 1
1 0
0


- 深聊性能测试之:Locust性能自动化代码实战(二)
接着《深聊性能测试之:Locust性能自动化代码实战(一)》,我们继续第二部分的分享:
4. Locust高级用法
4.1 关联
做过接口或者爬虫的的大佬都知道,传参是必不可少的,
而常见的场景有session_id。
对于返回的html页面,可用采用lxml库来定位获取需要的参数。
我们先上代码
# -*- coding: utf-8 -*-
"""
@ auth : carl_DJ
@ time : 2022-07-23
"""
from locust import HttpUser,task,TaskSet
from lxml import etree
class WebsitTasks(TaskSet):
#获取session
def get_session(self,html):
tags = etree.HTML(html)
return tags.xpath("输入标签需要定位的到元素")
#启动
def on_start(self):
html = self.client.get('/index')
session = self.get_session(html.text)
#设置payload参数
payload = {
'username': 'carl_dj',
'password':'111111',
'session':session
}
#设置header参数
header = {"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36"}
self.client.post('/login',data = payload,headers = header)
@task(5)
def index(self):
self.client.get('/')
@task(1)
def about(self):
self.client.about('/about/')
class WebsiteUser(HttpUser):
# 被测系统的host,在终端中启动locust时没有指定--host参数时才会用到
host = "http://www.xxx.com/user/login"
# TaskSet类,该类定义用户任务信息,必填。这里就是:WebsiteTasks类名,因为该类继承TaskSet;
task_set = task(WebsiteTasks)
# 每个用户执行两个任务间隔时间的上下限(毫秒),具体数值在上下限中随机取值,若不指定默认间隔时间固定为1秒
min_wait = 5000
max_wait = 15000嗯,详细的内容都在代码中标注,这里就不再重新唠叨。
4.2 参数化
4.2.1 聊一聊参数化
老话说的好:代码写死一时爽,框架重构火葬场
虽然大部分大佬还没有涉及到 设计框架的阶段,但是,只要稍微努努力…
火葬场 迟早都是要去滴~ ~
所以,就有了另一句老话:动态代码一时爽,一直动态一时爽
可见,参数化的作用,真的,很Nice!
话说回来,参数化的作用是啥呢:循环取数据,数据可重复使用。
4.2.2 三个场景认识参数化
场景1:
>> 模拟3个用户并发请求网页,共有100个URL地址,每个虚拟用户都会依次循环加载100个URL地址
代码展示:
# -*- coding: utf-8 -*-
"""
@ auth : carl_DJ
@ time : 2022-07-23
"""
from locust import TaskSet, task, HttpUser
class UserBehav(TaskSet):
def on_start(self):
self.index = 0
@task
def test_visit(self):
url = self.locust.share_data[self.index]
print('visit url: %s' % url)
self.index = (self.index + 1) % len(self.locust.share_data)
self.client.get(url)
class WebsiteUser( HttpUser):
host = 'http://www.xxx.com'
task_set = task(UserBehav)
share_data = ['url1', 'url2', 'url3', 'url4', 'url5']
min_wait = 1000
max_wait = 15000场景2
>>>模拟3用户并发注册账号,共有9个账号,要求注册账号不重复,注册完毕后结束测试
概括:
保证并发测试数据唯一性,不循环取数据
>>>所有并发虚拟用户共享同一份测试数据,并且保证虚拟用户使用的数据不重复;
代码示例:
采用队列
# -*- coding: utf-8 -*-
"""
@ auth : carl_DJ
@ time : 2020-9-23
"""
from locust import TaskSet, task, HttpUser
import queue
class UserBehav(TaskSet):
@task
def test_register(self):
try:
data = self.locust.user_data_queue.get()
except queue.Empty:
print('account data run out, test ended.')
exit(0)
print('register with user: {}, pwd: {}'\
.format(data['username'], data['password']))
payload = {
'username': data['username'],
'password': data['password']
}
self.client.post('/register', data=payload)
class WebsiteUser(HttpUser):
host = 'http://www.xxx.com'
task_set = task(UserBehav)
user_data_queue = queue.Queue()
for index in range(100):
data = {
"username": "test%04d" % index,
"password": "pwd%04d" % index,
"email": "test%04d@debugtalk.test" % index,
"phone": "186%08d" % index,
}
user_data_queue.put_nowait(data)
min_wait = 1000
max_wait = 15000场景3
>>>模拟3个用户并发登录账号,总共有9个账号,要求并发登录账号不相同,但数据可循环使用;
概括:
保证并发测试数据唯一性,循环取数据;
>>>所有并发虚拟用户共享同一份测试数据,保证并发虚拟用户使用的数据不重复,并且数据可循环重复使用。
代码展示
# -*- coding: utf-8 -*-
"""
@ auth : carl_DJ
@ time : 2022-07-23
"""
from locust import TaskSet, task, HttpUser
import queue
class UserBehav(TaskSet):
@task
def test_register(self):
try:
data = self.locust.user_data_queue.get()
except queue.Empty:
print('account data run out, test ended')
exit(0)
print('register with user: {0}, pwd: {1}' .format(data['username'], data['password']))
payload = {
'username': data['username'],
'password': data['password']
}
self.client.post('/register', data=payload)
self.locust.user_data_queue.put_nowait(data)
class WebsiteUser(HttpUser):
host = 'http://www.xxx.com'
task_set = task(UserBehav)
user_data_queue = queue.Queue()
for index in range(100):
data = {
"username": "test%04d" % index,
"password": "pwd%04d" % index,
"email": "test%04d@debugtalk.test" % index,
"phone": "186%08d" % index,
}
user_data_queue.put_nowait(data)
min_wait = 1000
max_wait = 150004.3 检查点
我们直接使用assert来进行断言操作。
上代码:
# -*- coding: utf-8 -*-
"""
@ auth : carl_DJ
@ time : 2022-07-23
"""
from locust import task
@task
def test_interface(self):
#直接使用csdn的某一个api
with self.client.get("https://editor.csdn.net/md?articleId=108596407",name = 'fileconfig',catch_response=True) as response:
#python断言对接口返回值中的max字段进行断言
assert response.json()['rating']['max']==100
#对http响应码是否200进行判断
if response.status_code ==200:
response.success()
else:
response.failure("Failed!")这里说明一下:
1、断言形式:with self.client.get(“url地址”,catch_response=True) as response;
2、response.status_code获取http响应码进行判断,失败后会加到统计错误表中;
>>>如果直接使用python自带assert,则不会进入到locust报表,
3、默认不写参数catch_response=False断言无效,将catch_response=True才生效。
5. Locust运行模式
运行Locust时,通常会使用到两种运行模式:单进程运行和多进程分布式运行。
5.1 单进程运行模式
5.1.1 定义及解析
1、Locust所有的虚拟并发用户均运行在单个Python进程中,
由于单进程的原因,并不能完全发挥压力机所有处理器的能力,因此主要用于调试脚本和小并发压测的情况。
2、当并发压力要求较高时,就需要用到Locust的多进程分布式运行模式。
>>> 一旦单台计算机不足以模拟所需的用户数量,Locust就会支持运行分布在多台计算机上的负载测试。
3、多进程分布运行情况:
①多台压力机同时运行,每台压力机分担负载一部分的压力生成;
②同一台压力机上开启多个slave的情况。
>>>如果一台压力机有N个处理器内核,那么就在这台压力机上启动一个master,N个slave。
>>>也可以启动N的倍数个slave。
5.1.2 有Web UI模式
Locust默认采用8089端口启动web;如果要使用其它端口,就可以使用如下参数进行指定。
参数说明:
① -P, --port:指定web端口,默认为8089.
终端中—>进入到代码目录: locust -f locustfile.py --host = xxxxx.com
② -f: 指定性能测试脚本文件
③ -host: 被测试应用的URL地址【如果不填写,读取继承(HttpLocust)类中定义的host】
注意
1、如果Locust运行在本机,在浏览器中访问http://localhost:8089即可进入Locust的Web管理页面;
2、如果Locust运行在其它机器上,那么在浏览器中访问http://locust_machine_ip:8089即可。
5.1.3 无Web UI模式
如果采用no_web形式,则需使用–no-web参数,并会用到如下几个参数。
参数说明:
① -c, --clients:指定并发用户数;
② -n, --num-request:指定总执行测试次数;
③ -r, --hatch-rate:指定并发加压速率,默认值位1。
示例展示:
$ locust -f locustfile.py --host = xxxxx --no-web -c 1 -n 2
5.1.4 启动locust
在Pycharm的 的Terminal 中启动 locust,
输入内容:
locust --host =http://localhost -f test_load.py
也可以在 VScode、WindowsPowserShell中启动,这里我就是用 Pycharm演示一下
5.2 多进程分布式运行
不管是单机多进程,还是多机负载模式,运行方式都是一样的,都是先运行一个master,再启动多个slave。
5.2.1 master启动
1、启动master时,需要使用–master参数
2、如果要使用8089以外的端口,还需要使用-P, --port参数
示例展示:
locust -f prof_load.py --master --port=8089
5.2.2 slave 启动
1、启动slave时需要使用–slave参数
2、在slave中,就不需要再指定端口
3、master启动后,还需要启动slave才能执行测试任务
示例展示
locust -f monitorAgent.py --slave
ocust -f monitorAgent.py --slave --master-host=<locust_machine_ip>
master和slave都启动完成,就可以进入到Locust 的web界面。剩下的操作,就是界面操作了~
6. Locust 结果分析

Number of users to simulate: 设置虚拟用户数,对应中no_web模式的-c, --clients参数;
Hatch rate(users spawned/second): 每秒产生(启动)的虚拟用户数 , 对应着no_web模式的-r, --hatch-rate参数,默认为1。

上图:启动了一个 master 和两个 slave,由两个 slave 来向被测试系统发送请求
性能测试参数
Type: 请求的类型,例如GET/POST。
Name:请求的路径。这里为百度首页,即:https://www.baidu.com/
request:当前请求的数量。
fails:当前请求失败的数量。
Median:中间值,单位毫秒,一半的服务器响应时间低于该值,而另一半高于该值。
Average:平均值,单位毫秒,所有请求的平均响应时间。
Min:请求的最小服务器响应时间,单位毫秒。
Max:请求的最大服务器响应时间,单位毫秒。
Content Size:单个请求的大小,单位字节。
reqs/sec:是每秒钟请求的个数。
相比于LoadRunner,Locust的结果展示十分简单,主要就四个指标:并发数、RPS、响应时间、异常率。但对于大多数场景来说,这几个指标已经足够了。

上图是 曲线分析图。
关于locust的代码实战及结果分析,就先到这里。
在这里,小鱼再多说一句:
万行代码从头写,先看基础挺要紧
所以,要弄懂代码,还是先看基础。
- -1.00 查看剩余0%
- 【留下美好印记】赞赏支持

热门文章
最新讲堂
- 推荐阅读
- 换一换
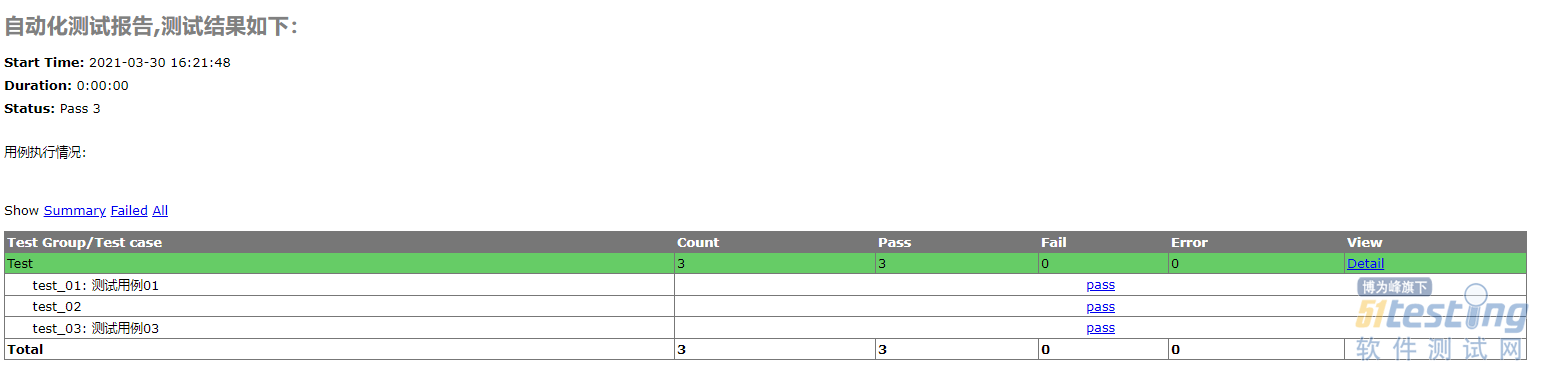
- 前言 无论做什么自动化,测试报告一定要有的,它可以清楚的展示出来我们执行用例的情况。便于查看自动化测试结果内容。安静这边了解目前通过python生成的测试报告分别有:HTMLTestRunner、BeautifulReport 、 pytest-html 和Allure,这几种报告内容都是属于不同的模板,本篇文章主要介绍下这如何生成以上四份报告的过程以及对比情况。 HTMLTestRunner HTMLTestRunner是Python标准库的unittest模块的扩展。它生成易于使用的HTML测试报告。使用时需要下载,然后放到项目目录中 下载地址:http://tungwaiyi...
-
- 测试工程师如何突破职业瓶颈?——软件测试圈04-12测试行业现状 继教育培训、社区团购领域大幅度裁员之后,互联网大厂裁员消息也开始陆续传出,百度爆出游戏部门300多人接近全部被裁,直播业务被裁员90%;爱奇艺大规模裁员,裁员比例在20%到40%;而腾讯在年度员工大会表示,PCG事业群将开始大规模人员优化,此外,字节、阿里、携程等一众互联网企业,都开始削减支出、裁员过冬,不得不承认互联网企业的寒冬已来。 互联网仍在发展,但已经是存量市场了,对人员规模的需求正在放缓。在存量市场里,冗余人员和低效人员会被淘汰、被外包,而优秀的人才也会一直受到招聘方的青睐。所以我们就看到了近期行业里冰火两重天的一幕,一边是大量的低端测试工程师被淘汰、被外包和被...
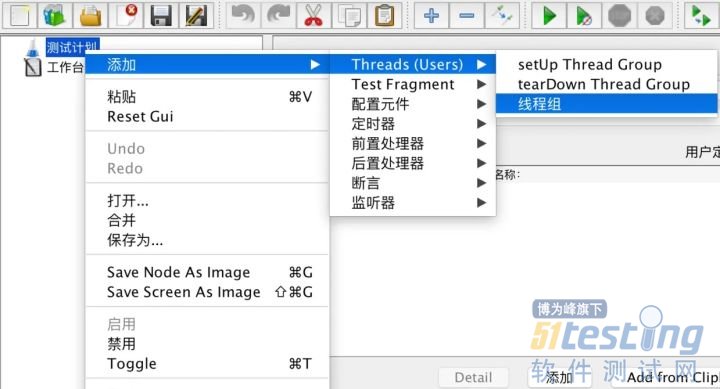
- 一、简介 我的jdk是1.8 Jmeter版本是3.3 其它可能会有冲突 导致不能正确安装 jdk和jmeter会有对应版本,大家注意。 二、打开Jmeter 在安装jmeter里面的bin目录下双击jmeter.bat文件即可本地启动。 三、添加虚拟用户组 入下图所示,右击“测试计划”,添加-Theard-线程组。 线程组:JMeter是由Java实现的,并且使用一个Java线程来模拟一个用户,因此线程组就是指一组用户的意思,这些虚拟用户用来模拟访问被测系统。 四、线程组常用设置 线程数:虚拟用户数,默认的输入是1,表明一个用户访问被测系统,如果想模拟100个用户...
-
- 自从学会Jenkins自动化,我整个人都升华了10-09初次使用Jenkins部署自动化,记录下操作过程。安装Jenkins采用安装离线版Jenkins,将文件解压后,在Jenkins文件夹内启动终端,输入命令java -jar jenkins.war --httpPort=3344,启动。进入Jenkins页面输入账号密码。创建一个任务配置任务General目前仅需填写描述,其他不做了解。源码管理源码管理分两种方式,本底和远程(git/svn,两种操作方式类似)。git填写git地址以及账号密码。本地选无,然后把代码文件拉入Jenkins工作空间中(workspace)。构建触发器触发远程构建 (例如,使用脚本):使用远程脚本出发任务。Build...
- 新浪科技讯 北京时间11月30日早间消息,据报道,Twitter表示,从11月23日起,该公司在最近的网站更新中已经不再推行与新冠肺炎不实信息相关的政策。这意味着Twitter将不再优先删除或标记与新冠肺炎有关的误导性信息。Twitter于2020年12月宣布,该公司将开始标记和删除与新冠肺炎疫苗有关的不实信息,原因是有成千上万的帐号发布与新冠病毒和疫苗接种的副作用有关的虚假信息。Twitter CEO埃隆·马斯克(Elon Musk)一直对美国卫生官员应对新冠疫情的方式颇有微词。他于2020年在播客 “The Joe Rogan Experience”上表示,美国新冠肺炎的死亡率远低于卫生官...
-


{kind=link}
{kind=link}
。git填写git地址以及账号密码。本地选无,然后把代码文件拉入Jenkins工作空间中(workspace)。构建触发器触发远程构建 (例如,使用脚本):使用远程脚本出发任务。Build...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=768&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=768&pic=http://quan.51testing.com/ueditor/php/upload/image/20201009/1602226936706085.png){kind=link}
- 关于我们 联系我们 版权声明 广告服务 站长统计
- 建议使用IE 11.0以上浏览器,800×600以上分辨率,法律顾问:上海兰迪律师事务所 项棋律师
- 版权所有 上海博为峰软件技术股份有限公司 Copyright©51testing.com 2003-2024, 沪ICP备05003035号
- 投诉及意见反馈:webmaster@51testing.com; 业务联系:service@51testing.com021-64471599-8017

- 51testing软件测试圈微信