8:(业务)用例本质都是“E2E”
现在我们提到E2E(End to End)一般认为它是与用户验收测试(UAT)相关,即去覆盖真实用户有用户场景从头到尾。UAT与系统测试(ST)的区别是什么呢?以上文中的订单场景为为例,ST上下文的取消订单不会关心这个订单是从哪来的,但是UAT场景中确要确保这个订单是之前的用例通过用户合法操作得到的。ST和UAT的不同是多方面的,恰恰这一点较少被关注到。既然ST的订单可以通过合法操作得到,为什么还要用不那么合法的SQL方式直接插入呢?这其实是用例执行时的效率问题,一般认为UI的方式慢且不稳定。换言之,这是一个妥协,如果我们有更好的方式在保证操作合法的同时又能确保效率,我们就不需要这种妥协。由此,从逻辑层面,我们可以得到这样一个结论,一个用例循着前提条件,就能“追溯”到当前场景的起点,用例尤其是业务用例的本质都是E2E的(第一个E是场景的起点,第2个E是当前的测试点)。
正确认识这个E2E真相、以及承认用SQL这样非业务方式直接写入是一种执行层面“妥协”非常重要,它会让我们重新思考当前的一些“理所当然”的实践,其出发点、收益、风险,从而改进与提高。
真相9:增量(迭代)开发模式中,回归用例集其实很重要
我们一般都会认同回归测试很重要,但要真正做好回归测试并不容易。回归什么、想达到的目的是什么、效率怎样都是回归过程中需要认真对待的问题。
在瀑布的流程中,回归测试一般是以一个单独的测试阶段而存在的。它有自己的资源分配、准入、准出。 迭代开发中,至少在实践Scrum的团队中,没有明确有回归这么一个阶段存在。引出的问题就是我们应该 在敏捷中怎样来对待回归测试呢,它是一个阶段、还是一个类型?笔者观察到的敏捷团队的实践中,甚至会出现两个极端的现象。一方面,有团队对有分层次的测试策略,完备的自动化测试,使得一次回归的代价很很低,回归集在持续维护。在重构、新功能引入等情况下,回归可以随时执行,在几分钟内或不超过1小时就完成一次回归,回归以一种测试类型存在而非一个测试阶段。另一方面,也有团队在重构、新功能引入等情况下对回归这件事就“随缘”了,没有回归目标,回归测试是以天为单位的代价存在,且是在一个相对其它开发、测试活动之外一个明显存在的阶段。
从用例的角度看,回归用例集一定程度是代表“回归什么”。没有这个基础,回归测试将是一种无序的、难以评估的方式进行。持续保持回归用例集有效,添加新用例、剔除无效用例等用例集的维护工作很重要,尤其是探索性测试过程中产生的有价值的新用例怎么加入回归用例集。
启示
貌似笔者在上面描述了很多与用例相关的不确定性、甚至不可能性,其实想传递的主要信息就是:
· 对待测试不要盲目乐观和轻视这些问题
· 要正视这些问题,同时看到在解决这些问题时带来的好处
作者:Thoughtworks
- -1.00 查看剩余0%
- 【留下美好印记】赞赏支持

热门文章
最新讲堂
- 推荐阅读
- 换一换
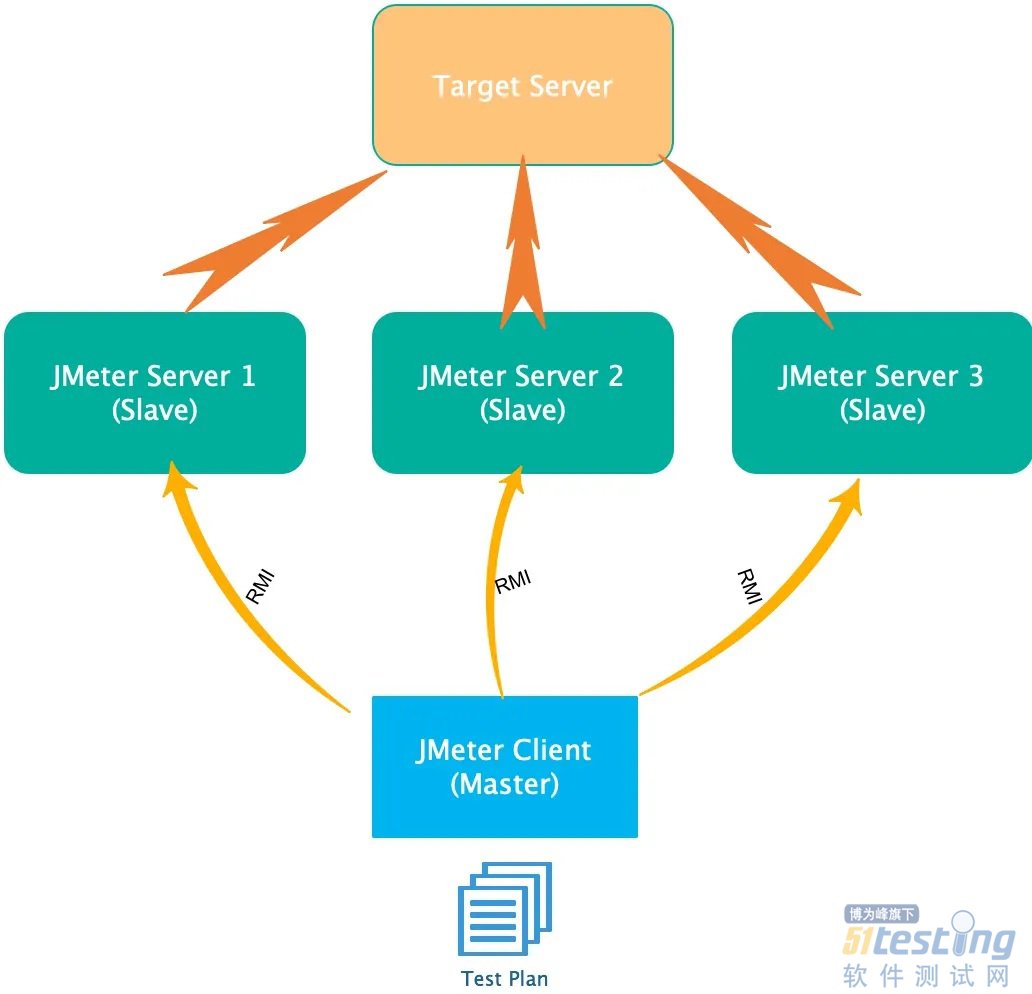
- JMeter是Apache软件基金会的开源项目,主要来做功能和性能测试,用Java编写。 我们一般都会用JMeter在本地进行测试,但是受到单个电脑的性能影响,往往达不到性能测试的要求,无法有效的模拟高并发的场景,那么这个时候,我们就可以借由JMeter提供的Romote Test来进行远程的测试。 其工作方式入下图: 我们可以在多台电脑上,启动JMeter的Romote Testing模式,然后用某一台服务器作为Master端通过RMI控制Slave端来执行我们的测试脚本。当JMeter Slave端执行完测试脚本后,会将执行结果发送回Master控制端进行汇总,得出整体的测试报表...
-
- 美国国家公路交通安全管理局(NHTSA)近日发布调查报告,称过去几年将近 1000 起交通事故和特斯拉的 Autopilot 系统存在关联,而且其中超过 20 起事故导致人员死亡。 报告指出大部分事故都是司机不专心造成的,他们可能错误地认为该公司的驾驶员辅助系统可以充当成熟的自动驾驶方案使用。 报告详细记录了 2018 年 1 月至 2023 年 8 月期间发生的 956 起事故,导致 100 多人受伤、数十人死亡,IT之家附上截图如下: 在本次关联事故中,均为特斯拉的 Autopilot 系统检测到障碍物后几秒后发生的,细心的驾驶员有足够的时间来避免事故或最大程度地减少所遭受的损失...

-
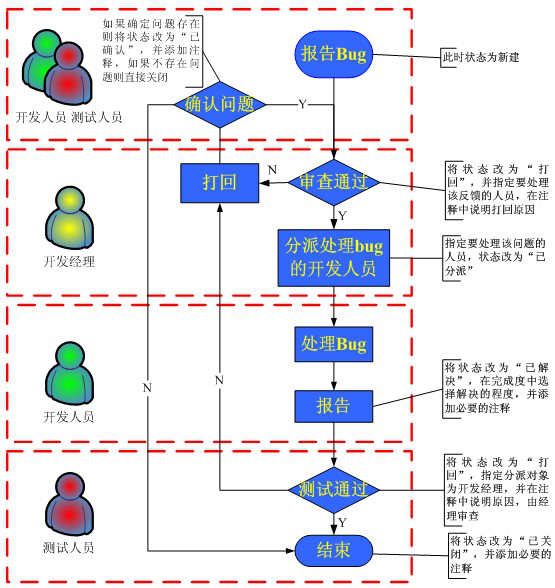
- 几种常见缺陷管理工具——软件测试圈11-22(1)MantisMantis是一个基于PHP技术的轻量级的开源缺陷跟踪系统,其功能与JIRA系统类似,都是以Web操作的形式提供项目管理及缺陷跟踪服务。在功能上可能没有JIRA那么专业,界面也没有JIRA漂亮,但在实用性上足以满足中小型项目的管理及跟踪。Mantis基本功能介绍http://tb.blog.csdn.net/TrackBack.aspx?PostId=作者:龚云卿???? 2005年8月1、简介缺陷管理贯穿于整个软件开发生命周期中, 是不可缺少的环节。Mantis是PHP/MySQL/Web-based缺陷跟踪系统,Mantis当前版本为1.0.0a3。关于产品详细信息和支持...
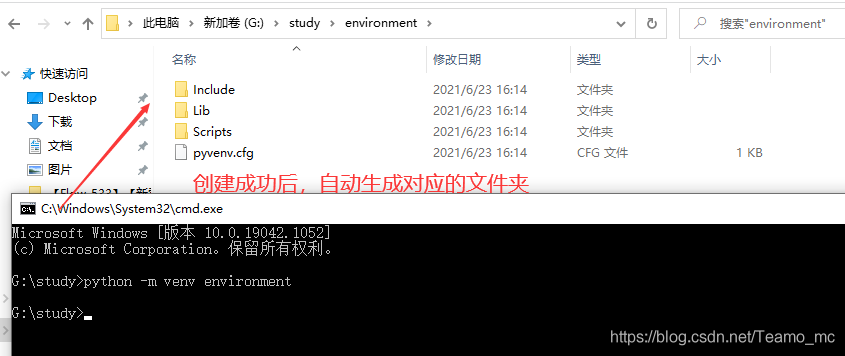
- 今天给大家分享一个“VirtualEnv(虚拟环境)”的概念。在学习RobotFramework时遇到这么一个问题:电脑本地环境已经安装了python3,但是RobotFramework接口测试框架一开始对python3的兼容还不够完全,存在较多的问题,所以需要使用python2环境来开展接口自动化工作。这个时候就遇到python和python3版本造成的环境冲突的问题了。如果卸载python3重新安装python2会导致我原有的其他项目可能出现问题;那么如果直接使用python3环境对应的RobotFramework又存在很多兼容性问题。怎么办?这时候“VirtualEnv(虚拟环境)”的好...
-
- 接口自动化-数据库相关知识——软件测试圈04-01python接口自动化实战目标学习数据库相关,用例增加对数据库校验利用数据库完成对数据查询如何校验数据库数据,怎样添加校验让程序自己校验(充值、提现、投资接口对金额的校验)知识补充用例之间关联性不要太强,比如每个模块的用例都需要登录状态,在每个模块最开始加上一次登录的用例即可。关于登录、充值啥的,用例里面的手机号最好不要写死,万一该手机号数据有脏数据,处理起来会很麻烦,所以一般在用例里面用变量,将数据放在指定的sheet里面方便读取与修改什么接口需要数据库校验?钱的变动、增减数据库安装mysql.connector模块 pip2 install --user mysql-connector基本...

{kind=link}
近日发布调查报告,称过去几年将近 1000 起交通事故和特斯拉的 Autopilot 系统存在关联,而且其中超过 20 起事故导致人员死亡。 报告指出大部分事故都是司机不专心造成的,他们可能错误地认为该公司的驾驶员辅助系统可以充当成熟的自动驾驶方案使用。 报告详细记录了 2018 年 1 月至 2023 年 8 月期间发生的 956 起事故,导致 100 多人受伤、数十人死亡,IT之家附上截图如下: 在本次关联事故中,均为特斯拉的 Autopilot 系统检测到障碍物后几秒后发生的,细心的驾驶员有足够的时间来避免事故或最大程度地减少所遭受的损失...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=146941&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=146941&pic=http://quan.51testing.com/ueditor/php/upload/image/20240428/1714272037154428.jpg){kind=link}
MantisMantis是一个基于PHP技术的轻量级的开源缺陷跟踪系统,其功能与JIRA系统类似,都是以Web操作的形式提供项目管理及缺陷跟踪服务。在功能上可能没有JIRA那么专业,界面也没有JIRA漂亮,但在实用性上足以满足中小型项目的管理及跟踪。Mantis基本功能介绍http://tb.blog.csdn.net/TrackBack.aspx?PostId=作者:龚云卿???? 2005年8月1、简介缺陷管理贯穿于整个软件开发生命周期中, 是不可缺少的环节。Mantis是PHP/MySQL/Web-based缺陷跟踪系统,Mantis当前版本为1.0.0a3。关于产品详细信息和支持...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=144261&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=144261&pic=http://quan.51testing.com/ueditor/php/upload/image/20211122/1637564705364289.png){kind=link}
”的概念。在学习RobotFramework时遇到这么一个问题:电脑本地环境已经安装了python3,但是RobotFramework接口测试框架一开始对python3的兼容还不够完全,存在较多的问题,所以需要使用python2环境来开展接口自动化工作。这个时候就遇到python和python3版本造成的环境冲突的问题了。如果卸载python3重新安装python2会导致我原有的其他项目可能出现问题;那么如果直接使用python3环境对应的RobotFramework又存在很多兼容性问题。怎么办?这时候“VirtualEnv(虚拟环境)”的好...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=145021&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=145021&pic=http://quan.51testing.com/ueditor/php/upload/image/20220717/1658036777737168.png){kind=link}
知识补充用例之间关联性不要太强,比如每个模块的用例都需要登录状态,在每个模块最开始加上一次登录的用例即可。关于登录、充值啥的,用例里面的手机号最好不要写死,万一该手机号数据有脏数据,处理起来会很麻烦,所以一般在用例里面用变量,将数据放在指定的sheet里面方便读取与修改什么接口需要数据库校验?钱的变动、增减数据库安装mysql.connector模块 pip2 install --user mysql-connector基本...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=116958&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=116958&pic=http://quan.51testing.com/ueditor/php/upload/image/20210401/1617263133594691.png){kind=link}
- 关于我们 联系我们 版权声明 广告服务 站长统计
- 建议使用IE 11.0以上浏览器,800×600以上分辨率,法律顾问:上海兰迪律师事务所 项棋律师
- 版权所有 上海博为峰软件技术股份有限公司 Copyright©51testing.com 2003-2024, 沪ICP备05003035号
- 投诉及意见反馈:webmaster@51testing.com; 业务联系:service@51testing.com021-64471599-8017

- 51testing软件测试圈微信