 2
2 2
2


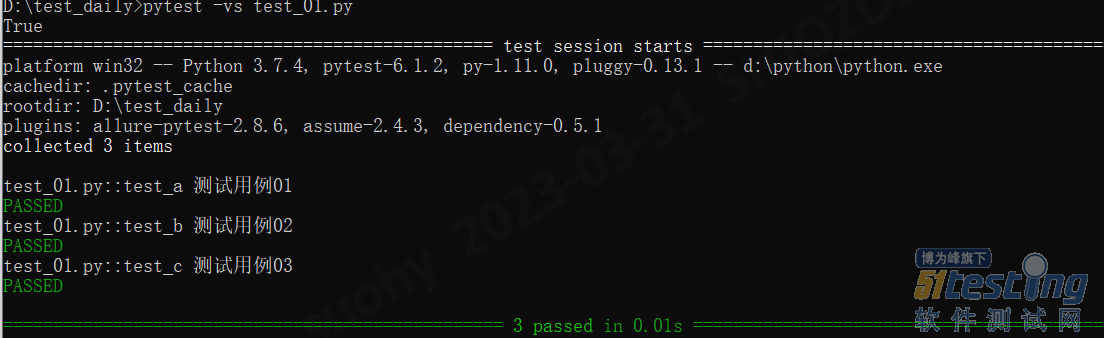
- 自从学了这套框架,自动化+性能都搞定了(1)——软件测试圈
框架介绍
1、HttpRunner
是一款面向 HTTP(S) 协议的通用测试框架,只需编写维护一份YAML/JSON脚本,即可实现自动化测试、性能测试、线上监控、持续集成等多种测试需求。
2、Locust
Locust是一款易于使用的分布式用户负载测试工具。它用于对网站(或其他系统)进行负载测试,并确定系统可以处理多少并发用户。HttpRunner 通过复用Locust ,可以在无需对 YAML/JSON 进行任何修改的情况下,直接运行性能测试。
3、 httprunner使用手册
附httprunner中文使用文档地址:cn.httprunner.org/
环境安装
1 安装httprunner: pip install httprunner==2.2.5
2 安装har2case: pip install har2case
3 检查安装是否成功:hrun -h/-v;har2case -h/-v
4 安装locust: pip install locustio
新增命令
在 HttpRunner 安装成功后,系统中会新增如下 5 个命令:
1 httprunner: 核心命令。
2 hrun: httprunner 的缩写,功能与 httprunner 完全相同。
3 locusts: 基于 Locust 实现性能测试。
4 har2case: 辅助工具,可将标准通用的 HAR 格式(HTTP Archive)转换为YAML/JSON格式的测试用例。
用例生成
(1)利用fiddler/charles对接口数据进行抓包,将结果导出为XX.har文件。


(2)将导出的XX.har文件转化为json文件/yaml文件。
转化为json文件:har2case xx.har 转化为yaml文件:har2case xx.har -2y/--to-yml
(3) 转化成功后的yaml文件如下:

status_code: 请求的状态码
headers.Content-Type: 将响应头的内容格式做验证
content.msg: 响应内容的关键字作为验证
config: 作为整个测试用例集的全局配置项,包括变量(variables,name)
test: 对应单个测试用例
name 这个test的名字(用例的名称)
request 这个test具体发送http请求的各种信息, 如下:
url 请求的路径 (若config中有定义base_url, 则完整路径是用 base_url + url )
method 请求方法 POST, GET等等
headers: 请求头
请求体: json格式的数据
validate(断言): 完成请求后, 所要进行的验证内容. 所有验证内容均通过该test才算通过,否则失败.
参数化:
testcases: - name: call demo_testcase with data 1 testcase: testcases/test_login.yml parameters: # username: ["admin1","admin"] -username: - ["admin1"] - ["admin"]
测试用例(testcase)嵌套testcases
测试用例集是测试用例的无序集合,集合中的测试用例应该都是相互独立,不存在先后依赖关系的。
如果确实存在先后依赖关系怎么办,例如登录功能和下单功能。正确的做法应该是,在下单测试用例的前置步骤中执行登录操作。
- config: name:order product - test: name:login testcase:testcases/login.yml - test: name:add to cart api:api/add_cart.yml - test: name:make order api:api/make_order.yml
变量取值:
在测试用例内部,HttpRunner划分了两层变量空间作用域context。
·config:作为整个测试用例的全局配置项,作用域为整个测试用例;
· test:测试步骤的变量空间context会继承或覆盖config中的定义的内容;
- 若某变量在config中定义了,在某test中没有定义,则该test会继承该变量
- 若某变量在config中和某test中都定义了,则该test中使用自己定义的变量值
· 各个测试步骤test的变量空间相互独立,互不影响;
· 如需在多个测试步骤test中传递参数值,则需要使用extract关键字,并且只能从前往后传递
响应头和响应体的提取:
//response headers:
{
“Content - Type”:"application/json",
“Content - Length”:69
}
//response body:
{
“success”:false,
“person”:{
"name":{
“first_name”:"cs",
“last_name”:"css",
},
“age”:29,
“cities”:["Guangzhou","Shenzhen"]
}
}那么对应的字段提取方式就为:
“headers.content-type”=>"application/json" “headers.content-length”=>69 “body.success"/"content.success"/"text.success=>false "content.person.name.first_name"=>"cs" "content.person.age"=>29 "content.person.cities"=>["Guangzhou","Shenzhen"] "content.person.cities.0"=>"Guangzhou" "content.person.cities.1"=>"Shenzhen"
可以看出,通过点( . )运算符,我们可以从上往下逐级定位到具体的字段:
· 当下一级为字典时,通过.key来指定下一级的节点,例如.person,指定了content下的person节点;
· 当下一级为列表时,通过.index来指定下一级的节点,例如.0,指定了cities下的第一个元素。
提取HTML的内容(正则表达式)

上传文件场景

作者:软件测试自动化测试
- -1.00 查看剩余0%
- 【留下美好印记】赞赏支持

热门文章
最新讲堂
- 推荐阅读
- 换一换
- Python中如何添加测试用例?05-12polita3.0的框架接口如何编写测试用例如何运行测试用例在利用caster平台进行接口管理以后,我们可以将所有的中心放在编写测试用例case。这个教程可以帮助大家快速上手添加测试用例。1、polita3.0的框架接口```python ├── bin 这里定义了怎么生成open-api ├── ci &...

- 前言 在自动化测试中,自动化测试用例设计原则就是执行过程时不能存在依赖顺序,那么如果测试用例需要按照指定顺序执行,这个时候应该怎么做呢?目前单元测试框架中unittest没有办法改变测试用例的执行顺序,但是另一个单元测试框架pytest可以做到,辅助测试人员更改测试用例的执行顺序,今天小编简单的介绍几种,如何通过pytest进行更改自动化测试用例的执行顺序 pytest pytest的执行顺序想必大家都清楚,是通过ascii码进行收集的,然后通过文件中从上往下的执行顺序进行运行,我们只需要将我们的测试用例在编写时,按照从上往下的顺序进行编写。 # coding:utf-8...
-
- 尽管有报道称苹果公司今年至少发生了四次较小规模的裁员事件,但 2024 年苹果公司的员工人数仍有所增长。苹果公司在上周提交的文件中披露,截至 9 月底,该公司在全球拥有约 16.4 万名全职员工。 这一数字高于苹果一年前公布的 16.1 万名全职员工。 这些数字包括公司员工(如软件工程师)和零售店员工。 苹果公司目前的员工人数与 2022 年持平,而去年则略有下降。 根据苹果公司的文件,该公司各年的全职员工人数如下: · 2024:164000 · 2023:161000 · 2022:164000 · 2021:154000 · 2020:147000 · 20...
-
- 据报道,OpenAICEO山姆·阿尔特曼(SamAlteman)最近接受媒体采访时表示,他“有点害怕”人工智能技术及其对劳动力、选举和虚假信息传播产生的影响。 最近几个月火遍全球的ChatGPT聊天机器人正是由OpenAI开发的,它能以类似于人类的方式回答问题,从而引发了新一轮人工智能热潮。 “我觉得大家真的从ChatGPT那里获得了乐趣。”阿尔特曼接受采访时说。 他很看好人工智能技术的转型潜力,认为这最终将反映“人类集体的力量、创造力和意志”。 中国科技公司百度最近也举行了发布会,推出了与ChatGPT竞争的文心一言。 谷歌和微软同样在积极参与人工智能竞争。微软选择与OpenA...
-
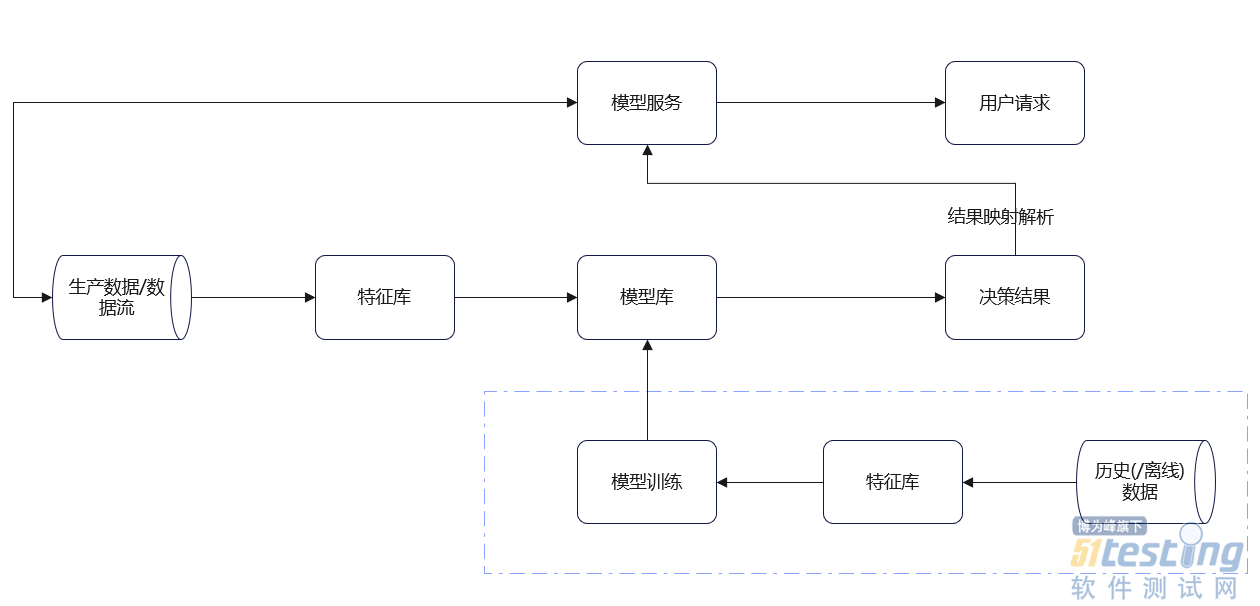
- 1、引言 在上一篇中,我们聊到了《AI测试技能卷起来!目标检测算法测试流程与方法总结》,反响还不错。但是,也有测试同学给我留言:“能不能讲一讲模型工程的测试流程和方法”。这当然没问题了, 因为在整个工程中,算法模型只是其中的一个环节,我们模型测试完成后,需要部署到系统中,这样才能让模型真正的应用于业务中。 为了更好的让你们理解模型在系统中的流程,我以我的工作为例(当然,处于职业操守,部分内容进行脱敏),以流程图的形式给大家展示。 通过上图,大家可以了解到模型的整体架构。 这里说两点: 1)数据流:即数据解析,保证数据的质量; 2)特征库:即数据处理,提取数据特征进行...
-

{kind=link}
{kind=link}
,以流程图的形式给大家展示。 通过上图,大家可以了解到模型的整体架构。 这里说两点: 1)数据流:即数据解析,保证数据的质量; 2)特征库:即数据处理,提取数据特征进行...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=147167&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=147167&pic=http://quan.51testing.com/ueditor/php/upload/image/20240816/1723794323886606.png){kind=link}
- 关于我们 联系我们 版权声明 广告服务 站长统计
- 建议使用IE 11.0以上浏览器,800×600以上分辨率,法律顾问:上海兰迪律师事务所 项棋律师
- 版权所有 上海博为峰软件技术股份有限公司 Copyright©51testing.com 2003-2024, 沪ICP备05003035号
- 投诉及意见反馈:webmaster@51testing.com; 业务联系:service@51testing.com021-64471599-8017

- 51testing软件测试圈微信