 0
0 0
0


- 机器学习的类型
机器学习程序分为 3 种类型,如下所示。
监督
无监督
强化学习
2.1 监督学习
监督学习发生在监督者在场的情况下,就像小孩在老师的帮助下进行的学习一样。当孩子在老师的监督下接受训练以识别水果、颜色和数字时,这种方法就是监督学习。
在这种方法中,孩子的每一步都由老师检查,孩子从他必须产生的输出中学习。
监督学习如何运作?
在有监督的 ML 算法中,输出是已知的。输入与输出之间存在映射。因此,为了创建一个模型,机器被输入了大量的训练输入数据(输入和相应的输出已知)。
训练数据有助于为创建的数据模型实现一定程度的准确性。构建的模型现在已准备好接受新的输入数据并预测结果。
什么是标签数据集?
对于给定输入,具有已知输出的数据集称为标记数据集。例如,水果的图像连同水果的名称是已知的。因此,当显示新的水果图像时,它会与训练集进行比较以预测答案。
2.2 无监督学习
无监督学习在没有监督者的帮助下发生,就像鱼学会自己游泳一样。这是一个独立的学习过程。
在此模型中,由于没有与输入映射的输出,因此目标值是未知/未标记的。系统需要自己从输入的数据中学习并检测隐藏的模式。
什么是无标签数据集?
对于所有输入值具有未知输出值的数据集称为未标记数据集。
无监督学习如何工作?
由于没有已知的输出值可用于在输入和输出之间建立逻辑模型,因此使用一些技术来挖掘数据规则、模式和具有相似类型的数据组。这些组帮助最终用户更好地理解数据并找到有意义的输出。
馈入的输入不像训练数据那样采用适当的结构形式(在监督学习中)。它可能包含异常值、噪声数据等。这些输入一起馈送到系统。在训练模型时,输入被组织形成集群。
无监督算法的类型

聚类算法:寻找相同形状、大小、颜色、价格等数据项之间的相似性,并将它们分组形成一个聚类的方法就是聚类分析。
异常值检测:在这种方法中,数据集是对数据中任何类型的差异和异常的搜索。例如,系统检测到信用卡上的高额交易以进行欺诈检测。
关联规则挖掘:在这种类型的挖掘中,它找出最频繁出现的项集或元素之间的关联。诸如“经常一起购买的产品”等关联。
自动编码器:输入被压缩成编码形式并被重新创建以去除噪声数据。该技术用于改善图像和视频质量。
2.3 强化学习
在这种类型的学习中,算法通过反馈机制和过去的经验来学习。总是希望采取算法中的每一步来达到一个目标。
因此,无论何时要采取下一步,它都会收到上一步的反馈,以及从经验中学习来预测下一个最佳步骤。这个过程也称为达到目标的试错过程。
强化学习是一个长期的迭代过程。反馈的数量越多,系统就越准确。基本强化学习也称为马尔可夫决策过程。
强化学习的例子
强化学习的一个例子是视频游戏,玩家完成游戏的某些级别并获得奖励积分。游戏通过奖励动作向玩家提供反馈,以提高他/她的表现。
强化学习用于训练机器人、自动驾驶汽车、库存自动管理等。
以上讲解了什么是机器学习以及机器学习是如何工作的,还有机器学习的类型分为监督学习、无监督学习、强化学习等。
- -1.00 查看剩余0%
- 【留下美好印记】赞赏支持

热门文章
最新讲堂
- 推荐阅读
- 换一换
- web自动化中常用的跳过验证码操作——软件测试圈06-15前言 在做web自动化的时候,登录验证码是一个大问题。在测试过程中,我们可以通过找研发进行去除,但是如果真的无法去除的时候,那应该怎么操作呢? 安静今天通过几个实例来给大家介绍下,web自动化中怎么解决验证码的问题。 通过cookies值登录 我们都知道cookies是保持登录的一种状态,那是否可以通过cookies进行登录呢? selenium中也有获取cookies信息操作,通过将cookies保存在text中,在我们执行登录操作时,进行将cookies添加进去,这个时候就能通过cookies完成登录,从而跳过验证码内容。 思路是清晰了,先进行通过selenium进行获取c...

- 【测试技术】常用的linux命令集锦07-15测试人员部署版本的时候需要登录linux服务器,去下载,安装一些环境配置,搭建测试环境,这样才能和开发环境独立开来。除此之外,版本测试期间,在一部分场景下,测试人员需要登录服务器去查询一些文件,修改一些文件,修改一些文件权限等,或者链接数据库,查询数据库,新增数据,删除,修改数据等。这个时候就需要用到一些linux命令了。1)使用less [file] 命令查看2)[g] 跳到文件头3)[G] 跳到文件尾部4)[/] 向下查找5)[?] 向上查找6)[n] 查找后找下一个7)[N] 查找后找上一个8)[b] 向上翻...
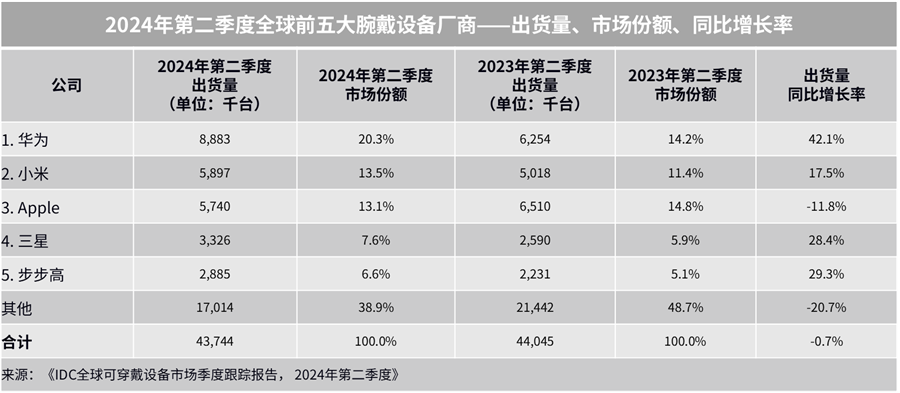
- 根据国际数据公司(IDC)最新发布的《全球可穿戴设备市场季度跟踪报告》,2024 年第二季度全球腕戴设备市场出货 4,374 万台,同比下滑 0.7%;中国腕戴设备市场出货量为 1,555 万台,同比增长 10.9%,发展速度明显超过全球市场。 · 腕戴设备市场包含智能手表和手环产品。其中: · 智能手表市场 2024 年第二季度全球出货量 3,475 万台,同比下降 3.2%;而中国智能手表市场出货量 1,114 万台,同比增长 18.7%。 手环市场 2024 年第二季度全球出货量 899 万台,同比增长 10.6%;中国手环市场出货量 441 万台,同比下降 4.8%...
-
- 前言:本篇讲堂是紧接【安全测试工具-进阶篇[XSS跨站点脚本漏洞(上)]】的内容。例牌,先说下安全测试工具的更新情况【工具地址:https://gitee.com/samllpig/SafeTool-51testing】1. 安全测试工具服务端增加前端脚本路由定位功能漏洞讲解:所属模块: (A7) Cross-Site Scripting (XSS) [跨站脚本漏洞]8.1.7 第七节主题:本节是个小测验,试试反射型XSS内容:测试XSS最重要的是确定可以注入的字段,并构造一段html标记和javascript代码,我们把它称之为有效载荷,将有效载荷注入到http请求中的所有可控参数...
-
- 如何利用GPT自动生成单元测试代码——软件测试圈11-07为什么我要做单元测试 1. 单元测试的定义和作用 在工作中,我们都希望提高效率、保证质量。那么,如何利用gpt来帮助我们开发,提升效率呢?今天,我们来探究一下如何让gpt帮我们快速写单元测试。单元测试是一种软件开发过程中的测试方法,它能够验证代码是否符合预期的功能和设计要求。通过单元测试,我们可以测试程序中每个独立的单元,并在修改代码后快速验证是否符合功能要求。这样不仅能提高代码的质量,减少缺陷和错误,还能提高代码的可维护性和可读性。让gpt来帮助我们快速写单元测试,能够让我们更加高效地开发出高质量的代码,满足用户需求,提升工作效率。所以,让我们一起来探索一下如何利用gpt来写单元测试...



{kind=link}
使用less [file] 命令查看2)[g] 跳到文件头3)[G] 跳到文件尾部4)[/] 向下查找5)[?] 向上查找6)[n] 查找后找下一个7)[N] 查找后找上一个8)[b] 向上翻...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=145007&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=145007&pic=http://quan.51testing.com/ueditor/php/upload/image/20220715/1657855336808214.png){kind=link}
最新发布的《全球可穿戴设备市场季度跟踪报告》,2024 年第二季度全球腕戴设备市场出货 4,374 万台,同比下滑 0.7%;中国腕戴设备市场出货量为 1,555 万台,同比增长 10.9%,发展速度明显超过全球市场。 · 腕戴设备市场包含智能手表和手环产品。其中: · 智能手表市场 2024 年第二季度全球出货量 3,475 万台,同比下降 3.2%;而中国智能手表市场出货量 1,114 万台,同比增长 18.7%。 手环市场 2024 年第二季度全球出货量 899 万台,同比增长 10.6%;中国手环市场出货量 441 万台,同比下降 4.8%...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=147208&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=147208&pic=http://quan.51testing.com/ueditor/php/upload/image/20240905/1725503000651453.png){kind=link}
]》&前言:本篇讲堂是紧接【安全测试工具-进阶篇[XSS跨站点脚本漏洞(上)]】的内容。例牌,先说下安全测试工具的更新情况【工具地址:https://gitee.com/samllpig/SafeTool-51testing】1. 安全测试工具服务端增加前端脚本路由定位功能漏洞讲解:所属模块: (A7) Cross-Site Scripting (XSS) [跨站脚本漏洞]8.1.7 第七节主题:本节是个小测验,试试反射型XSS内容:测试XSS最重要的是确定可以注入的字段,并构造一段html标记和javascript代码,我们把它称之为有效载荷,将有效载荷注入到http请求中的所有可控参数...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=143884&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=143884&pic=http://quan.51testing.com/ueditor/php/upload/image/20210824/1629786368125901.png){kind=link}
- 关于我们 联系我们 版权声明 广告服务 站长统计
- 建议使用IE 11.0以上浏览器,800×600以上分辨率,法律顾问:上海兰迪律师事务所 项棋律师
- 版权所有 上海博为峰软件技术股份有限公司 Copyright©51testing.com 2003-2024, 沪ICP备05003035号
- 投诉及意见反馈:webmaster@51testing.com; 业务联系:service@51testing.com021-64471599-8017

- 51testing软件测试圈微信