 0
0 0
0
分享


- 浅谈有关FDBSCAN算法的研究——软件测试圈
点击链接参加测试行业调查问卷,提交成功之后免费获得独家测试资料,链接:http://vote.51testing.com/
机器学习、人工智能各类KNN算法层出不穷,DBSCAN具有强代表性,它是一个基于密度的聚类算法,最大的优点是能够把高密度区域划分为簇,能够在高噪声的条件下实现对目标的精准识别,但该算法当前已远不能满足人们对于高效率、高精准度的算法要求,由此FDBSCAN算法应运而生。
01
FDBSCAN聚类算法在KD-树的加持下,时间复杂度达到了O(nlogn),目标识别效率已指数级别上升。

02
Kd-树:它是一种树形结构,主要应用于多维空间关键数据的搜索。由于他的增加、删除、查询时间复杂度都是O(logn),所以才造就了FDBSCAN算法的高效率。
想必大家对于树形结构也不是特别陌生,但是对于四维及以上的树形结构,就难以体现其具体的结构了。kd-树的三维立体空间如下图所示:

03
FDBSCAN算法的高效就体现在它使用了KD树作为自己遍历数据的工具,通过树形结构,能够最大限度的提高遍历效率。在算法执行之前,首先对待处理数据创建Kd-树,使用KD树自有的空间搜索算法来进行数据划分。可以看到整个数据划分流程图:

04
下面对FDBSCAN算法伪代码进行展示:
FDBSCAN算法伪代码:
DBSCAN(D, eps, MinPts)
C = 0 //类别标示
for each unvisited point P in dataset D //遍历
mark P as visited //已经访问
NeighborPts = regionQuery(P, eps) //计算这个点的邻域
if sizeof(NeighborPts) < MinPts //不能作为核心点
mark P as NOISE //标记为噪音数据
else //作为核心点,根据该点创建一个类别
C = next cluster
expandCluster(P, NeighborPts, C, eps, MinPts) //根据该核心店扩展类别
expandCluster(P, NeighborPts, C, eps, MinPts)
add P to cluster C //扩展类别,核心店先加入
for each point P' in NeighborPts //然后针对核心店邻域内的点,如果该点没有被访问
if P' is not visited
mark P' as visited //进行访问
NeighborPts' = regionQuery(P', eps) //如果该点为核心点,则扩充该类别
if sizeof(NeighborPts') >= MinPts
NeighborPts = NeighborPts joined with NeighborPts'
if P' is not yet member of any cluster //如果邻域内点不是核心点,并且无类别,比如噪音数据,则加入此类别
add P' to cluster C
regionQuery(P, eps) //计算邻域
return all points within P's eps-neighborhood
kdtree (list of points pointList, int depth) {
var tree_node node;
node.location := median;
node.leftChild := kdtree(points in pointList before median, depth+1);
node.rightChild := kdtree(points in pointList after median, depth+1);
return node;
}05
机器学习、深度学习、图像识别、人工智能、大数据、区块链、互联网+等各种新兴技术层出不穷,人们对于算法的效率、精度要求也是越来越严格。各位大佬们,传统DBSCAN聚类算法对于一个高分辨率,数以千百万级的像素点的图像来说,是远远不够的,那就让FDBSCAN算法来助你一臂之力吧!
作者:樊松松
- -1.00 查看剩余0%
- 【留下美好印记】赞赏支持
登录 后发表评论

曼倩诙谐测试
+ 关注
热门文章
最新讲堂
温馨提示
- 推荐阅读
- 换一换
- 支付宝支付(二)—PC电脑网站支付——软件测试圈05-10在看这篇文章之前,希望你先看上一篇文章支付宝支付(一)—H5手机网站支付2.0(alipay.trade.wap.pay) ,涉及到的部分准备工作这里就不再重复了,有疑问的看上一篇文章或者查阅官方文档。一、PC收银台产品介绍 这篇文章我们先来介绍一下支付宝Page支付(也叫作电脑网站支付)。 电脑网站支付产品帮助用户在商家 PC 网站购买商品支付时,跳转到支付宝 PC 网站收银台完成付款。 交易资金直接打入商家支付宝账户,实时到账。 用户可以通过输入支付宝账号、密码完成支付。也可以通过支付宝APP扫码完成支付。 用户交易款项即时到账,提供退款、资金分账、对账等配套服务。1、应用场景...
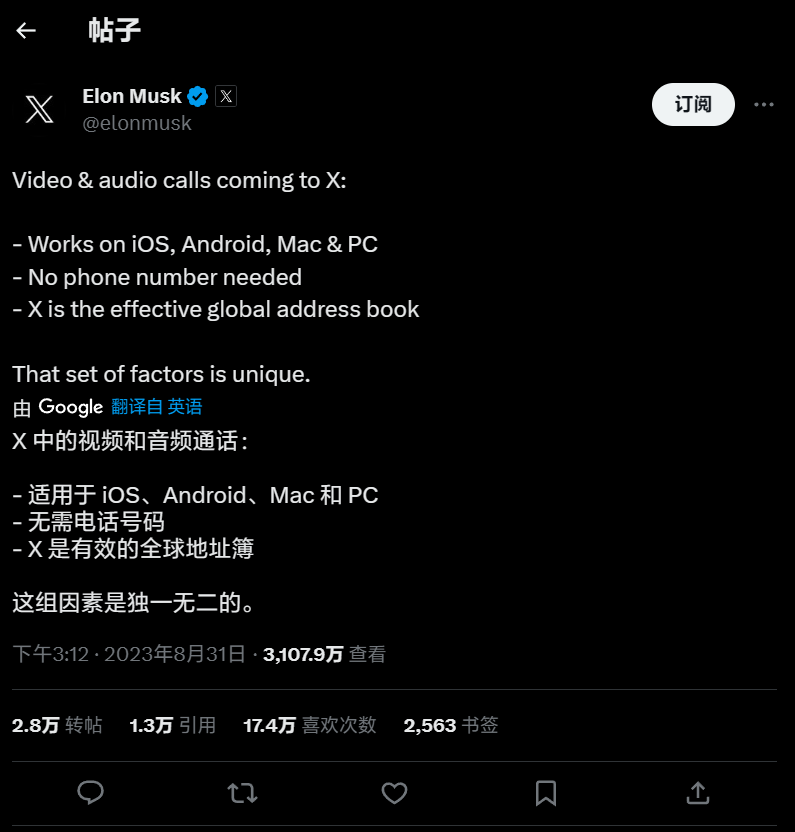
- 马斯克在执掌 X 平台之后,多次在公开场合表示要效仿微信,将 X 打造成“超级应用”。IT之家此前曾报道,X 公司首席执行官 Linda Yaccarino 在本月中旬表示 X 平台“即将支持视频通话功能”。 而马斯克本人今日在 X 平台正式官宣,X 平台将带来“音频与视频通话”选项,但目前并不确定是否只有订阅 Blue 的用户可以使用,也并不知道该特性上线的具体时间点,不过根据马斯克所述,该“音频与视频通话”功能将具有两大特性: 马斯克此前曾“毫不掩饰自己对微信模式的喜爱”,他声称:“对于那些用过微信的人来说,我认为微信实际上是一个很好的模式,它有点像推特、PayPal 以及其他一大...
-
- 信息系统项目管理师 介绍08-26记得那是2年前,闲来无事简单游览公司关于人事部分相关事宜介绍,无意间看到公司在职员工考取《信息系统项目管理师》资格证书后,高级每月可获得600元工资之外奖励、中级为300元,对于爱钱如命的我来说,顿时吸引了眼球,引起了我的好奇,开启了我与之相生相克历程。《信息系统项目管理师》是什么?考试难度大么?《信息系统项目管理师》是软考中的一种,分为高级和中级,其中高级比中级在考试科目上比中级多出了一项论文(不要小看这一篇论文,这是真正体现你学习水平的一关),在选取自己是考高级和中级的选择上,个人建议还是可以直接报考高级(一来可以省去考完中级再复习报考高级的时间,二来对于收入来说,也是差了一半);考试时间...
- 银保监会:已全面叫停新设网络小贷——软件测试圈10-14IT之家 10 月 12 日消息,据 21 世纪经济报道,近日,在“领导留言板”回复网友留言时,银保监会明确指出,针对部分小额贷款公司在网络小额贷款业务中存在的问题,组织各地方金融监管部门开展专项整治和清理规范,全面叫停新设网络小额贷款从业机构。IT之家了解到,这是继 2017 年 11 月互联网金融风险专项整治工作领导小组办公室发布《关于立即暂停批设网络小额贷款公司的通知》后,监管再次公开提及“全面叫停新设网络小贷机构”。2017 年 11 月,针对现金贷业务乱象,互联网金融风险专项整治工作领导小组办公室发布《关于立即暂停批设网络小额贷款公司的通知》,要求各级小贷公司监管部门即日起一律不得新...
- 前言 对于我们测试来说,做自动化测试需要编写测试用例,编写测试用例就会使用到单元测试模块,常见的python单元测试模块有unittest,pytest,nose等,但是听说过最多的也就属于pytest和unittest了,安静今天就通过这一篇文字简单的介绍下pytest和unittest的区别。 unittest 说起单元测试,安静立刻想到的就是unittest框架,为什么呢?因为安静刚开始学习的时候也是学习的unittest框架。unittest属于python的内置框架,被广泛的应用到各个项目中。unittest最早的时候是受到junit的启发,unittest支持多种自动化测...

-


—PC电脑网站支付——软件测试圈》& 在看这篇文章之前,希望你先看上一篇文章支付宝支付(一)—H5手机网站支付2.0(alipay.trade.wap.pay) ,涉及到的部分准备工作这里就不再重复了,有疑问的看上一篇文章或者查阅官方文档。一、PC收银台产品介绍 这篇文章我们先来介绍一下支付宝Page支付(也叫作电脑网站支付)。 电脑网站支付产品帮助用户在商家 PC 网站购买商品支付时,跳转到支付宝 PC 网站收银台完成付款。 交易资金直接打入商家支付宝账户,实时到账。 用户可以通过输入支付宝账号、密码完成支付。也可以通过支付宝APP扫码完成支付。 用户交易款项即时到账,提供退款、资金分账、对账等配套服务。1、应用场景...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=117066&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=117066&pic=http://quan.51testing.com/ueditor/php/upload/image/20210510/1620633081396071.png){kind=link}
{kind=link}
——软件测试圈》& 前言 对于我们测试来说,做自动化测试需要编写测试用例,编写测试用例就会使用到单元测试模块,常见的python单元测试模块有unittest,pytest,nose等,但是听说过最多的也就属于pytest和unittest了,安静今天就通过这一篇文字简单的介绍下pytest和unittest的区别。 unittest 说起单元测试,安静立刻想到的就是unittest框架,为什么呢?因为安静刚开始学习的时候也是学习的unittest框架。unittest属于python的内置框架,被广泛的应用到各个项目中。unittest最早的时候是受到junit的启发,unittest支持多种自动化测...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=144357&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=144357&pic=http://quan.51testing.com/ueditor/php/upload/image/20211220/1639968682619658.png){kind=link}
温馨提示
打开微信 扫一扫
温馨提示
设置支付密码
- 关于我们 联系我们 版权声明 广告服务 站长统计
- 建议使用IE 11.0以上浏览器,800×600以上分辨率,法律顾问:上海兰迪律师事务所 项棋律师
- 版权所有 上海博为峰软件技术股份有限公司 Copyright©51testing.com 2003-2024, 沪ICP备05003035号
- 投诉及意见反馈:webmaster@51testing.com; 业务联系:service@51testing.com021-64471599-8017

- 51testing软件测试圈微信