 1
1 3
3


- 关于MySQL性能优化方案,掌握这一篇就够了!
我最近在做性能测试时,发现MySQL的问题还蛮严重的。
像我这种有对性能要求这么高的人,例如SQL语句没有走索引,或者没有设置索引
当时想象一下我的心情.....(次数省略5万字)
天气炎热,切勿烦躁。
接下来,下面咱们聊一聊MySQL性能优化~~
一、设置索引
索引是一种可以让SELECT语句提高效率的数据结构,可以起到快速定位的作用。
1、索引的优缺点:
优点:某些情况下使用select语句大幅度提高效率,合适的索引可以优化MySQL服务器的查询性能,从而起到优化MySQL的作用。
缺点:表行数据的变化(index、update、delect),简历在表列上的索引也会自动维护,一定程度上会使DML操作变慢。索引还会占用磁盘额外的存储空间。
2、给表列创建索引
建表时创建索引:
create table t(id int,name varchar(20),index idx_name (name));
给表追加索引:
alter table t add unique index idx_id(id);
给表的多列上追加索引
alter table t add index idx_id_name(id,name); 或者 create index idx_id_name on t(id,name);
3、查看索引
使用show语句查看t表上的索引:
show index from t;
show keys from t;–mysql中索引也被称作keys

使用show create table语句查看索引:
show create table t\G

4、删除索引:
使用alter table命令删除索引:
alter table 表 drop index 索引名
使用drop index命令删除索引:
drop index 索引名 on 表
5、索引原理:
例如一个学生信息表,我们设置学号(stu_id)为索引:
索引页之间存在一定的关联关系,一般为树形结构;分为根节点、分支节点、和叶子节点
根节点页中存放分段stu_id的起始值,以及值所对应的分支索引页号
分支索引页中存放分段stu_id的起始值,以及值所对应的叶子索引页号
叶子索引页中存放排序后的stu_id值,该值所对应的表页号, 下一个叶子索引页的页号

stu_id建立索引后,执行select name,sex,height from stu where stu_id=13查询过程如下:
① 索引页存在关联关系,先找索引页号20的根节点,13在>=11和<17的范围内,需要查找25号索引页
② 读取25号索引页,13在>=11和<14范围内,得到了26号叶子索引页
③ 读取26号叶子索引页,找到了13这个值,以及该值所对应表页的页号161,目前只得到了stu_id的值,还要得到name,sex,height等,因此需要再读一次编号为161的表页,里面存放了stu_id之外的值。
④ 读取161号表页,获得sname,sex,height等值
以上4步,只读取了3个索引页1个表页,共4个页,比读取所有表页(5000个页),按照stu_id=13挨个翻一遍效率要高,这也是有些情况下索引可以加速查询的原因。
二、分类讨论
一条 SQL 语句执行的很慢,那是每次执行都很慢呢?还是大多数情况下是正常的,偶尔出现很慢呢?所以我觉得,我们还得分以下两种情况来讨论。
1、大多数情况是正常的,只是偶尔会出现很慢的情况。
2.、在数据量不变的情况下,这条SQL语句一直以来都执行的很慢。
针对这两种情况,我们来分析下可能是哪些原因导致的。
三、针对偶尔很慢的情况
一条 SQL 大多数情况正常,偶尔才能出现很慢的情况,针对这种情况,我觉得这条SQL语句的书写本身是没什么问题的,而是其他原因导致的,那会是什么原因呢?
1、 数据库在刷新脏页(flush)
当我们要往数据库插入一条数据、或者要更新一条数据的时候,我们知道数据库会在内存中把对应字段的数据更新了,但是更新之后,这些更新的字段并不会马上同步持久化到磁盘中去,而是把这些更新的记录写入到 redo log 日记中去,等到空闲的时候,在通过 redo log 里的日记把最新的数据同步到磁盘中去。
刷脏页有下面4种场景:
①redolog写满了:redo log 里的容量是有限的,如果数据库一直很忙,更新又很频繁,这个时候 redo log 很快就会被写满了,这个时候就没办法等到空闲的时候再把数据同步到磁盘的,只能暂停其他操作,全身心来把数据同步到磁盘中去的,而这个时候,就会导致我们平时正常的SQL语句突然执行的很慢,所以说,数据库在在同步数据到磁盘的时候,就有可能导致我们的SQL语句执行的很慢了。
②内存不够用了:如果一次查询较多的数据,恰好碰到所查数据页不在内存中时,需要申请内存,而此时恰好内存不足的时候就需要淘汰一部分内存数据页,如果是干净页,就直接释放,如果恰好是脏页就需要刷脏页。
③MySQL 认为系统“空闲”的时候:这时系统没什么压力。
④MySQL 正常关闭的时候:这时候,MySQL 会把内存的脏页都 flush 到磁盘上,这样下次 MySQL 启动的时候,就可以直接从磁盘上读数据,启动速度会很快。
2. 拿不到锁我能怎么办
这个就比较容易想到了,我们要执行的这条语句,刚好这条语句涉及到的表,别人在用,并且加锁了,我们拿不到锁,只能慢慢等待别人释放锁了。或者,表没有加锁,但要使用到的某个一行被加锁了。
如果要判断是否真的在等待锁,我们可以用 show processlist这个命令来查看当前的状态哦,这里我要提醒一下,有些命令最好记录一下。
四、针对一直都这么慢的情况
如果在数据量一样大的情况下,这条 SQL 语句每次都执行的这么慢,那就就要好好考虑下你的 SQL 书写了,下面我们来分析下哪些原因会导致我们的 SQL 语句执行的很不理想。
我们先来假设我们有一个表,表里有下面两个字段,分别是主键 id,和两个普通字段 c 和 d。
mysql> CREATE TABLE `t` ( `id` int(11) NOT NULL, `c` int(11) DEFAULT NULL, `d` int(11) DEFAULT NULL, PRIMARY KEY (`id`)) ENGINE=InnoDB;
1、没用到索引
没有用上索引,我觉得这个原因是很多人都能想到的,例如你要查询这条语句
select * from t where 100 <c and c < 100000;
a. 字段没有索引
刚好你的 c 字段上没有索引,那么抱歉,只能走全表扫描了,你就体验不会索引带来的乐趣了,所以,这回导致这条查询语句很慢。
b. 字段有索引,但却没有用索引
好吧,这个时候你给 c 这个字段加上了索引,然后又查询了一条语句
select * from t where c - 1 = 1000;
我想问大家一个问题,这样子在查询的时候会用索引查询吗?
不会,如果我们在字段的左边做了运算,那么很抱歉,在查询的时候,就不会用上索引了,所以呢,大家要注意这种字段上有索引,但由于自己的疏忽,导致系统没有使用索引的情况了。
正确的查询应该如下
select * from t where c = 1000 + 1;
有人可能会说,右边有运算就能用上索引?难道数据库就不会自动帮我们优化一下,自动把 c - 1=1000 自动转换为 c = 1000+1。
c. 函数操作导致没有用上索引
如果我们在查询的时候,对字段进行了函数操作,也是会导致没有用上索引的,例如
select * from t where pow(c,2) = 1000;
这里我只是做一个例子,假设函数 pow 是求 c 的 n 次方,实际上可能并没有 pow(c,2)这个函数。其实这个和上面在左边做运算也是很类似的。
所以呢,一条语句执行都很慢的时候,可能是该语句没有用上索引了,不过具体是啥原因导致没有用上索引的呢,你就要会分析了,我上面列举的三个原因,应该是出现的比较多的吧。
2.、数据库自己选错索引了
我们在进行查询操作的时候,例如
select * from t where 100 < c and c < 100000;
我们知道,主键索引和非主键索引是有区别的,主键索引存放的值是整行字段的数据,而非主键索引上存放的值不是整行字段的数据,而且存放主键字段的值。 里面有说到主键索引和非主键索引的区别。
也就是说,我们如果走 c 这个字段的索引的话,最后会查询到对应主键的值,然后,再根据主键的值走主键索引,查询到整行数据返回。
好吧扯了这么多,其实我就是想告诉你,就算你在 c 字段上有索引,系统也并不一定会走 c 这个字段上的索引,而是有可能会直接扫描扫描全表,找出所有符合 100 < c and c < 100000 的数据。
为什么会这样呢?
其实是这样的,系统在执行这条语句的时候,会进行预测:究竟是走 c 索引扫描的行数少,还是直接扫描全表扫描的行数少呢?显然,扫描行数越少当然越好了,因为扫描行数越少,意味着I/O操作的次数越少。
如果是扫描全表的话,那么扫描的次数就是这个表的总行数了,假设为 n;而如果走索引 c 的话,我们通过索引 c 找到主键之后,还得再通过主键索引来找我们整行的数据,也就是说,需要走两次索引。而且,我们也不知道符合 100 c < and c < 10000 这个条件的数据有多少行,万一这个表是全部数据都符合呢?这个时候意味着,走 c 索引不仅扫描的行数是 n,同时还得每行数据走两次索引。
所以呢,系统是有可能走全表扫描而不走索引的。那系统是怎么判断呢?
判断来源于系统的预测,也就是说,如果要走 c 字段索引的话,系统会预测走 c 字段索引大概需要扫描多少行。如果预测到要扫描的行数很多,它可能就不走索引而直接扫描全表了。
那么问题来了,系统是怎么预测判断的呢?这里我给你讲下系统是怎么判断的吧,虽然这个时候我已经写到脖子有点酸了。
系统是通过索引的区分度来判断的,一个索引上不同的值越多,意味着出现相同数值的索引越少,意味着索引的区分度越高。我们也把区分度称之为基数,即区分度越高,基数越大。所以呢,基数越大,意味着符合 100 < c and c < 10000 这个条件的行数越少。
所以呢,一个索引的基数越大,意味着走索引查询越有优势。
那么问题来了,怎么知道这个索引的基数呢?
系统当然是不会遍历全部来获得一个索引的基数的,代价太大了,索引系统是通过遍历部分数据,也就是通过采样的方式,来预测索引的基数的。
重点来了,居然是采样,那就有可能出现失误的情况,也就是说,c 这个索引的基数实际上是很大的,但是采样的时候,却很不幸,把这个索引的基数预测成很小。例如你采样的那一部分数据刚好基数很小,然后就误以为索引的基数很小。然后系统就不走 c 索引了,直接走全部扫描了。
所以呢,说了这么多,得出结论:由于统计的失误,导致系统没有走索引,而是走了全表扫描,而这,也是导致我们 SQL 语句执行的很慢的原因。
不过呢,我们有时候也可以通过强制走索引的方式来查询,例如
select * from t force index(a) where c < 100 and c < 100000;
我们也可以通过
show index from t;
来查询索引的基数和实际是否符合,如果和实际很不符合的话,我们可以重新来统计索引的基数,可以用这条命令
analyze table t;
来重新统计分析。
既然会预测错索引的基数,这也意味着,当我们的查询语句有多个索引的时候,系统有可能也会选错索引,这也可能是 SQL 执行的很慢的一个原因。
五、总结
一个 SQL 执行的很慢,我们要分两种情况讨论:
1、大多数情况下很正常,偶尔很慢,则有如下原因
a. 数据库在刷新脏页,例如 redo log 写满了需要同步到磁盘。
b. 执行的时候,遇到锁,如表锁、行锁。
2、这条 SQL 语句一直执行的很慢,则有如下原因。
a . 没有用上索引:例如该字段没有索引;由于对字段进行运算、函数操作导致无法用索引。
b. 数据库选错了索引。
- -1.00 查看剩余0%
- 【留下美好印记】赞赏支持

热门文章
最新讲堂
- 推荐阅读
- 换一换
- 最近在看一些底层的东西。driver翻译过来是驱动,司机的意思。如果将webdriver比做成司机,竟然非常恰当。 我们可以把WebDriver驱动浏览器类比成出租车司机开出租车。在开出租车时有三个角色: · 乘客:他/她告诉出租车司机去哪里,大概怎么走。 · 出租车司机:他按照乘客的要求来操控出租车。 · 出租车:出租车按照司机的操控完成真正的行驶,把乘客送到目的地。 在WebDriver中也有类似的三个角色: · 自动化测试代码:自动化测试代码发送请求给浏览器的驱动(比如火狐驱动、谷歌驱动)。 · 浏览器的驱动:它来解析这些自动化测试的代码,解析后把它们发送给浏...
-
- 软件测试之BUG处理流程——软件测试圈02-10什么是软件测试缺陷?测验行业的习惯叫法,即Bug管理。在软件或程序开发过程中,编程人员编码、系统设计结构不合理等都会导致错误报错,影响系统程序的正常运行。并且软件测试的目的之一,就是通过手工测试或者自动测试工具来执行操作,测试发现这些Bug,并对代码进行修复。 一、软件测试缺陷分类 1、网络环境;如果测试过程中,外部网络不稳定,也有可能造成软件测试缺陷。例如性能测试对网络环境的配置要求比较高,网络出现延迟、卡顿等都会影响测试结果。 2、硬件环境;由于磁盘空间内存不足、CPU运行速度等造成的系统瓶颈问题。对操作系统、服务器等硬件配置的测试也可能出现偏差。 3、数据问题;由于不同环境i...
- 公司后端服务使用 java 重构后,很多接口采用了阿里的 dubbo 协议。而 python 是无法直接调用 dubbo 接口的,但可以通过 telnet 调用,具体可以通过 telnetlib 模块的 Telnet类 来调用,只需要四行代码即可实现:import telnetlib # 创建telnet类对象 conn = telnetlib.Telnet() # 连接dubbo接口地址 conn.open(host, port) #1.cmd命令格式: 接口全名字.方法名(参数1,参数2,参数3...参数n)&nbs...
-
- 由于面试官还要摸鱼刷沸点,不想花那么多时间一个个面,所以采用群面的方式,就出现了这样的场景。 交锋 面试官:方便说下离职原因吗? 网友1:不方便 网友2:在前公司长期工作量有些太大了,我自己身体上也出现了一些信号,有段时间都完全睡不着觉,所以需要切换一个相对来讲工作量符合我个人要求的,比如说周末可以双休这样一个情况,这个对我现在的选择来讲还蛮重要的。 网友3:本来已经定好的前端负责人(组长),被关系户顶掉了,我需要一个相对公平的竞争环境,所以打算换个公司。 网友4:实不相瞒,一年前我投过咱们公司(或者面试过但没过),一年了,你知道我这一年是怎么过的吗,因为当时几轮面试都很顺利的...

-
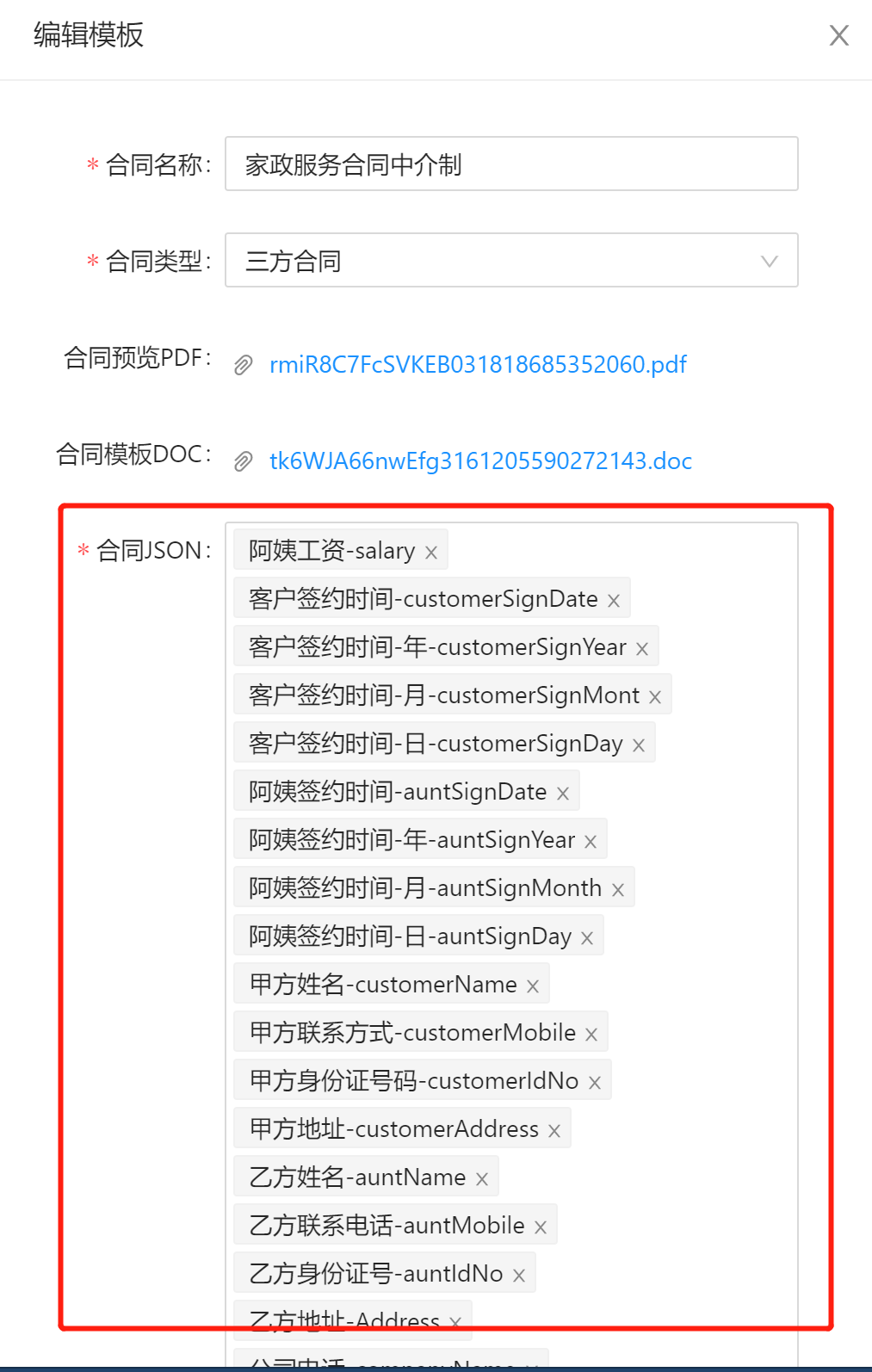
- 【项目经历】电子合同签署问题排查方向10-20最近的项目中,将很多原本的纸质合同转移到线上,变成电子合同,包括电子合同的制作,审核,电子合同的生成,电子合同的签署等环节,也容易出现一部分问题,一下列举碰到问题的排查方向:APP端生成电子合同,提示:系统异常,请和管理员联系:合同创建失败,请先联系客服大概率原因:公司名称变更了,在资源中心的elec_contract_user表中,存放了开户信息,查看标品中的公司名称和开户信息中的公司名称,是否一致。雇主端签署电子合同,提示:请先开户原因:在生成电子合同后,修改合同中的客户名字,查看合同中的客户名字和elec_contract_user表中的开发信息是否一致电子合同中存在未替换的替换符原因一...


,被关系户顶掉了,我需要一个相对公平的竞争环境,所以打算换个公司。 网友4:实不相瞒,一年前我投过咱们公司(或者面试过但没过),一年了,你知道我这一年是怎么过的吗,因为当时几轮面试都很顺利的...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=146754&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=146754&pic=http://quan.51testing.com/ueditor/php/upload/image/20240122/1705915456939908.jpg){kind=link}
{kind=link}
- 关于我们 联系我们 版权声明 广告服务 站长统计
- 建议使用IE 11.0以上浏览器,800×600以上分辨率,法律顾问:上海兰迪律师事务所 项棋律师
- 版权所有 上海博为峰软件技术股份有限公司 Copyright©51testing.com 2003-2024, 沪ICP备05003035号
- 投诉及意见反馈:webmaster@51testing.com; 业务联系:service@51testing.com021-64471599-8017

- 51testing软件测试圈微信