 0
0 0
0


- 数据质量测试:测试数据有效性和准确性的方法——软件测试圈
传统上,数据质量被分成6个方面。
准确性:一项信息在多大程度上反映了现实?
完备性:它是否满足你对全面性的期望?
连贯性:存储在一个地方的信息与存储在其他地方的相关数据是否一致?
及时性:当你需要时,你的信息是否可用?
有效性:信息是否有特定的格式、类型或大小?它是否遵循业务规则/最佳实践?
完整性:不同的数据集能否被正确地连接起来,以反映一个更大的画面?关系是否被很好地定义和实施?
这些维度是在对设计数据仓库采取广泛的观点时定义的。考虑了所有定义和收集的数据集,它们之间的关系,以及正确服务于组织的能力。
当我们看一个单一的数据集时,我们的质量考虑就比较“狭窄”:
它不需要完整性,因为其他数据集可能会弥补。
一致性和完整性是不相关的,因为其他数据集没有被考虑。
时效性主要取决于工程管道的运作,而不是数据的质量。
在我们的案例中,问一个数据集是否可以,等于问 “它是否有效和准确?”。
在这篇文章中,我将描述有效性测试,分解准确性测试的概念,并回顾现有的测试框架。
验证:元数据测试
元数据是描述数据的信息,而不是数据本身。例如,如果数据是一个表,元数据可能包括模式,例如列的数量,以及每一列中变量的名称和类型。如果数据是在一个文件中,文件格式和其他描述性参数,如版本、配置和压缩类型可能是元数据的一部分。
测试的定义很直接:对元数据的每个值都有一个期望,这个期望来自于组织的最佳实践和它必须遵守的规定。如果你是一个软件工程师,这种类型的测试非常像一段代码的单元测试。就像单元测试覆盖率一样,可能需要一些时间来创建所有这些测试,但达到高测试覆盖率是可能的。
每当元数据改变时,维护测试也是需要的。当然期望值往往有差距,当我们习惯于在改变代码时更新我们的单元测试时,我们必须愿意投入同样的时间和注意力,在我们的模式演变时维护元数据的验证。
数据准确性的三种类型
类型1:入门级的事实核查
我们收集的数据来自于我们周围的现实,因此它的一些属性可以通过与已知记录的比较来验证,例如:
这个地址是真实的吗?
这是一个活跃的网页吗?
我们是否出售这个名字的产品?
对于价格栏,其数值是否为非负值?
对于一个强制性的字段,它不是空的吗?
值来自于一个给定的范围,所以最小和最大是已知的。
获取验证值通常需要查询另一个能够可靠地提供答案的数据集。这个数据集可以是公司内部的,比如人力资源系统中的雇员记录。以及公司外部的来源,如街道、城市、国家注册数据库等。
一旦获得了验证值,测试本身就是一个简单的比较/包含查询,其准确性仅限于所用的外部数据集的准确性。
这个测试验证了数据本身,而不是其元数据。最好是在收集数据的时候尽可能地进行这种验证,以避免准确性问题。例如,如果数据是由一个人填表收集的,数字表格可以只提供有效的选项。由于这并不总是可能的,建议在获取阶段对数值进行验证。
类型2:设置级别健全性
事实核查是测试单一记录中的一个值。当涉及到大数据时,我们需要测试我们拥有的集合的属性。这个集合可能包括来自某个时间段的数据,来自某个操作系统的数据,ETL过程的输出,或者一个模型。不管它的来源是什么,它作为一个集合都有我们想要验证的特征。这些特征是统计学上的,比如说:
数据预计来自于一个给定的分布。
平均数、方差或中位数的值被预期在一个给定的范围内的概率很高。
统计学测试仍然需要你知道预期,但你的预期现在有了不同的形式。
这个数据来自这个分布的概率够高吗?
这一栏的平均值应该在这个范围内,概率为95%。
想象一下,一张保存着扑克游戏中发给玩家的手牌的表格。在这种情况下,可以预先计算出手牌的预期分布。
我们进行的测试将查看持有发牌手数的那一列的数值,并询问,这组数值来自预期分布的概率是多少?
在这个统计测试中,定义通过/失败的参数将必须是概率性的。如果分布是均匀的,概率小于X%,你会得到一个警报。当然,你宁愿手动检查一个被警告的数据集,也不愿意让一个错误连带着进入你的数据管道。
类型3:基于历史的集合级别的正确性
就像统计准确性测试一样,我们要看的是一组记录的属性。只是在这种情况下,我们没有一个现实世界的真相来源可以依赖。我们有数据集本身的历史:同一个数据集随着时间的推移而演变。
我们可以使用这些历史数据来创建一个数据特征的基线,然后测试今天的新数据集是否与基线一致。
我们可以从历史数据中推断出一些特征的例子。
某一列中数值的期望值和方差。
某一列中数值的分布,如一天中每分钟的事件数量。
寻找数据的特征和它们的预期分布。
预计随着时间的推移,会有一定的季节性,例如黑色星期五的销售高峰,周末的流量较少。
运行异常检测算法,查看特征的历史,看看当前的值是否正常。
学习基线不仅为测试结果增加了概率方面,也为基线值的有效性增加了概率。我们执行与类型2相同的统计测试,但我们对其正确性有一个额外的风险,因为我们所比较的基线只有一定的概率是正确的,因为它是从历史数据中统计推导出来的。
我们还应该进行这个测试吗?如果基线正确的概率足够高,而且你明智地使用了阈值,那么绝对应该。建议你记住,警报系统需要在假阳性和假阴性之间取得平衡。
假阴性:测试失败,而它本应通过。
假阳性:测试通过了,而它应该是失败的。
你应该根据业务需要,以优化所需错误的方式构造你的测试。你会有错误,所以要确保你有你能接受的错误,而且是高概率的。
作者:测试界的飘柔
原文链接:https://blog.csdn.net/m0_67695717/article/details/127321319
- -1.00 查看剩余0%
- 【留下美好印记】赞赏支持

热门文章
最新讲堂
- 推荐阅读
- 换一换
- 软开源了一个Python项目:Playwright,从此又多了一个浏览器自动化工具。之前一直用selenium或splinter。Playwright 可通过单个API自动执行Chromium,Firefox和WebKit浏览器,支持无头浏览器(headless),Linux、macOS、Windows下均可以使用,Playwright提供的自动化技术是绿色的,功能强大,稳定且速度快。Playwright最吸引我的地方在于它可以自己记录你对浏览器的操作,并将这些操作生成可以执行的代码,这简直就是神器,大大提升了浏览器自动化的效率。生成代码只需要执行python -m pla...
-
- 因为车辆的电池隔离装置(pyrotechnic battery disconnect)可能无法正常工作,特斯拉公司在美国启动了部分 2023 年款的 Model 3 和 Model Y 汽车召回工作。 据IT之家了解,这种装置用来在车辆发生碰撞或电池出现问题时,切断高压电池的连接,以保证安全。美国国家公路交通安全管理局(NHTSA) 的安全召回报告指出,这次召回涉及的车辆大约有 26 辆,其中预计有 2% 的车辆安装了有缺陷的电池隔离装置。 NHTSA 的安全召回报告显示,特斯拉公司在 2023 年 4 月 20 日的一次验证测试中,发现了一个无法正常工作的电池隔离装置。特斯拉公司和该...
-
- 小编已经在内测抽奖系统了,快来填问卷、赢礼品吧!链接:http://vote.51testing.com/ (本次礼包好物多多:大容量马克杯、畅销测试书籍) 在初学Python过程中,会遇到这样的概念,一个类下面会有多个方法,有的叫类方法、有的叫静态方法,还有的叫实例方法。当调用他们的时候,不免会有点蒙圈,那么他们之间的区别是什么呢? 和类属性一样,类方法可以进行细致地划分为类方法、实例方法和静态方法。 表象区别就是: 类方法前用@classmethod修饰 静态方法前用@staticmethod修饰 不加任何修饰的就是实例方法(普通方法) 用法区别 ...
-
- 为什么软件测试的岗位需求越来越多?——软件测试圈12-01随着产品的不断升级,软件测试人员在研发团队中的比重越来越大,因为前期发展较晚,所以目前这方面的人才缺口很大。 1、测试人员是保证企业赖以生存的关键; 先来看一个因为测试人员的疏漏能给企业造成巨大损失的案例,最有代表性的就是2019年“拼多多100元无门槛消费券”漏洞,由于项目测试不到位,导致很多用户仅用了0.4元就给自己充值了100元的话费,事件虽发生在半夜,但是拼多多依旧损失严重,网络流传损失金额达200亿元,很多人担心拼多多就此倒闭。 这件事也给了企业重重一击,也让他们认识到测试的重要性,这件事不只是个例,每年企业因为测试没有做到位而造成的损失的事件早已屡见不鲜,也再次印证了测试...
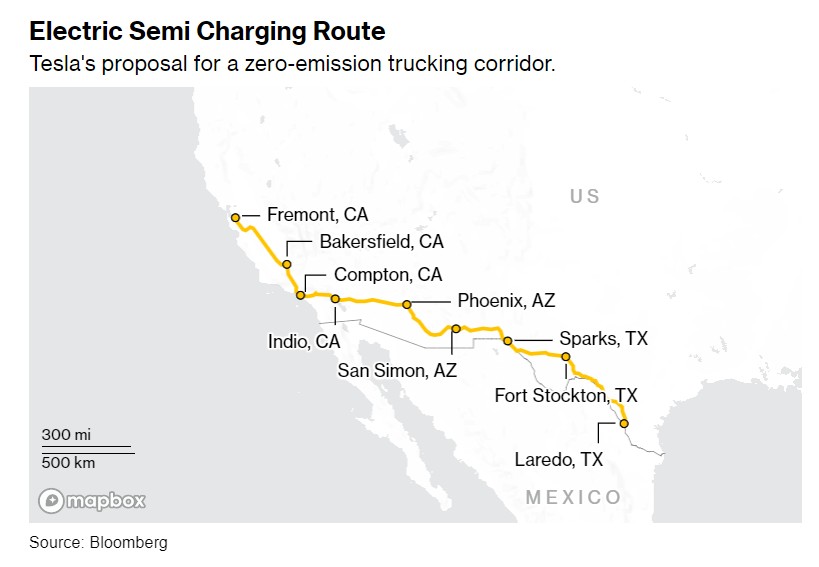
- 有媒体报道称,特斯拉正在向美国州政府寻求近1亿美元的资金,用于在从美国得克萨斯州南部边境到加利福尼亚州北部的一条路线上带头建造9个电动化的半挂卡车充电站。据媒体报道,特斯拉高管在5月至7月初之间写给得克萨斯州交通部的数封电子邮件中表示,该公司建议为特斯拉Semi卡车配备8个750kw的充电桩,为竞争对手生产的卡车配备4个充电桩。 据了解,如果成功获批,这将是美国首个此类充电网络。它将实现从得克萨斯州到加利福尼亚州的长途电气化卡车运输,以及得克萨斯州、亚利桑那州和加利福尼亚州的区域长途卡车运输。美国严重依赖商用卡车运输货物,但一直在努力限制该行业的温室气体排放量。 特斯拉的高管们告诉得州...
-

{kind=link}
{kind=link}
- 关于我们 联系我们 版权声明 广告服务 站长统计
- 建议使用IE 11.0以上浏览器,800×600以上分辨率,法律顾问:上海兰迪律师事务所 项棋律师
- 版权所有 上海博为峰软件技术股份有限公司 Copyright©51testing.com 2003-2024, 沪ICP备05003035号
- 投诉及意见反馈:webmaster@51testing.com; 业务联系:service@51testing.com021-64471599-8017

- 51testing软件测试圈微信