 0
0 0
0


- 数据库设计规范——软件测试圈
一、数据规范化
仅有好的RDBMS并不足以避免数据冗余,必须在数据库的设计中创建好的表结构
Dr E.F.codd 最初定义了规范化的三个级别,范式是具有最小冗余的表结构
这些范式是:
1、第一范式(1st NF -First Normal Fromate)
2、第二范式(2nd NF-Second Normal Fromate)
3、 第三范式(3rd NF- Third Normal Fromate)
第一范式 (1st NF):

第一范式的目标是确保每列的原子性
如果每列都是不可再分的最小数据单元(也称为最小的原子单元),则满足第一范式(1NF)
第二范式 (2nd NF):

如果一个关系满足1NF,并且除了主键以外的其他列,都依赖与该主键,则满足第二范式(2NF)
第二范式要求每个表只描述一件事情
第三范式 (3rd NF):

如果一个关系满足2NF,并且除了主键以外的其他列都不传递依赖于主键列,则满足第三范式(3NF)
二、规范化实例
假设某建筑公司要设计一个数据库,公司的业务规则概括说明如下:
1、公司承担多个工程项目,每一项工程有:工程号、工程名称、施工人员等
2、公司有多名职工,每一名职工有:职工号、姓名、性别、职务(工程师、技术员)等
3、公司按照工时和小时工资率支付工资,小时工资率由职工的职务决定(例如,技术员的小时工资率与
工程师不同)
4、公司定期制定一个工资报表
如图所示(工资表):

如图所示(工时表):

表中包含大量的冗余,可能会导致数据异常:
更新异常 :
------例如,修改职工号=1001的职务,则必须修改所有职工号=1001的行
添加异常:
------若要增加一个新的职工时,首先必须给这名职工分配一个工程。或者为了添加一名新职工的数据,先给这名职工分配一个虚拟的工程。(因为主关键字不能为空)
删除异常:
------例如,1001号职工要辞职,则必须删除所有职工号=1001的数据行。这样的删除操作,很可能丢失了其它有用的数据
采用这种方法设计表的结构,虽然很容易产生工资报表,但是每当一名职工分配一个工程时,都要重复输入大量的数据。这种重复的输入操作,很可能导致数据的不一致性。
应用范式规范化设计
一张表描述了多件事情

应用第二范式规范化

应用第三范式规范化

作者:网易测试开发猿
原文链接:https://blog.csdn.net/shuang_waiwai/article/details/121500382
- -1.00 查看剩余0%
- 【留下美好印记】赞赏支持

热门文章
最新讲堂
- 推荐阅读
- 换一换
- 据每日经济新闻今天傍晚报道,日前有消息称,Stellantis 集团正在考虑向中国车企出售旗下超豪华汽车品牌玛莎拉蒂,该品牌有望被奇瑞拿下。对此,奇瑞方面的回复为“并无相关消息”。 关于奇瑞和玛莎拉蒂两家车企的传闻可追溯至今年 4 月 14 日。奇瑞董事长在驾驶星纪元 ET 进行长途高速高阶智驾挑战直播时透露,欧洲两家豪华品牌将用奇瑞平台生产高端汽车。“某欧洲豪华品牌要用星途星纪元的技术平台造车,有一家已接近落实签约,另一个海外品牌也在谈。” 有不具名知情人士称,和奇瑞汽车谈合作的欧洲豪华品牌大概是玛莎拉蒂。据IT之家此前报道,尹同跃曾在 4 月放话称,星途星纪元品牌“要往高端走”,要...
-
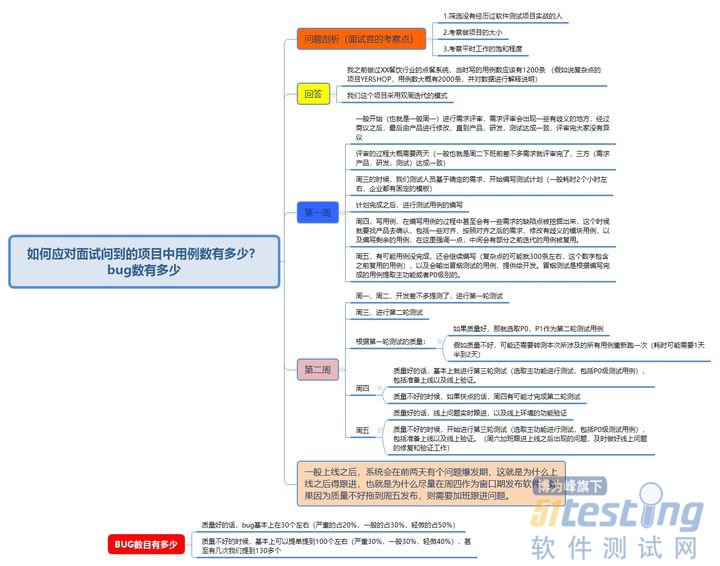
- 首先,我觉得在软件测试面试的过程中,逻辑比较混乱的最大一个原因是,说明你没有形成一个一个整体的体系。导致你说的时候很多东西都杂乱无章。 我个人认为软件测试,其实开始首先进行的是一些需求的分析工作,之后呢,进行需求的评审,需求评审完成之后,当需求确定之后我们下来开始着手去写一些测试计划相关的内容。等测试计划编写完成之后,针对每个人分配好的固定模块,各自去编写一些测试用例。然后编写完成测试用例之后,进行测试用例的评审,评审完成之后大家形成一个统一的测试用例。 之后,在这个时候开发的软件已经开发的差不多了,我们对开发的软件输出一部分冒烟测试用例,要求开发对着冒烟的测试用例全部通过之后,进行提...
-
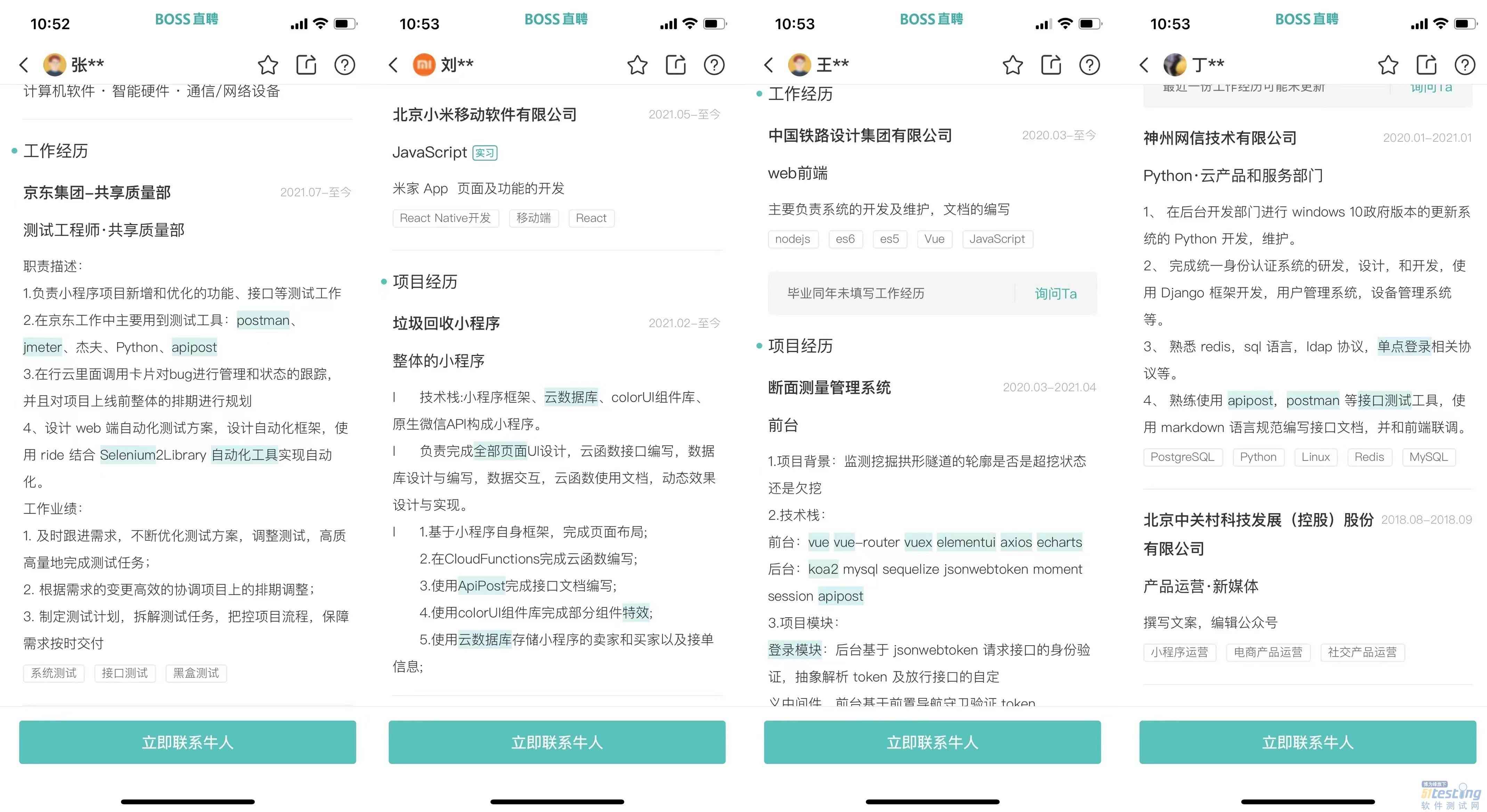
- 51Testing软件测试网正在收集测试行业问卷结果,如果你也想为测试行业的前景助力,就点击下方的链接提交答案吧,还有精美礼品等你拿(测试课程五选二)。链接:http://vote.51testing.com/ 本人在今年互联网大环境如此严峻的情况下,作为一个刚毕业不到一年的初级测试,赶在“金九银十”依然拿到了一些面试机会,并且成功拿下4家公司的offer,其中不乏互联网大厂,而且最高总包给到了接近double(无炫耀的意思 〒▽〒)~ 确定好要签的offer后,我决定来复盘一下这波求职的成功原因,也给身处迷茫期的测试朋友提供一个参考,同时抛砖引玉~ 其实我认为最根本的原因是我迅速完...
-
- 入职软件测试,谈谈我面试的经验——软件测试圈04-03宝子们,现在是不是还在观望呢?有没有考虑转行?有没有了解过软件测试呢?现在软件测试的风口很大,但是并不是什么人都能学软件测试,我不建议大家盲目跟风。 1、学历大专以上,最好本科。 2、逻辑能力强,沟通能力强(不要社恐)。 3、计算机专业的最好,别的专业也无所谓。 4、有抗压能力。 一、性格测试 总共是有一百道题目左右,不能够返回答题,因为部分题是考察考生的回答题目的一致性。 现在想起来感觉第二次和第一次填写的答案差不多,就感觉emmm。。。很迷。 这里建议大家在答题的时候要保持一颗要努力拼搏,不怕困难以及积极向上的心态。 二、技术一面 其实之前也有了解过今年的华为面试比...
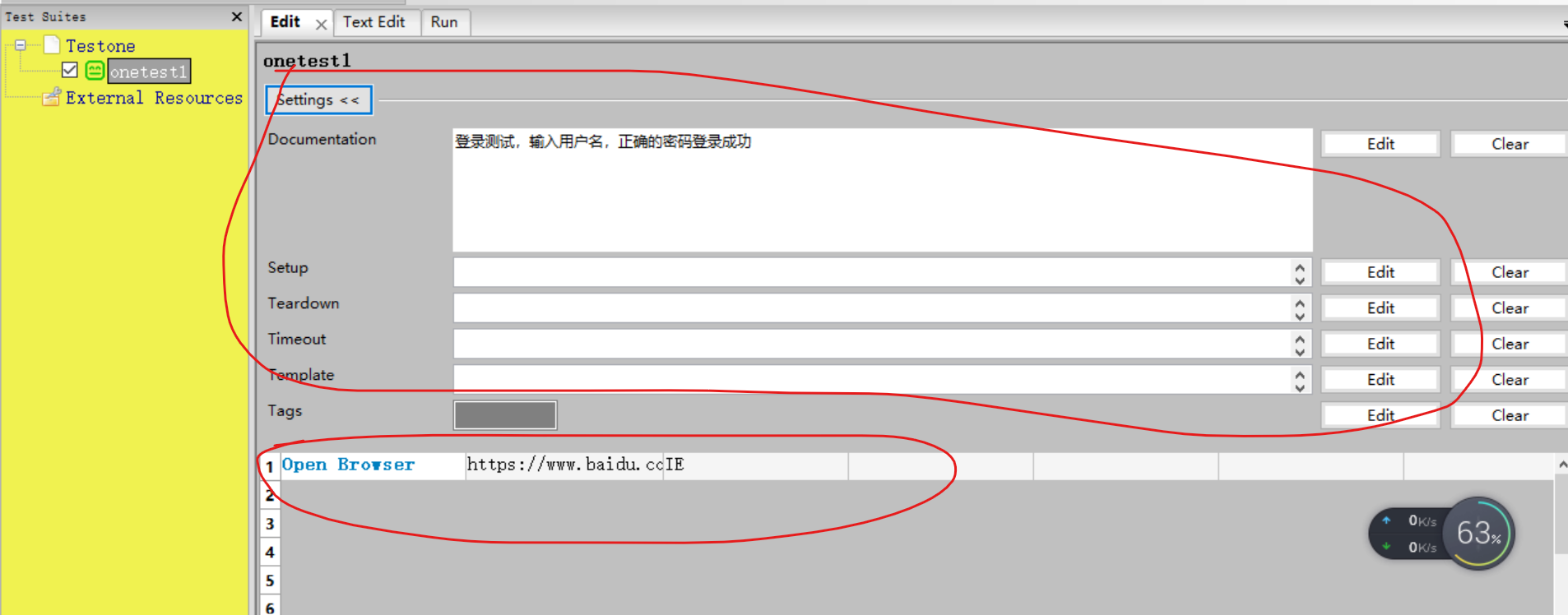
- 开源软件最大的好处是免费的,最大的烦恼大概就是各种问题的调试解决吧,这是一个非常浪费时间和精力的问题,说实话以前都是拿别人整理好的软件直接用,再就是公司所给使用的也都是经过验证没啥问题的正式版本,没有见过这么多问题,想当然的我也以为这软件安装好,能启动就可以直接拿来用了,但当自己实际去用的时候,发现这问题一堆,特别是python 3.8匹配的这个版本,那个问题是多啊,整得我是没有脾气了,下面就给大家讲讲我所遇到的问题吧,但愿我的问题能给你带来帮助。 首先说说第一个遇到的问题吧: 创建用例后发现用例编写页面空白一片,没有编写的地方,就是图上红线标示的地方都看不到,怎么回事,求助百度搜索发...
-

{kind=link}
。链接:http://vote.51testing.com/ 本人在今年互联网大环境如此严峻的情况下,作为一个刚毕业不到一年的初级测试,赶在“金九银十”依然拿到了一些面试机会,并且成功拿下4家公司的offer,其中不乏互联网大厂,而且最高总包给到了接近double(无炫耀的意思 〒▽〒)~ 确定好要签的offer后,我决定来复盘一下这波求职的成功原因,也给身处迷茫期的测试朋友提供一个参考,同时抛砖引玉~ 其实我认为最根本的原因是我迅速完...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=145441&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=145441&pic=http://quan.51testing.com/ueditor/php/upload/image/20221009/1665283317578767.jpg){kind=link}
{kind=link}
- 关于我们 联系我们 版权声明 广告服务 站长统计
- 建议使用IE 11.0以上浏览器,800×600以上分辨率,法律顾问:上海兰迪律师事务所 项棋律师
- 版权所有 上海博为峰软件技术股份有限公司 Copyright©51testing.com 2003-2024, 沪ICP备05003035号
- 投诉及意见反馈:webmaster@51testing.com; 业务联系:service@51testing.com021-64471599-8017

- 51testing软件测试圈微信