 1
1 0
0


- 成本效益:前后比较回归测试(译)
摘要:
通过比较生产和测试代码版本之间的多个API响应来进行测试的方法非常有效,可以在一个版本一个版本
地生成所需的结果。但是,需要改进和改变,以满足不断变化的需要。对于大多数(若不是所有)技术解决
方案来说都是如此;“边际效用递减定律”的经济学原理也适用于软件。一种最初引入时让利益相关者兴奋
不已的技术解决方案可能很快就会过时。需要修改或新的解决方案来匹配不断发展的期望。
概述
通过比较生产和测试代码版本之间的多个API响应来进行测试的方法非常有效,可以在一个版本一个版本
地生成所需的结果。但是,需要改进和改变,以满足不断变化的需要。对于大多数(如果不是所有)技术解决方
案来说都是如此;“边际效用递减定律”的经济学原理也适用于软件。一种最初引入时让利益相关者兴奋不已的
技术解决方案可能很快就会过时。需要修改或新的解决方案来匹配不断发展的期望。从好的方面来看,这使我
们周围的世界不断改善。
为了解决由于紧密耦合和遗留代码而导致的关键业务工作流泄漏问题,使用生产和测试版本的代码创建并
行设置,并从相同的生产备份恢复数据库;每个工作流步骤在两个设置中并行完成,然后在工作流里程碑处比较
所有报告。因为每次设置的数据都是相同的,所以这些差异是代码更改的直接结果。然后验证预期的和未预期
的更改的差异。
这种方法带来了两个挑战:
保持平行设置
没有生产数据测试
这种解决方案非常有效地发现关键流中的所有问题,这些问题是在验证操作的特定结果的特性测试中遗漏
的。与此同时,这是一个代价高昂的解决方案。由于需要并行设置,测试的h/w和许可证成本成倍增加。另一
个限制是使用生产数据备份。使用生产数据所获得的信心是无与伦比的,但随之而来的是规模问题,例如当客
户机数量增加时,使用一个复杂的客户机数据集进行测试是不够的。很多时候客户不喜欢这样,或者由于组织
政策,不能为测试共享数据。
使用单一设置而不是并行设置
使用多个设置可以比较多个版本,但实际上测试通常是比较产品和被测试版本。最初的想法是为多次运行使用一个设置—每个版本一个设置,然后保存响应并比较结果。因此,可以使用生产版本准备安装,并运行工作流的步骤,并保存API响应以进行比较。然后用测试版本刷新设置,然后执行工作流步骤,并在里程碑处并行比较API响应。这个选项失败了,因为它增加了一倍的测试时间。在截止日期前发布将变得非常困难。
为了进一步优化这一点,API响应被保存在代码存储库中,用于上一个版本。让我们更详细地阐述。发布分支是为将要发布的特性而裁剪的,GitLab管道负责在测试服务器上部署构建并触发测试套件。测试套件执行API调用,并将响应与来自前一个版本构建的已有保存的响应进行比较。报告响应中的差异以进行手动验证—检查差异是由于更改实现所预期的结果,还是由于意外更改而需要进行代码修复。如果这是预期的更改,则在回购中更新保存的响应,如果差异是意外的,则记录错误以修复问题。
该解决方案在资源和时间方面具有成本效益,使用的设置只需要一个,对于每个连续的版本只需要一个设置和执行。但它也有一个缺点,即只能对保存响应的一个版本进行比较。
使用非生产数据
使用生产数据进行测试可以提供额外的信任级别;任何测试人员都不想放弃这种特权。对于单个客户端,例如在受控组织中,这是相当简单的,并且可以使用生产数据进行测试。然而,对于许多其他情况,生产数据并不容易获得。很多时候,客户端的数据策略不允许与服务提供者共享数据,或者只能让组织中固定的一组人访问数据。换句话说,可能有各种各样的原因导致无法获得用于测试的生产数据。此外,随着客户机数量的增长,并且在跨越多个客户机的测试中需要覆盖多个场景,任何单个生产备份都不能覆盖所有场景。这就需要生成测试数据。在我们正在讨论的解决方案中,并行执行之间的数据非常需要保持一致。如果数据不一致,则无法对响应进行比较。
为了解决这个问题并保持使用生产数据的可信度(在某种程度上),可以创建一个混淆脚本。使用编排工具[如Jenkins],将恢复生产备份,执行脚本以模糊化数据,并创建新的备份。第二个备份用于测试。这第二次数据备份成为我们的基础,从下一次迭代开始,它被用于准备测试设置,而混淆脚本不会执行。相反,需要执行添加新数据的脚本。新的数据是为了提高覆盖率和覆盖新的功能。该过程的另一个步骤是将模式更改作为新版本的一部分执行。这将保持测试备份到最新版本。
结论
这些步骤的组合解决了并行回归测试的问题。比较多个版本之间的响应的方法揭示了潜在的事件和生产问题。与测试操作的预期反应相比,这验证了所有其他内容,以捕获泄漏到生产中的不需要的更改。测试与关键业务工作流相关的所有内容的基本主题为稳定发布提供了基础。客户对产品的信心增强了,这也导致了业务的扩展。使用单一的设置和生成的数据使这种方法的使用更加实际。
- -1.00 查看剩余0%
- 【留下美好印记】赞赏支持

热门文章
最新讲堂
- 推荐阅读
- 换一换
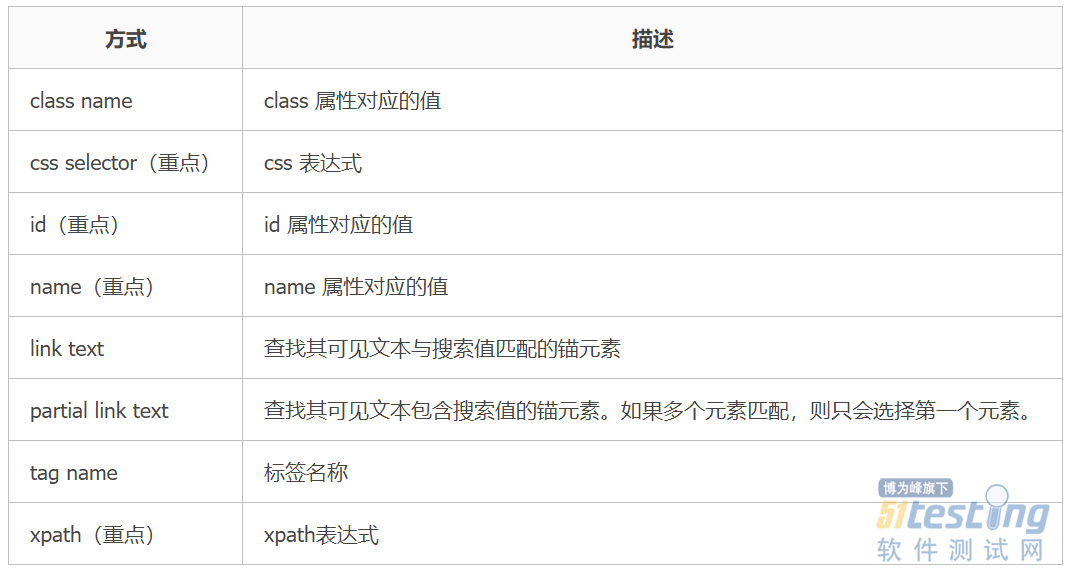
- Selenium 常见控件定位方法——软件测试圈06-27HTML知识铺垫 <!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title>测试人论坛</title> </head> <body> <a href="https://ceshiren.com/" class="link">链接</a> </body> </h...
- 测试用例和测试方法——软件测试圈12-071.测试用例的定义:测试用例是执行测试的依据,把测试系统的操作步骤用文档的形式描述出来2.测试用例包含?用例编号 用例描述 【用例所属模块】 执行条件 预期结果 测试输入 实际结果 【测试人】 【测试版本】 【测试日期】 【备注】3.测试用例文档的方式Excel word 方式 bug管理工具里可以直接写4.测试用例开始写的时间拿到对应的模块进行编写。5.测试用例的注意:根据需求文档或者是原型图年写的用例的覆盖度[80%-90%].书写用例有正反 &...
- 华为nova11系列及全场景新品发布会正式举办,nova11系列、畅享60X、MateBook系列等新品相继亮相。这其中,有一个“大家伙”非常值得关注,华为智慧屏S3Pro相较于上一代实现了全面升级,搭载智慧双芯实现了音画体验和智慧体验的大幅提升。同时,也带来了业界最强的超级投屏功能,全面革新投屏体验。 华为智慧屏S3Pro搭载了一颗4K旗舰主芯和一颗AI视觉芯片,智慧双芯的性能组合成为了行业新的解决方案。这颗4K旗舰主芯拥有四核A73CPU,主频可达1.5GHz,在应用启动速度、操作流畅性等方面起到了关键作用。同时,这颗芯片还配备了一块1.6TOPS的NPU单元,带来了鸿鹄AIHDR增...

-
- 面经之网页端测试内容——软件测试圈01-18问:网页端测试点有哪些?1.界面测试:链接能否跳转,跳转后的页面是否正确;有没有错误的信息;页面布局是否合理,风格是否统一,重点内容是否突出;图片表单位置是否正确。2.功能测试:保存:表单的输入有无格式、类型、 长度限制,内容错误有无提示;编辑和保存权限是否一致;数据能否保存成功,保存成功或失败有没有提示;字段能不能重复,不能重复有没有提示;保存成功后返回的页面是否正确;连续多次点击保存会不会新增多条重复的数据;特殊键Tab、Enter键是否能使用;数据关联性,有内容修改了,其它相关联的数据也要同步;上传:上传的文件的大小、类型手动输入上传的地址上传已删除的文件上传成功或失败的提示下载:导出的...
- 模拟多终端神器-夜神——软件测试圈11-30背景: 有个测试场景需要模拟多终端手机在线,测试配车比数是否按照系统给出的比值进行配车 测试过程: 卡车一辆一辆上线,确认卡车是否按照配车比指派到电铲终端 问题: 测试过程中没有足够真实机进行测试,所以需要模拟多台终端的场景 下面介绍一款神器--夜神模拟器如何操作的 一 夜神模拟器介绍 夜神模拟器(Nox Player)是一款针对Windows和Mac操作系统的Android模拟器。它允许用户在计算机上模拟Android设备,以便在桌面上运行Android应用程序和游戏。以下是夜神模拟器的一些特点和功能: 1.多平台支持:夜神模拟器可在Windows和Mac操作...



{kind=link}
{kind=link}
{kind=link}
是一款针对Windows和Mac操作系统的Android模拟器。它允许用户在计算机上模拟Android设备,以便在桌面上运行Android应用程序和游戏。以下是夜神模拟器的一些特点和功能: 1.多平台支持:夜神模拟器可在Windows和Mac操作...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=146641&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=146641&pic=http://quan.51testing.com/ueditor/php/upload/image/20231130/1701326972669905.png){kind=link}
- 关于我们 联系我们 版权声明 广告服务 站长统计
- 建议使用IE 11.0以上浏览器,800×600以上分辨率,法律顾问:上海兰迪律师事务所 项棋律师
- 版权所有 上海博为峰软件技术股份有限公司 Copyright©51testing.com 2003-2024, 沪ICP备05003035号
- 投诉及意见反馈:webmaster@51testing.com; 业务联系:service@51testing.com021-64471599-8017

- 51testing软件测试圈微信