 1
1 4
4


- 深聊自动化测试之:熬夜整理21条避坑指南,让你完美运行自动化
1、引言
在撸码过程中,99.1%的大佬,都不敢说自己的撸出来的代码,是不需要debug的。
换句话说,码农在撸码过程中,最痛苦的,莫过于撸出来的代码,又…

为了能避坑,小鱼也是在撸码过程中,总结的一点避坑方法,
请各位大佬笑纳
2、避坑内容总结
2.1无法定位到元素
遇到问题:
找不到元素,脚本报“NoSuchElementException:Unable to find element”,或"定位到了,不能操作,点击无效
解决方法:
- 查看自己的“属性值”是否写正确
- 元素的标签不唯一,默认找到第一个
- 向上查看,元素是否在frame或iframe框架中
- 查看元素是否在新打开的页面中,需要切换到新窗口
- 换其它的定位方式:id/name/class name/tag name/link text/xpath/css selector
- 检查元素属性是否是会变动的、是否是隐藏的
- 添加等待时间sleep(),implicitly_wait(),WebDriverWait(driver, 10, 1).until(定位的元素, messages)
- 查看标签的属性是否有“style=’display:none’->。元素不显示。属性改为block即可
- 查看标签的属性是否有‘οnclick=return false’->。取消点击。属性改为false即可
- 针对于9和8这两种情况,修改js属性:
js=”document.getElementById(‘title‘).style.display=’block’” driver.execute_script(js)
2.2 Indentation Error
遇到问题:
出现 Indentation Error
解决方法:
脚本代码对其
2.3 PO设计模式类
1、使用PO设计模式封装页面元素类,需要有初始化函数"init"
2、页面元素调用Page类时候,Page函数,后面括号的“self”不用写
3、Page的初始化包含(self,driver)两个元素,在页面封装类中,初始化中调用方式为
Page.__init__(self,driver)
4、页面元素封装时候,定位方式一定要写对,否则报错
5、在页面封装中,类的初始化使用如下样式:
def __init__(self,driver): Page.__init__(self,driver)
6、类中定义变量,比如x=“hello”,调用时使用:self.x
7、在testcase中调用已封装的并且实例化的类时,在testcase中定义函数,不需要写self。
# -*- coding: utf-8 -*-
"""
@ auth : Carl_奕然
@ time : 2022-02-19
"""
def test_pmlogin(self):
try:
driver = self.driver
pm = Login(driver)
pm.strat()
pm.login_home()
pm.login_username('admin')
pm.login_password('8888888')
pm.login_click()
time.sleep(2)
pm.quit()
except Exception as e:
logging.info(f"login in failed {e}")
pm.quit()2.4 页面封装类中没有已定义函数的问题
2.4.1 提示没有该方法
遇到问题
在调用baseView.py文件的公共方法,提示:没有该方法
解决方法
1.需要在baseView.py文件确认,是否已封装该方法
2.导入的包/模块是否正确
2.4.2 没有定义好的函数
遇到问题
提示在页面封装类中没有baseView.py文件中定义好的函数
解决方法
①新建名字为module_baseView.pth文件,内容为“baseView.py文件”存放路径:例如(“E:\Progect”)
② 进入python的安装目录,将文件放到python3\lib\sit-packages文件夹下
③ 在测试用例中导入其他文件夹模块引入:import sys
④ sys.path.append(“…”)
⑤ from … import …
2.5 parater must be str
遇到问题
出现”parater must be str“
原因
使用参数有问题
解决方法
①在封装页面元素定位方式时,经常会会遇到二次定位
② 第一次定位调用基础类的方法,第二次定位就正常写就行了,
例如:
x=self.find_element(locu).find_element(By.ID,'locu')
2.6 继承
继承,使我们减少代码冗余及代码高效的常用方式。
子集继承父级(不是继承银子)
老规矩,上例子
""" @ auth : Carl_奕然 @ time : 2022-02-19 """ def __init__(self,dirver): Logger.__init__(self,'DJ') self.log=self.getlog() self.driver = driver
2.7 not all arguments curerted during string format
遇到问题
打印输出时显示“not all arguments curerted during string format”
原因
前后参数不对应
解决方法
调整前后参数,使其一致
2.8 读取文件转码错误
遇到问题
读取txt文件的汉子和字符是,打印出一串编码,如下:
(b’\xef\xbb\xbf\xe5\xa5\xbd\xe7\x9a\x84\r\n’)
解决办法
"""
@ auth : Carl_奕然
@ time : 2022-02-19
"""
x = open("test.txt","rb")
y = x.readlines()
for i in y:
#追加utf8 格式
j = i.decode('utf-8')
print(j)
x.close()2.9 str object is not callable
遇到问题
出现"“str object is not callable”
原因
使用定义的变量名字与内置模块名字相同
解决办法
修改定义变量名
2.10 开启多窗口无法定位到最后一个句柄
遇到问题
开启多窗口,第一次得到的句柄列表为a=[1,2],第二次得到的句柄列表是b=[1,3,2],按照顺序排序,要切换到句柄3?
解决方法
首先把a和b变成集合,再取b不同于a的元素
c=list(set(b)-set(a))=[3]
然后再转换为列表赋值给变量c
driver.switch_to.window(c[0])
2.11 Can not connect to the Service chromedriver
遇到问题
提示 Can not connect to the Service chromedriver
原因
chromedriver未被调用
解决方法
①python根目录存放chromedriver
②hrome版本号与chromedriver版本号 要匹配
③chromedriver追加到环境变量(Path)
④运行脚本调用chromedriver
⑤Firewalls 允许chromedriver运行
2.12 文件路径配置
读取数据文件,尽量使用参数化,即 调用os模块
import os data_dir = os.path.dirname(os.path.abspath(__file__)) file_path = os.path.join(data_dir,'data1.txt')
2.13 文件改名与复制
python对文件进行"改名"和"复制"
#引入os模块
import os
data_dir = os.path.dirname(os.path.abspath(__file__))
old_file = os.path.join(data_dir,'data.txt')
new_file = os.path.join(data_dir,'new_data.txt')
#改名
os.rename(old_file,new_file)
#复制
os.system(f"copy {old_file},{new_file}")2.14 调用脚本小技巧
技巧一
运行自动化脚本时,将鼠标放到屏幕中间或者下方,(有可能切换窗口时定位不到)
大量脚本运行,一般我们都是在后台运行
代码示例
options = webdriver.ChromeOptions()
options.add_argument('headless')
driver = webdriver.Chrome(options=options)技巧二
cmd窗口,直接把结果写入文本
#测试报告 python allrun.py >>replor.html #log nohup python my.py >> ../python/logfile/run.log 2>&1
参数说明
nuhup:是no hang up的缩写,即不挂断运行
2>&1:
0: 表示stdin标准输入,用户键盘输入的内容
1 表示stdout标准输出,输出到显示屏的内容
2 表示stderr标准错误,报错内容
- -1.00 查看剩余0%
- 【留下美好印记】赞赏支持

热门文章
最新讲堂
- 推荐阅读
- 换一换
- 模糊测试工具设计思路浅谈——软件测试圈09-01一、说明去年写了一篇“模糊测试(fuzzing)是什么”,在最后提到可以自己手动编写实现模糊测试工具,但一直没把可行的代码放上来。其实这不是光说不练没实现,而是在去年就着手编写了,并在前段时间发现参数未做防呆处理导致设备重启上收到了很好的效果,只是一是说代码涉及产品具体业务需要进行处理二是说对之前做到一半没做完的事时常缺乏兴趣回头继续做。二、模糊测试中的几个关键问题讨论2.1 如何标识模糊测试项标识模糊测试项有两大思路:一类是sqlmap的无标识思路,另一类是burpsuite的有标识思路。sqlmap无标识思路:自动分析数据中的参数,然后逐个参数进行测试;优点是使用方便,缺点是如果协议的结构...

- 我爬取了8483条测试工程师招聘需求,竟发现……软件测试要做些什么?软件测试需要掌握什么技能?软件测试有发展前景吗?……针对以上问题,谭叔写过文章介绍,也做过线上分享,你可以翻翻之前推送的文章。但我总觉得还差个东西——软件测试的职业环境。就我个人来说,我每隔一段时间(或半年、或一年)便会审视、总结软件测试职业,给自己的未来一个交代。最近,借金三银四招聘旺季的契机,我爬取了某招聘网站8483条测试工程师的用人需求,通过分析这些数据,跟大家讲一讲软件测试的职业环境。具体请看:数据爬取、数据清洗、数据分析数据爬取我不喜欢重复造轮子,在分析之前,我依旧在网上浏览,却发现并无多少博主通过分析招聘需求来研...
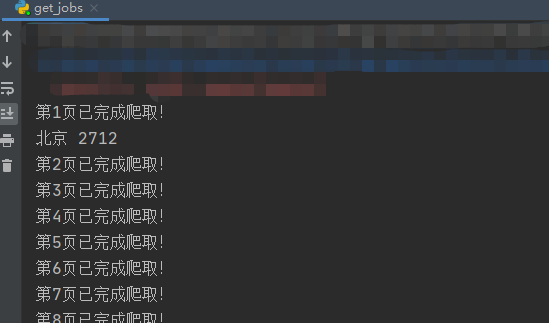
-
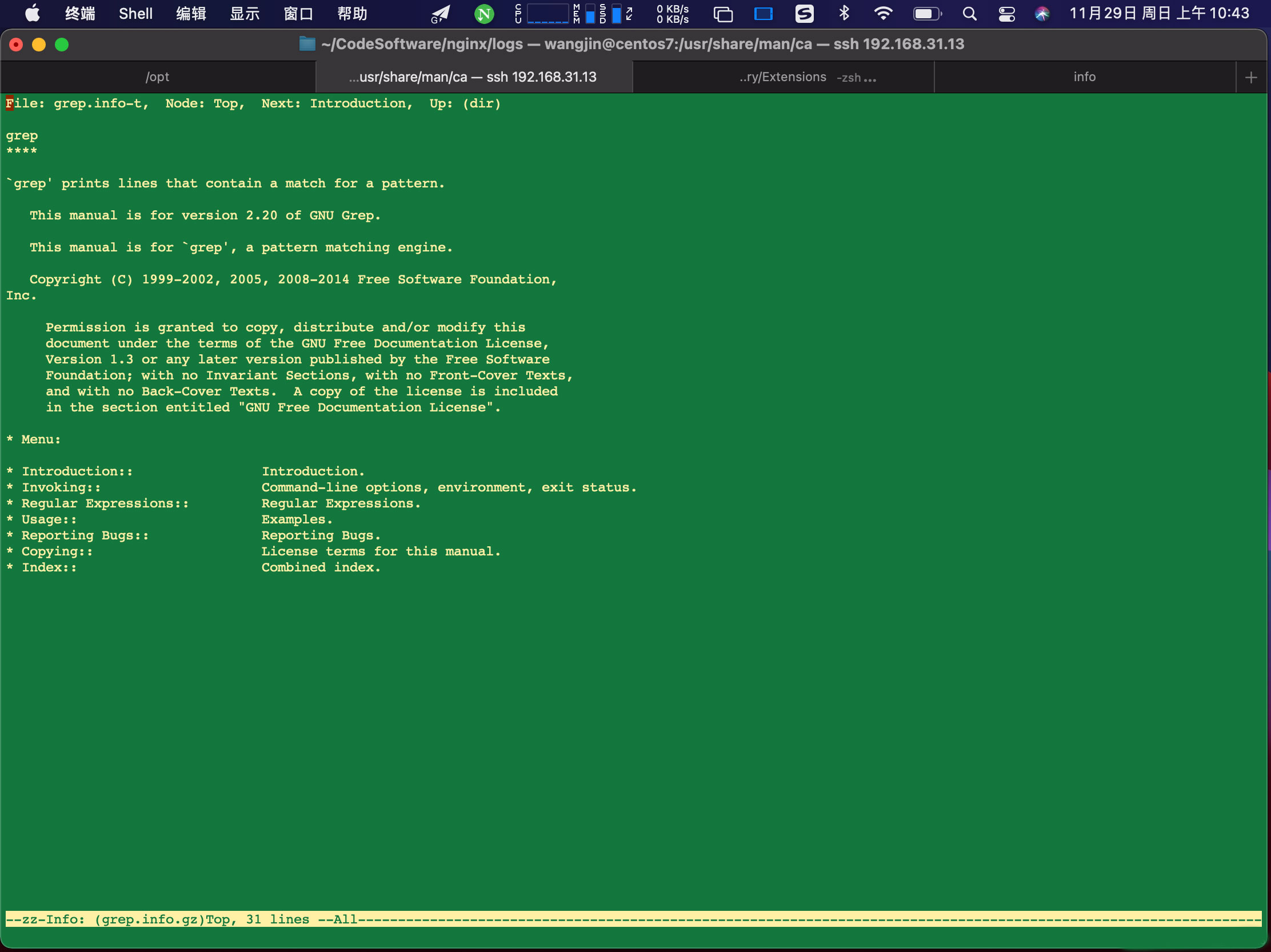
- Linux info 命令详解——软件测试圈02-04快捷键首先,我们进入具体命令的info界面。如使用info grep 或者 info info命令。即可进入如下界面:此时再单击h键,即可查看info内的帮助。如下图:即可查看info中可以使用的快捷键说明:操作:x:关闭 info内帮助界面Ctrl + g:取消当前操作(如搜索)页面内移动:↑:移动到上一行↓:移动到下一行Tab:移动到下一个超链接处(menu或交叉引用),按Enter键跳转链接deletebackPage Up:移动到上一屏空格键Page Down:移动到下一屏node间移动:Home:移动到node的开始End:移动到node的结束l:返回到上一个查看的node[:移动到...
- 高效接口测试(三)08-121.3 如何转存Swagger的内容上一个小节,我们学习到了如何通过Swagger提供的接口,获取文档中所有的数据信息。我们拿到了所有的数据信息,发现是一个很大的Json报文,里面的结构在上个小节中也基本梳理清楚了。下一步我们就要把核心的,也就是接口测试用例中要用到的数据,转存到一个Excel文件中。一直跟随我学习的童鞋们,会记得我们开发过一批类似的接口测试工具,都是使用Excel来编写测试用例,直接运行生成测试报告。如果我们能把Swagger中的接口信息,自动化的导出成接口工具对应格式的Excel,那么开发人员变更了服务端代码,Swagger文档自动更新,接口测试用例也会自动同步。 ...

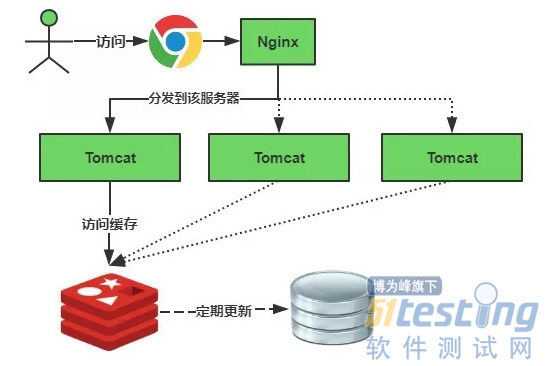
- 测试进阶:从0开始搭建测试体系——软件测试圈11-01一、缓存测试 缓存系统的使用,在一定程度上,极大的提升了应用程序的性能和效率,在秒杀系统的建设上,缓存系统出力不小,特别是数据查询方面,数据的快速返回广受好评。但同时,它也带来了一些问题,测试过程中,如果没有及时关注到缓存系统,整个测试环节是有遗漏的。缓存系统没有经过严格的测试,容易产生一个严重的问题,就是数据的一致性问题。如果没有对缓存系统进行测试,并且后端系统对数据的一致性要求很高,那么就不能使用缓存。 缓存的主要作用:是将业务系统的数据处理结果,暂时在内存中保存,并且等待下次访问的时候,立马从内存中取出。在日常开发场景中,因为服务器的性能或者自身业务对数据处理非常耗时的时候,当发...




是什么”,在最后提到可以自己手动编写实现模糊测试工具,但一直没把可行的代码放上来。其实这不是光说不练没实现,而是在去年就着手编写了,并在前段时间发现参数未做防呆处理导致设备重启上收到了很好的效果,只是一是说代码涉及产品具体业务需要进行处理二是说对之前做到一半没做完的事时常缺乏兴趣回头继续做。二、模糊测试中的几个关键问题讨论2.1 如何标识模糊测试项标识模糊测试项有两大思路:一类是sqlmap的无标识思路,另一类是burpsuite的有标识思路。sqlmap无标识思路:自动分析数据中的参数,然后逐个参数进行测试;优点是使用方便,缺点是如果协议的结构...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=145346&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=145346&pic=http://quan.51testing.com/ueditor/php/upload/image/20220901/1662017363523860.png){kind=link}
便会审视、总结软件测试职业,给自己的未来一个交代。最近,借金三银四招聘旺季的契机,我爬取了某招聘网站8483条测试工程师的用人需求,通过分析这些数据,跟大家讲一讲软件测试的职业环境。具体请看:数据爬取、数据清洗、数据分析数据爬取我不喜欢重复造轮子,在分析之前,我依旧在网上浏览,却发现并无多少博主通过分析招聘需求来研...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=116887&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=116887&pic=http://quan.51testing.com/ueditor/php/upload/image/20210308/1615171167892783.png){kind=link}
页面内移动:↑:移动到上一行↓:移动到下一行Tab:移动到下一个超链接处(menu或交叉引用),按Enter键跳转链接deletebackPage Up:移动到上一屏空格键Page Down:移动到下一屏node间移动:Home:移动到node的开始End:移动到node的结束l:返回到上一个查看的node[:移动到...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=1399&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=1399&pic=http://quan.51testing.com/ueditor/php/upload/image/20210204/1612415644649966.jpg){kind=link}
》&1.3 如何转存Swagger的内容上一个小节,我们学习到了如何通过Swagger提供的接口,获取文档中所有的数据信息。我们拿到了所有的数据信息,发现是一个很大的Json报文,里面的结构在上个小节中也基本梳理清楚了。下一步我们就要把核心的,也就是接口测试用例中要用到的数据,转存到一个Excel文件中。一直跟随我学习的童鞋们,会记得我们开发过一批类似的接口测试工具,都是使用Excel来编写测试用例,直接运行生成测试报告。如果我们能把Swagger中的接口信息,自动化的导出成接口工具对应格式的Excel,那么开发人员变更了服务端代码,Swagger文档自动更新,接口测试用例也会自动同步。 ...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=687&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=687&pic=http://quan.51testing.com/ueditor/php/upload/image/20200812/1597199117598933.jpg){kind=link}
{kind=link}
- 关于我们 联系我们 版权声明 广告服务 站长统计
- 建议使用IE 11.0以上浏览器,800×600以上分辨率,法律顾问:上海兰迪律师事务所 项棋律师
- 版权所有 上海博为峰软件技术股份有限公司 Copyright©51testing.com 2003-2024, 沪ICP备05003035号
- 投诉及意见反馈:webmaster@51testing.com; 业务联系:service@51testing.com021-64471599-8017

- 51testing软件测试圈微信