 2
2 3
3


- Python精髓之括号家族:方括号、花括号和圆括号的用法总结
Python独一无二的特色除了缩进还有哪些特色呢?大多数的回答一定是语法简洁、简单易学、代码高效、功能强大等四项。那究竟是Python的哪些语言特性使得人们普遍认为Python具有语法简洁、简单易学、代码高效、功能强大的特点呢?其实很大程度上,这要归功于列表(list)、字典(dict)、元组(tuple)和集合(set)这“四大金刚”。尽管整型(int)、浮点型(float)和字符串(str)也很重要,但毫不夸张地说,列表、字典、元组和集合才代表了Python语言的核心和基础,同时也是Python的精髓所在。学会使用列表、字典、元组和集合,就意味着掌握了Python这门编程语言。
我们来一起回顾一下由列表、字典、元组和集合“四大金刚”,而演变成的由方括号、花括号和圆括号组成的“括号族”。
1. 方括号
方括号几乎是所有编程语言的第一符号。这里的第一,并不是指使用频率,而是指这个符号展现出的编程语言的内涵和创造力。事实上,就符号的使用频率而言,方括号也可能排在首位——只是我的直觉,并没有统计数据支持。
1.1 创建列表
对于初学者来说,创建列表最常用的方法就是用一对方括号。
>>> a = [] >>> a [] >>> b = [3.14, False, 'x', None] >>> b [3.14, False, 'x', None]
即便是老鸟,也会大量使用方括号创建列表,尤其是使用推导式创建列表的情况下。
>>> c = [i**2 for i in range(5)] >>> c [0, 1, 4, 9, 16]
但其实方括号就像口语或俚语,太过随便。大家要习惯使用严谨的list()来创建列表。使用list()创建列表,是list类的实例化的标准方法,可以体会list类的构造函数如何适应不同类型的参数。
>>> a = list()
>>> a
[]
>>> b = list((3.14, False, 'x', None))
>>> b
[3.14, False, 'x', None]
>>> c = list({1,2,3})
>>> c
[1, 2, 3]
>>> d = list({'x':1,'y':2,'z':3})
>>> d
['x', 'y', 'z']
>>> e = list(range(5))
>>> e
[0, 1, 2, 3, 4]
>>> f = list('*'*i for i in range(5))
>>> f
['', '*', '**', '***', '****']1.2 列表的索引
方括号可以创建列表,但方括号并不等同于列表,因为方括号还用来索引。
>>> [3.14, False, 'x', None][2] 'x' >>> [3.14, False, 'x', None][-2] 'x' >>> [3.14, False, 'x', None][1:] [False, 'x', None] >>> [3.14, False, 'x', None][:-1] [3.14, False, 'x'] >>> [3.14, False, 'x', None][::2] [3.14, 'x'] >>> [3.14, False, 'x', None][::-1] [None, 'x', False, 3.14]
列表的索引非常灵活,尤其是引入了负数索引,用-1表示最后一个元素或逆序,实属喜大普奔。上面的操作,属于常用索引方式,如果能读懂下面的代码,说明你已经具备了足够深的功力。
>>> a = [3.14, False, 'x', None] >>> a[2:2] = [1,2,3] >>> a [3.14, False, 1, 2, 3, 'x', None]
1.3 列表的方法
对于列表对象的方法如果能信手拈来,那就是Python高手了。
>>> a = [3.14, False, 'x', None]
>>> a.index('x')
2
>>> a.append([1,2,3])
>>> a
[3.14, False, 'x', None, [1, 2, 3]]
>>> a[-1].insert(1, 'ok')
>>> a
[3.14, False, 'x', None, [1, 'ok', 2, 3]]
>>> a.remove(False)
>>> a
[3.14, 'x', None, [1, 'ok', 2, 3]]
>>> a.pop(1)
'x'
>>> a
[3.14, None, [1, 'ok', 2, 3]]
>>> a.pop()
[1, 'ok', 2, 3]
>>> a
[3.14, None]2. 花括号
花括号代表字典对象,大多数初学者都这样认为。然而,这是错误的,至少是片面的。下面的代码中,a和b都是用花括号创造出来的对象,却一个是字典,一个是集合。
>>> a = {}
>>> a
{}
>>> b = {'x','y','z'}
>>> b
{'y', 'z', 'x'}
>>> type(a)
<class 'dict'>
>>> type(b)
<class 'set'>原来,Python用花括号表示字典和集合两种对象:花括号内是空的,或者是键值对的,表示字典;花括号内是无重复元素的,表示集合。为了不引起误会,我习惯用dict()来生成字典,用set()来生成集合。
>>> dict()
{}
>>> dict({'x':1, 'y':2, 'z':3})
{'x': 1, 'y': 2, 'z': 3}
>>> dict((('x',1), ('y',2), ('z',3)))
{'x': 1, 'y': 2, 'z': 3}
>>> dict.fromkeys('xyz')
{'x': None, 'y': None, 'z': None}
>>> dict.fromkeys('abc', 0)
{'a': 0, 'b': 0, 'c': 0}
>>> set((3,4,5))
{3, 4, 5}
>>> set({'x':1, 'y':2, 'z':3})
{'y', 'z', 'x'}
>>> set([3,3,4,4,5,5])
{3, 4, 5}编码实践中,虽然在某些情况下集合是无可替代的,但集合的使用频率是“四大金刚”中最低的,我们这里不展开讨论,只说说字典的使用技巧。
2.1 判断一个键是否存在于字典中
Py2时代,dict对象曾经有has_key()的方法,用来判断是否包含某个键。py3舍弃了这个方法,判断一个键是否存在于字典中,只能使用in这样的方法了。
>>> a = dict({'x':1, 'y':2, 'z':3})
>>> 'x' in a
True
>>> 'v' in a
False2.2 向字典中添加一个新键或更新键值
很多人喜欢用对字典的一个键赋值的方法,实现向字典中添加一个新键或更新键值。
>>> a = dict()
>>> a['name'] = 'xufive'
>>> a
{'name': 'xufive'}我不推荐这样的方式,使用update()才更有仪式感,还可以一次添加或修改多个键。
>>> a = dict()
>>> a.update({'name':'xufive', 'gender':'男'})
>>> a
{'name': 'xufive', 'gender': '男'}2.3 从字典中获取一个键值
a[‘age’]是最常用的方式,但是也还会遇到键不存在的异常。下面的方法值得推荐。
>>> a.get('age', 18)
182.4 获取字典的全部键、全部值、全部键值对
dict类提供了keys()、values()和items()等三个方法分别返回字典的全部键、全部值和全部键值对。需要注意的是,返回结果并非列表,而是迭代器。如果你需要列表形式的返回结果,请使用list()转换。
>>> a = dict()
>>> a.update({'name':'xufive', 'gender':'男'})
>>> list(a.keys())
['name', 'gender']
>>> list(a.values())
['xufive', '男']
>>> list(a.items())
[('name', 'xufive'), ('gender', '男')]2.5 遍历字典
遍历字典的时候,很多同学或写成遍历字典的keys()。其实,不需要这么麻烦,可以像下面这样直接遍历。
>>> a = dict([('name', 'xufive'), ('gender', '男')])
>>> for key in a:
print(key, a[key])
name xufive
gender 男3. 圆括号
圆括号代表元组对象,这么说应该没有问题吧?的确,听起来没有问题,但在元组的使用上,我相信每个初学者都会跌进同一个深坑至少一次。
3.1 必入之浅坑
元组不用于列表的最显著的特点,就是无法更新元素的值。忘记或者忽略这一点,就会入坑。
>>> a = (3, 4) >>> a[0] = 5 Traceback (most recent call last): File "<pyshell#14>", line 1, in <module> a[0] = 5 TypeError: 'tuple' object does not support item assignment
3.2 必入之深坑
我们一起来看一下下面这段代码bug在哪里
>>> import threading
>>> def do_something(name):
print('My name is %s.'%name)
>>> th = threading.Thread(target=do_something, args=('xufive'))
>>> th.start()
Exception in thread Thread-1:
Traceback (most recent call last):
File "C:\Users\xufive\AppData\Local\Programs\Python\Python37\lib\threading.py", line 926, in _bootstrap_inner
self.run()
File "C:\Users\xufive\AppData\Local\Programs\Python\Python37\lib\threading.py", line 870, in run
self._target(*self._args, **self._kwargs)
TypeError: do_something() takes 1 positional argument but 6 were given分明只提供了1个参数,却提示说给出了6个参数,为什么呢?
原来,元组初始化时,如果只有单个参数,则必须在单个参数之后增加一个逗号(,),否则,初始化结果仅返回原参数。
>>> a = (5)
>>> a
5
>>> type(a)
<class 'int'>
>>> b = ('xyz')
>>> b
'xyz'
>>> type(b)
<class 'str'>
>>> a, b = (5,), ('xyz',)
>>> a, b
((5,), ('xyz',))
>>> type(a), type(b)
(<class 'tuple'>, <class 'tuple'>)3.3 单星号解包元组
格式化输出字符串时,下面也许是很多人的写法。
>>> args = (95,99,100)
>>> '%s:语文%d分,数学%d分,英语%d分'%('天元浪子', args[0], args[1], args[2])
'天元浪子:语文95分,数学99分,英语100分'正确固然正确,但不够精彩。满分写法应该是这样的。
>>> args = (95,99,100)
>>> '%s:语文%d分,数学%d分,英语%d分'%('天元浪子', *args)
'天元浪子:语文95分,数学99分,英语100分'3.4 为什么要使用元组?
既然元组的元素不可改变,那为什么还要使用元组呢?使用列表代替元组不是更方便吗?诚然,在多数情况下,可以使用列表代替元组,但下面的例子却可以证明,列表无法代替元组。
>>> s = {1,'x',(3,4,5)}
>>> s
{1, (3, 4, 5), 'x'}
>>> s = {1,'x',[3,4,5]}
Traceback (most recent call last):
File "<pyshell#32>", line 1, in <module>
s = {1,'x',[3,4,5]}
TypeError: unhashable type: 'list'我们可以将元组加到集合中,但列表不行,因为列表是不可哈希(unhashable)的。理解这一点并不困难:列表元素可以被动态改变,所以没有一个固定不变的哈希值——这与集合要求的元素唯一性冲突;而元组的元素被禁止更新,其哈希值在整个生命周期都不会变化,因此可以成为集合的元素。
所以我们可以得到一个结论,元组和列表有着完全不同的存储方式。因为不用考虑更新问题,元组的速度性能要远优于列表。优先使用元组,应该成为Python程序员遵循的一条基本原则。
作者:医生也来编个程
原文链接:https://www.jianshu.com/p/342789a436bb
- -1.00 查看剩余0%
- 【留下美好印记】赞赏支持

热门文章
最新讲堂
- 推荐阅读
- 换一换
- 先说下误删除的原因。 我在 Postman 中建了 2 个 workspace,我把其中一个 workspace 中的 collection 分享到另一个 workspace 了,按我正常的理解,这两个已经是独立的了,但是当我从第二个 workspace 删除这个分享的 collection 后,才发现原来 workspace 的 collection 也没了,囧。 这件事的教训: 1. 从别的&...
-
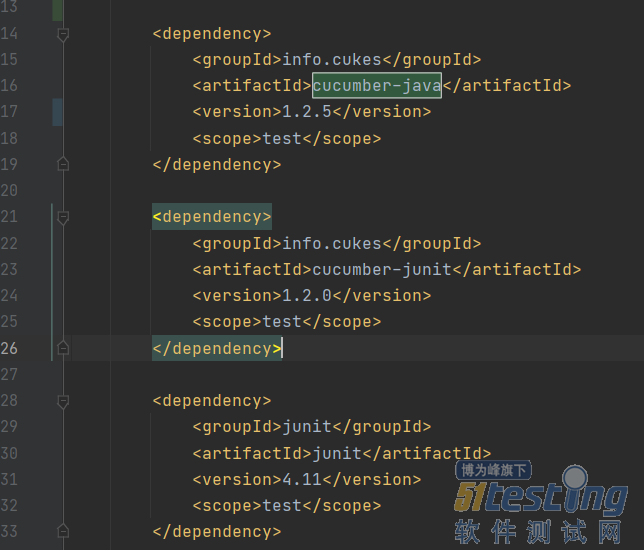
- Cucumber测试场景应用——软件测试圈07-06应用场景 “这个测试用例的前置条件、步骤、检验点是什么?” “让我看下代码。” 这可能是大多数做自动化测试的朋友遇到一种场景吧。 用例多了、代码有时候也就 “乱” 了。 清晰明了地组织自己的测试场景,让领导、同事一看就明白的你的测试步骤与检查点,不用费神费力地解释,又简单快速地维护用例代码。 这就是今天向大家介绍的BDD,让你的测试工作变得更高效、更简洁。 温馨提示 如果阅读者想按示例进行操作,您一定要具备以下的配置, 当然您也可以使用其它IDE。 自动化框架:Cucumber+Selenium 语言:Java 项目:Maven IDE:IntelliJ IDEA ...
- 测试工程师简历编写指南——软件测试圈07-11概述 在人才市场中,一次完整的求职过程通常包括以下阶段: · 简历筛选 · 电话面试 · 笔试面谈 · 意向确定 · 就职到岗 其中第一步,简历是求职过程中的敲门砖。 简历如果过于潦草,无法体现自身真实水平,那么可能连面谈的机会都得不到;反之,简历如果过于浮夸,后续流程中也难免露馅,造成不好的后果。 本文就来探讨一下,一份合格的测试工程师简历应该如何撰写。 简历元素 一份合格的简历应当包含以下元素: · 基础情况 · 个人信息 · 教育背景 · 技术能力 · 工作经历 · 项目经验 · 自我评价 1. 基础信息 求职者的基础情况有时候不会单...
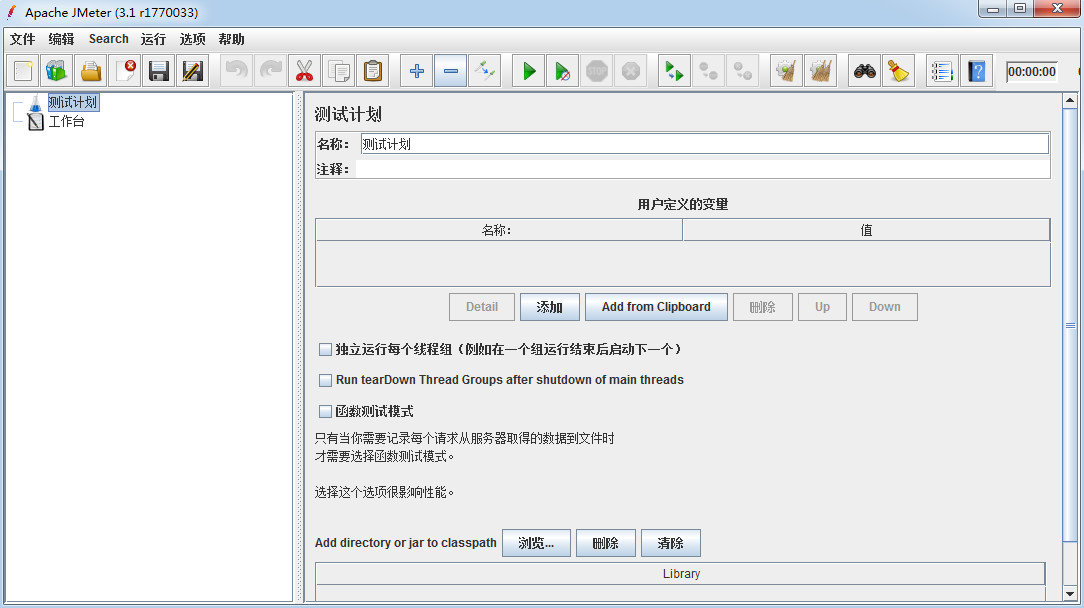
- jmeter之接口测试基础篇——软件测试圈12-13jmeter可以用来测接口和性能,由于水平有限,只能大概谈一谈接口。(接口文档跟开发要。)解压好后打开bin目录,里面有个jmeter.bat,运行就打开了。页面挺简单的,就不一一介绍了(实际是不会介绍,上来就干活吧。)这是页面,右击测试计划-->添加-->Threads(Users)-->线程组接下来右击线程组-->Sampler-->HTTP请求再添加响应断言,断言结果,查看结果树什么的,监听器里面的中文基本都可以添加看看,(英文再研究研究)添加完成这种效果,点击http请求,开始在里面填内容,接口在这里就简单模拟一下,抓一个登录接口。URL里的http是协议...
- 根据我的观察,优秀的测试人员可以做的事情可以包括如下3点: ·由单纯的测试变成项目质量保证工作 · 持续集成探索和推动和自动化测试技术研究 · 测试相关工具的开发 1、我们先来讲第一点,由单纯的测试变成项目质量保证工作 测试,从狭义的角度来讲,包括如下这些环节: 测试计划和测试用例编写-测试执行-质量报告书写 测试人员一般会在开发阶段就进行测试计划和测试用例的编写和准备工作;在测试阶段,我们一般先会做功能测试,等项目功能基本稳定,bug较少了,就开始做兼容性测试、性能测试、安全性测试。兼容性测试保证了产品在多浏览器、APP在产品在不同机型下的兼容性;性能测...
-


{kind=link}
解压好后打开bin目录,里面有个jmeter.bat,运行就打开了。页面挺简单的,就不一一介绍了(实际是不会介绍,上来就干活吧。)这是页面,右击测试计划-->添加-->Threads(Users)-->线程组接下来右击线程组-->Sampler-->HTTP请求再添加响应断言,断言结果,查看结果树什么的,监听器里面的中文基本都可以添加看看,(英文再研究研究)添加完成这种效果,点击http请求,开始在里面填内容,接口在这里就简单模拟一下,抓一个登录接口。URL里的http是协议...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=144331&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=144331&pic=http://quan.51testing.com/ueditor/php/upload/image/20211213/1639377443181125.png){kind=link}
- 关于我们 联系我们 版权声明 广告服务 站长统计
- 建议使用IE 11.0以上浏览器,800×600以上分辨率,法律顾问:上海兰迪律师事务所 项棋律师
- 版权所有 上海博为峰软件技术股份有限公司 Copyright©51testing.com 2003-2024, 沪ICP备05003035号
- 投诉及意见反馈:webmaster@51testing.com; 业务联系:service@51testing.com021-64471599-8017

- 51testing软件测试圈微信