 0
0 0
0


- 数据驱动测试从方法探研到最佳实践——软件测试圈
导读
在自动化测试实践中,测试数据是制造测试场景的必要条件,本文主要讲述了在沟通自动化框架如何分层,数据如何存储,以及基于单元测试 pytest 下如何执行。并通过实践案例分享,提供数据驱动测试的具体落地方案。
基本概念
数据驱动测试(DDT)是一种方法,其中在数据源的帮助下重复执行相同顺序的测试步骤,以便在验证步骤进行时驱动那些步骤的输入值和 / 或期望值。在数据驱动测试的情况下,环境设置和控制不是硬编码的。换句话说,数据驱动的测试是在框架中构建要与所有相关数据集一起执行的测试脚本,该脚本利用了可重用的测试逻辑。数据驱动的测试提供了可重复性,将测试逻辑与测试数据分离以及减少测试用例数量等优势。
设计思路
2.1 测试数据
在测试过程中往往需要更加充分地测试场景,而创建数据测试。测试数据包括输入输出,对输出的自动化验证等。创建测试数据,可以通过手动拼装,生产环境拷贝,或通过自动化工具生成。
2.2 数据存储
数据驱动测试中使用的数据源可以是 Excel 文件,CSV 文件,Yaml 文件,数据池,ADO 对象或 ODBC 源。
2.3 数据驱动优势
1. 如果应用程序开发还在进行当中,测试者仍然可以进行脚本的编写工作。
2. 减少了冗余和不必要的测试脚本。
3. 用较少的代码生成测试脚本。
4. 所有信息,如输入、输出和预期结果,都以适当的文本记录形式进行存储。
5. 为应用程序的维护提供利了灵活性条件。
6. 如果功能发生了变化,只需要调整特定的函数脚本。
实践分享
基于 Laputa 框架现有测试脚本,抽离测试数据与测试逻辑,实现数据驱动测试。
Laputa 框架简介:Laputa 框架基于 Pytest 集成了对 API 接口自动化,以及对 Web 应用,移动端应用和 Windows 桌面应用 UI 等自动化的能力。具有可视化的 Web 界面工具,便于配置执行规则,关联执行脚本, 触发用例执行,查看执行结果。提供 CI 集成服务,调用 Jenkins API 跟踪持续集成结果,开放接口,实现流水线自动化测试。
3.1 环境依赖
3.2.1 参数化配置方式
pytest 参数化有两种方式:
@pytest.fixture(params=[])
@pytest.mark.parametrize()
两者都会多次执行使用它的测试函数,但 @pytest.mark.parametrize () 使用方法更丰富一些,laputa 更建议使用后者。
3.2.2 用 parametrize 实现参数化
parametrize ( ) 方法源码:
【python】 def parametrize(self,argnames, argvalues, indirect=False, ids=None, scope=None):
1. 主要参数说明
(1)argsnames :参数名,是个字符串,如中间用逗号分隔则表示为多个参数名。
(2)argsvalues :参数值,参数组成的列表,列表中有几个元素,就会生成几条用例。
2. 使用方法
(1)使用 @pytest.mark.paramtrize () 装饰测试方法;
(2)parametrize ('data', param) 中的 “data” 是自定义的参数名,param 是引入的参数列表;
(3)将自定义的参数名 data 作为参数传给测试用例 test_func;
(4)在测试用例内部使用 data 的参数。
创建测试用例,传入三组参数,每组两个元素,判断每组参数里面表达式和值是否相等,代码如下:
【python】
@pytest.mark.parametrize("test_input,expected",[("3+5",8),("2+5",7),("7*5",30)])
def test_eval(test_input,expected):
# eval 将字符串str当成有效的表达式来求值,并返回结果
assert eval(test_input) == expected运行结果:
【python】 test_mark_paramize.py::test_eval[3+5-8]test_mark_paramize.py::test_eval[2+5-7] test_mark_paramize.py::test_eval[7*5-35] ============================== 3 passed in 0.02s ===============================
整个执行过程中,pytest 将参数列表 ("3+5",8),("2+5",7),("7*5",30) 中的三组数据取出来,每组数据生成一条测试用例,并且将每组数据中的两个元素分别赋值到方法中,作为测试方法的参数由测试用例使用。
3.2.3 多次使用 parametrize
同一个测试用例还可以同时添加多个 @pytest.mark.parametrize 装饰器,多个 parametrize 的所有元素互相组合(类似笛卡儿乘积),生成大量测试用例。
场景:比如登录场景,用户名输入情况有 n 种,密码的输入情况有 m 种,希望验证用户名和密码,就会涉及到 n*m 种组合的测试用例,如果把这些数据一一的列出来,工作量也是非常大的。pytest 提供了一种参数化的方式,将多组测试数据自动组合,生成大量的测试用例。示例代码如下:
【python】
@pytest.mark.parametrize("x",[1,2])@pytest.mark.parametrize("y",[8,10,11])
def test_foo(x,y):print(f"测试数据组合x: {x} , y:{y}")运行结果:
【python】 test_mark_paramize.py::test_foo[8-1] test_mark_paramize.py::test_foo[8-2] test_mark_paramize.py::test_foo[10-1] test_mark_paramize.py::test_foo[10-2] test_mark_paramize.py::test_foo[11-1] test_mark_paramize.py::test_foo[11-2]
分析如上运行结果,测试方法 test_foo () 添加了两个 @pytest.mark.parametrize () 装饰器,两个装饰器分别提供两个参数值的列表,2 * 3 = 6 种结合,pytest 便会生成 6 条测试用例。在测试中通常使用这种方法是所有变量、所有取值的完全组合,可以实现全面的测试。
3.2.4 @pytest.fixture 与 @pytest.mark.parametrize 结合
下面讲讲结合 @pytest.fixture 与 @pytest.mark.parametrize 实现参数化。
如果测试数据需要在 fixture 方法中使用,同时也需要在测试用例中使用,可以在使用 parametrize 的时候添加一个参数 indirect=True,pytest 可以实现将参数传入到 fixture 方法中,也可以在当前的测试用例中使用。
parametrize 源码:
【python】 def parametrize(self,argnames, argvalues, indirect=False, ids=None, scope=None):
indirect 参数设置为 True,pytest 会把 argnames 当作函数去执行,将 argvalues 作为参数传入到 argnames 这个函数里。创建 “test_param.py” 文件,代码如下:
【python】
# 方法名作为参数
test_user_data = ['Tome', 'Jerry']
@pytest.fixture(scope="module")
def login_r(request):
# 通过request.param获取参数
user = request.param
print(f"\n 登录用户:{user}")return user
@pytest.mark.parametrize("login_r", test_user_data,indirect=True)
def test_login(login_r):
a = login_r
print(f"测试用例中login的返回值; {a}")
assert a != "运行结果:
【plain】 登录用户:Tome PASSED [50%]测试用例中login的返回值; Tome 登录用户:Jerry PASSED [100%]测试用例中login的返回值; Jerry
上面的结果可以看出,当 indirect=True 时,会将 login_r 作为参数,test_user_data 被当作参数传入到 login_r 方法中,生成多条测试用例。通过 return 将结果返回,当调用 login_r 可以获取到 login_r 这个方法返回数据。
3.2.5 conftest 作用域
其作用范围是当前目录包括子目录里的测试模块。
(1)如果在测试框架的根目录创建 conftest.py 文件,文件中的 Fixture 的作用范围是所有测试模块。
(2)如果在某个单独的测试文件夹里创建 conftest.py 文件,文件中 Fixture 的作用范围,就仅局限于该测试文件夹里的测试模块。
(3)该测试文件夹外的测试模块,或者该测试文件夹外的测试文件夹,是无法调用到该 conftest.py 文件中的 Fixture。
(4)如果测试框架的根目录和子包中都有 conftest.py 文件,并且这两个 conftest.py 文件中都有一个同名的 Fixture,实际生效的是测试框架中子包目录下的 conftest.py 文件中配置的 Fixture。
3.3 代码 Demo
测试数据存储 yaml 文件:
【YAML】
测试流程:[
{"name":"B2B普货运输三方司机流程","senior":{"createTransJobResource":"B2B","createType":"三方","platformType":2}},
{"name":"B2B普货运输三方司机逆向流程","senior":{"isback":"True","createTransJobResource":"B2B","createType":"三方","platformType":2}},
]测试数据准备,定义统一读取测试数据方法:
【python】 def dataBuilder(key):dires = path.join(dires, "test_data.yaml") parameters = laputa_util.read_yaml(dires)[key] name = [] senior = [] for item in parameters: name.append(item['name'] if 'name' in item else '') senior.append(item['senior'] if 'senior' in item else '') return name, senior
测试用例标识,通过 @pytest.mark.parametrize 方法驱动用例:
【python】
class TestRegression:
case, param = dataBuilder('测试流程')
@pytest.mark.parametrize("param", param, ids=case)
def test_regression_case(self, param):
# 调度
res = create_trans_bill(params)
trans_job_code = res['data']['jobcode']
carrier_type = params['createType'] if params['createType'] in ('自营', '三方') else '个体'
# 执行
work_info = select_trans_work_info_new(trans_job_code)
trans_work_code = work_info['trans_work_code']
if 'isback' in params and params['isback']:
execute_param.update(isBack=params['isback'])
execute_bill_core(**execute_param)
# 结算
if carrier_type != '自营':
trans_fee_code = CreateTransFeeBillBase.checkTF(trans_job_code)
receive_trans_bill_core(**bill_param)
总结
日常测试过程中,无论是通过手动执行或者脚本执行,都需要利用数据驱动设计思路,这有助于提高测试场景覆盖率,测试用例的健壮性和复用性,及需求测试效率。通过数据驱动测试不仅可以得到更好的投资回报率,还可以达到质效合一的测试流程。
- -1.00 查看剩余0%
- 【留下美好印记】赞赏支持

热门文章
最新讲堂
- 推荐阅读
- 换一换
- 据曼谷邮报(Bangkok Post)今日报道,一位熟悉字节跳动的消息人士透露,字节跳动旗下的 BytePlus 部门正考虑于 2025 年在泰国建立一个数据中心,提供基于云和人工智能(AI)的服务。 该消息人士表示,泰国是字节跳动东盟扩张计划的一部分,该国的电子商务具有巨大的增长潜力,特别是在拥有众多追随者和顶级(OTT)参与者的大型零售品牌方面。 报道称,BytePlus 最近通过委任泰国公司 Light Up Total Solution Public Co Ltd(LTS)为其独家经销商,在泰国市场推出技术解决方案,包括实时商务解决方案,旨在利用当地价值约 25 亿美元(IT之...
-
- 8 月 25 日消息,索尼今日宣布,将在部分市场上调 PS5 主机价格,此次调价将针对欧洲、中东和非洲、亚太地区和拉丁美洲地区以及加拿大的部分市场推行,不过美国不会涨价。国行 PS5 数字版 / 光驱版上调 400 元,改为 3499 元 / 4299 元,涨价幅度分别为 12% 和 10%。虽然鉴于当前的全球经济环境及其对 SIE 业务的影响,此次价格上涨是必要的,但我们的首要任务仍然是改善 PS5 的供应状况,以便 尽可能多的玩家能够体验 PS5 提供的一切以及未来的发展。除非另有说明,否则以下新的 RRP 立即生效。欧洲带有超高...
-
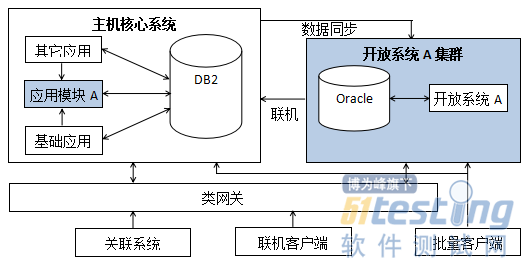
- 分布式核心系统测试方法探索与实践04-02基于主机的集中式架构核心系统面临着成本高昂、处理能力接近极限、技术封闭与弹性伸缩不足等方面的挑战。分布式核心系统,以构建主机+开放融合式架构为目标,搭建开放平台分布式核心系统应用平台,对原有的关联系统实现透明,对外提供统一的服务。分布式核心系统在扩展性、低成本、降低运行风险等方面具有明显优势。那么,分布式核心系统如何测试呢?小伙伴们,赶紧一起来看下吧!一、联机交易测试新架构下,开放平台继承主机(应用模块A)功能,搭建开放平台应用体系(开放系统A),服务于开放平台其它应用;与主机应用无关的功能从主机剥离,下移到开放平台,减少主机消耗。其总体架构如图1所示。图1 分布式核心系统总体架构根据原主机应...
- Jmeter自定义函数二次开发---函数助手08-05需求:读取本地存放图片的地址,实现随机选取图片转化为base64图片流问题出现的环境背景:工作中模型接口的传入为图片base64,在使用jmeter进行相关接口测试时需要有该功能函数。开发步骤:1、创建java项目,新建的包名称必须时org.apache.jmeter.functions,在该包下创建名为ImageToBase64的class2、导入jmeter安装目录下的lib\ext下的ApacheJMeter_functions.jar包3、继承AbstractFunction类,并重写其中的方法package org.apache.jmeter.functions; imp...
- 人工智能时代,你必须掌握的4大技术点08-09三年前的AlphaGo是人工智能发展史上的里程碑事件,当时人工智能首次击败了围棋高手,令很世界为之一震,从那时起人类就逐步进入了人工智能时代。而如今, 我们正迈向人工智能的“新时代”,在这个年代里面,无论是国际巨头,还是国内的BAT,都把人工智能列为了最核心的战略。今天,无论走到哪里,哪个会议都在讨论人工智能,人工智能时代已远远超过之前我们提到的大数据和移动互联网时代。在这个时代面前,不仅仅是几大知名的IT巨头,多个领域上千家的创业公司正风起云涌,越来越多的实用性产品早已应需而生, 例如我们熟悉的智能家居,智能炒菜,智能管家等,每一个都能直接改变传统的物质世界。怎么办?行业大佬们尚且如此,作为...

功能,搭建开放平台应用体系(开放系统A),服务于开放平台其它应用;与主机应用无关的功能从主机剥离,下移到开放平台,减少主机消耗。其总体架构如图1所示。图1 分布式核心系统总体架构根据原主机应...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=409&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=409&pic=http://quan.51testing.com/ueditor/php/upload/image/20200402/1585804547740201.png){kind=link}
- 关于我们 联系我们 版权声明 广告服务 站长统计
- 建议使用IE 11.0以上浏览器,800×600以上分辨率,法律顾问:上海兰迪律师事务所 项棋律师
- 版权所有 上海博为峰软件技术股份有限公司 Copyright©51testing.com 2003-2024, 沪ICP备05003035号
- 投诉及意见反馈:webmaster@51testing.com; 业务联系:service@51testing.com021-64471599-8017

- 51testing软件测试圈微信