 0
0 0
0


- 分析:如何多线程运行测试用例——软件测试圈
这是时常被问到的问题,尤其是UI自动化的运行,过程非常耗时,所以,所以多线程不失为一种首先想到的解决方案。
多线程是针对的测试用例,所以和selenium没有直接关系,我们要关心的是单元测试框架。
unittest
首先,应该说明的是unittest本身是不支持多线程的。当然,如果你学过Python的threading模块,也未必不行。不过我在stackoverflow 找了半天,大多是介绍unittest 测试多线程模块,并非是unittest本身如何多线程运行用例。
“我如何学习葵花宝典” 和 “我如何验证 张三 学会了葵花宝典”是两回事,而我显然要解决的问题是前者。
又重新百度,结果就找了答案。核心借助 tomorrow3 的测试库,再配合HTMLTestRunner 生成测试报告。
https://github.com/SeldomQA/HTMLTestRunner
https://github.com/dflupu/tomorrow3

测试用例
测试用例如下,你可以复制多份测试。
# test_a.py
import time
import unittest
from selenium import webdriver
class Test1(unittest.TestCase):
@classmethod
def setUpClass(cls):
cls.driver = webdriver.Chrome()
def test_01(self):
self.driver.get("https://www.bing.com/?mkt=zh-CN")
elem = self.driver.find_element_by_id("sb_form_q")
elem.send_keys("多线程")
elem.submit()
time.sleep(2)
self.assertIn("多线程", self.driver.title)
@classmethod
def tearDownClass(cls):
cls.driver.quit()
if __name__ == "__main__":
unittest.main()运行文件
核心在tomorrow3提供的threads装饰器,用于装饰测试运行方法。
import unittest
import os
from TestRunner import HTMLTestRunner
from tomorrow3 import threads
# 定义目录
BASE_DIR = os.path.dirname(os.path.realpath(__file__))
TEST_DIR = os.path.join(BASE_DIR, "test_dir")
REPORT_DIR = os.path.join(BASE_DIR, "test_report")
def test_suits():
"""
加载所有的测试用例
"""
discover = unittest.defaultTestLoader.discover(
TEST_DIR,
pattern="test_*.py"
)
return discover
@threads(2) # !!!核心!!!! 设置线程数
def run_case(all_case, nth=0):
"""
执行所有的用例, 并把结果写入测试报告
"""
report_abspath = os.path.join(REPORT_DIR, f"result{nth}.html")
with open(report_abspath, "wb+") as file:
runner = HTMLTestRunner(stream=file, title='多线程测试报告')
# 调用test_suits函数返回值
runner.run(all_case)
if __name__ == "__main__":
cases = test_suits()
# 循环启动线程
for i, j in zip(cases, range(len(list(cases)))):
run_case(i, nth=j) # 执行用例,生成报告总结:
确实可以(根据设置的线程数)同时开启两个浏览器运行,同时带来了两个问题。
程序会根据线程数,生成多份测试报告,每个测试报告统计当前线程所运行的测试结果。
如果去掉nth参数,设置为一个报告,那么第二个线程运行的结果不能正确展示的一张报告上。
至少每个线程中的用例要保证有浏览器的启动/关闭。
第3点,你可能不理解,我举个例子,小时候见过妈妈/奶奶缝衣服。假设一件衣服拿一根针来缝制,缝衣服最麻烦就是穿针引线,针眼很小,每次都要费半天功夫,小孩子眼神好,我时常被叫去穿针引线。那为了节约时间怎么办,我当然是把线弄的长长的,最好是一根针线可以缝制多件衣服。
在Selenium 中,定义的浏览器驱动driver,每一条用例都定义一次驱动,伴随而来的就每个用例都开启/关闭一次浏览器,这当然是非常耗时的,为了缩短这个时间,我们最好是启动一次浏览器把所有用例都跑完才关闭。
那么问题来了,当我们使用多线程之后,相当于多个人同时缝制衣服,共用一根针线肯定不行啊。至少需要每人一根针线吧!而且缝制衣服的人是变化的,为了赶时间就多两个人(多开两个线程),用例比较少就少几个人(少启两个线程),为了适应这种变化,那么最好一件衣配置一根针线,每件衣服是最小单位,一个人必须要独立的把一件衣服缝好。
为了使用多线程,我们就必须每条用例开启/关闭一次浏览器,这其实是另一种时间的浪费,为了弥补这里的浪费,你必须把线程开得足够多才行。
最后,你必须再配置一位统计员,去统计每个人缝制衣服的数量,合计到一个报告中。
pytest
多线程运行用例在 pytest 中就相对容易太多了,pytest-xdist 插件就可以完成这件事情。
https://github.com/pytest-dev/pytest-xdist

测试用例
测试用例如下,你可以复制多份测试。
# test_a.py
import time
from selenium import webdriver
def test_01():
driver = webdriver.Chrome()
driver.get("http://www.baidu.com")
elem = driver.find_element_by_id("kw")
elem.send_keys("unittest")
elem.submit()
time.sleep(2)
assert driver.title == "unittest_百度搜索"
driver.quit()
def test_02():
driver = webdriver.Chrome()
driver.get("http://www.baidu.com")
elem = driver.find_element_by_id("kw")
elem.send_keys("python")
elem.submit()
time.sleep(2)
assert driver.title == "python_百度搜索"
driver.quit()运行文件
核心就是安装 pytest-xdist 插件,通过-n参数设置线程数即可。
import os import pytest # 定义目录 BASE_DIR = os.path.dirname(os.path.realpath(__file__)) TEST_DIR = os.path.join(BASE_DIR, "test_dir") REPORT_DIR = os.path.join(BASE_DIR, "test_report") if __name__ == '__main__': report_file = os.path.join(REPORT_DIR, "result.html") pytest.main([ "-n", "2", # !!核心!!!设置2个线程 "-v", "-s", TEST_DIR, "--html=" + report_file, ])
总结:
相对于unittest,在pytest实现多线程非常简单,最终线线程的测试结果也可以很好在一个测试报告中展示。
存在的问题,正如我上面讨论的,你必须为每个用例设置开启/关闭。除了额外消耗启动时间外,如果想统一配置用例通过哪个浏览器执行也会比较麻烦。
你的每一条用例应该保持绝对独立,不能出现这条用例依赖上条用例的执行结果。因为,这两条用例可能会分配由不同的线程执行。
正如上一条的原因,你不能控制用例的执行顺序。
作者:虫师
原文链接:https://www.cnblogs.com/fnng/p/15441515.html
- -1.00 查看剩余0%
- 【留下美好印记】赞赏支持

热门文章
最新讲堂
- 推荐阅读
- 换一换
- 据报道,为了省钱、增加收入,马斯克试图让员工购买Twitter办公室绿植。不愿透露姓名的Twitter工程师称,马斯克关注的重点主要是钱,为了省钱,马斯克已经炒掉了清洁和餐饮员工。 因为管理混乱,Twitter纽约办公室甚至出现蟑螂,马斯克无意与负责清洁卫生的员工续签合约,办公室甚至能闻到恶臭。 去年10月末马斯克收购Twitter,之后大刀阔斧改革,马斯克宣称改革是为了节省成本,防止公司破产。去年11月马斯克曾说Twitter每天亏损400多万美元。刚接管Twitter马斯克便裁员几千人,相当于员工总数的一半,而且公司不再提供免费食品。 因为一些账单未付Twitter被告上法庭,T...
-
- 在正在举行的小米 SU7 北京车展发布会上,雷军公布了目前小米 SU7 购买者的一些数据。 雷军称,目前小米 SU7 女性购买者占比高达 28%,女性车主预计占比 40-50%;BBA 用户购买者占比 29%,苹果用户购买者占比 51.9%。 雷军还表示,小米 SU7 正在全力扩充产能,4 月 18 日标准版、Max 版开始交付,5 月底 Pro 版开始交付,6 月份月交付超过 1 万台。他透露,小米 SU7 今年交付目标 10 万台,今年销售门店覆盖 46 城 219 家,服务中心覆盖 86 城 143 家。作者:远洋原文链接:IT之家(ithome.com)

-
- 简介 除了测试,测试数据创建、需求跟踪和测试报告等任务也可自动化。 随着迭代,可自动化的内容越来越多: 什么应该被自动化? 与人工测试相比,具备明显收益 ·如果失败会对业务造成相当大的损失的业务功能或用户流;自动化测试有助于经常验证这些功能。 · 需要针对应用程序的每个构建或发布版本运行的测试,如烟雾测试、正常性测试和回归测试。 · 需要针对多种配置运行的测试,如不同平台和浏览器的组合。 · 涉及大量测试数据集或输入大量数据的测试,例如填写很长的表格,因为测试自动化有助于实现扩大覆盖范围,减少工作量和提高可靠性。 · 报告,自动化测试报告减少了人工干预,并产生频繁和最新的...
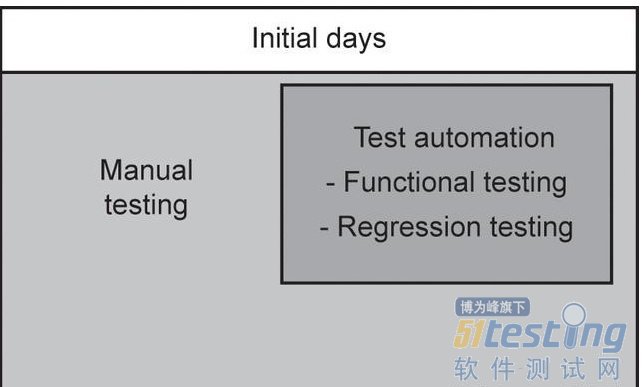
-
- 如何选择功能测试工具:7个关键因素10-28在谷歌搜索引擎中输入"如何选择一种测试工具?" ,你会发现答案从开源软件到各种基于不同假设的最佳繁衍物,五花八门。一类结果是假定在理想状态下你需要一个不需要编码的、基于GUI界面的测试工具,而另一类结果宣称是可以编码的自动化测试,第三类则是更加感兴趣于测试工具中的例子和文档是否可被执行。Liquidity Services公司的质量和测试主管Connor Roberts曾说过,有时公司引入或更换测试工具,仅仅是因为新上任的经理在上一家公司有此工具的使用经验,或者为了节省开支,使得预算单上的数据看起来更漂亮。Connor Roberts说:最终每天都使用工具的团队发现自己和以...
- 日前,吉祥航空母公司均瑶集团举行吉祥大出行空中全球发布会,正式发布了“吉祥大出行”战略以及智能出行科技品牌“吉祥汽车”。 不过,官方在发布会上并未公布新车详细信息,仅透露吉祥汽车旗下首款产品预计在明年第二季度于国内上市,第三季度走向海外市场。 据介绍,该车将拥有吉祥汽车全栈自研的、具有独立知识产权的全新智能电动平台,一开始就按照中欧双五星安全标准打造,是适合全球市场的智能终端。 新车采用一体式设计,理念来源于航空美学的“极简主义”,灵感来源于人类抬头仰望数千年的苍穹。 吉祥汽车主理人张广浩表示,流畅的整车姿态,实现同级别车型最优风阻系数。 据国内媒体报道,上海均瑶(集团)有限公司...
-

&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=146935&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=146935&pic=http://quan.51testing.com/ueditor/php/upload/image/20240425/1714013610742381.jpg){kind=link}
{kind=link}
- 关于我们 联系我们 版权声明 广告服务 站长统计
- 建议使用IE 11.0以上浏览器,800×600以上分辨率,法律顾问:上海兰迪律师事务所 项棋律师
- 版权所有 上海博为峰软件技术股份有限公司 Copyright©51testing.com 2003-2024, 沪ICP备05003035号
- 投诉及意见反馈:webmaster@51testing.com; 业务联系:service@51testing.com021-64471599-8017

- 51testing软件测试圈微信