 12
12 12
12


- 爬虫的基本原理?爬虫需要掌握哪些东西?——软件测试圈
什么是网络爬虫?相信刚接触爬虫这个词的人都有这样的疑问,网络爬虫可以做什么?它是基于什么样的原理,如果想要学习爬虫,需要掌握什么知识。本文将会对这些问题做一个解释和说明,希望可以帮助正在爬虫入门阶段的朋友。
网络爬虫是捜索引擎抓取系统的重要组成部分,爬虫的主要目的是将互联网上的网页下载到本地形成一个互联网内容的镜像备份
那么网络爬虫的基本结构和工作流程是什么样的呢?
基本的工作流程如下:
首先可以选择一部分精心挑选的种子url;
将这些URL放入待抓取URL系列;
从待抓取URL队列中取出待抓取在URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载下来,存储进已下载网页库中。此外,将这些URL放进已抓取URL队列;
分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL放入待抓取URL队列,从而进入下一个循环。如此反复进行,直到遍历了整个网络或者满足某种条件后,才会停止下来。

对应的,可以将互联网的所有页面分为五个部分:
已下载未过期网页。
已下载已过期网页。
待下载网页:待抓取URL队列中的网页。
可知网页:还没有抓取下来,也没有在待抓取URL队列中,但是可以通过对已抓取页面或者待抓取URL对应页面进行分析获取到的URL。
不可知网页:爬虫无法直接抓取下载的网页。

通过以上内容,我们可以了解到:网络爬虫是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本,被广泛用于互联网搜索引擎或其他类似网站,具有一套基本的工作流程。
如果想要学习爬虫,要如何如入门呢?在入门阶段,了解下面基础的理论可以达到更好的学习效果
第一、明确抓取目的
我们需要抓取的网站内容一般来讲可以分为非结构化和结构化两种
1、非结构化的数据,
HTML文本
HTML其实理应属于结构化的文本组织,但是又因为一般我们需要的关键信息并非直接可以得到,需要进行对HTML的解析查找,甚至一些字符串操作才能得到,所以还是归类于非结构化的数据处理中。
对于HTML文本,常见解析方式有CSS选择器、XPATH、正则表达式。
一段文本
例如一篇文章,或者一句话,我们的初衷是提取有效信息,所以如果是滞后处理,可以直接存储,如果是需要实时提取有用信息,常见的处理方式如下
分词
根据抓取的网站类型,使用不同词库,进行基本的分词,然后变成词频统计,类似于向量的表示,词为方向,词频为长度。
NLP
自然语言处理,进行语义分析,用结果表示,例如正负面等。
2、关于结构化的数据
结构化的数据是最好处理,一般都是类似JSON格式的字符串,直接解析JSON数据就可以了,提取JSON的关键字段即可。
第二、知道内容从何而来
网页包含内容
这种情况是最容易解决的,一般来讲基本上是静态网页已经写死的内容,或者动态网页,采用模板渲染,浏览器获取到HTML的时候已经是包含所有的关键信息,所以直接在网页上看到的内容都可以通过特定的HTML标签得到。
Java Script代码加载内容
这种情况是由于虽然网页显示时,内容在HTML标签里面,但是其实是由于执行js代码加到标签里面的,所以这个时候内容在js代码里面的,而js的执行是在浏览器端的操作,所以用程序去请求网页地址的时候,得到的response是网页代码和js的代码,所以自己在浏览器端能看到内容,解析时由于js未执行,肯定找到指定HTML标签下内容肯定为空,这个时候的处理办法,一般来讲主要是要找到包含内容的js代码串,然后通过正则表达式获得相应的内容,而不是解析HTML标签。
Ajax异步请求
这种情况是现在很常见的,尤其是在内容以分页形式显示在网页上,并且页面无刷新,或者是对网页进行某个交互操作后,得到内容。那我们该如何分析这些请求呢?这里我以Chrome的操作为例,进行说明:
所以当我们开始刷新页面的时候就要开始跟踪所有的请求,观察数据到底是在哪一步加载进来的。然后当我们找到核心的异步请求的时候,就只用抓取这个异步请求就可以了,如果原始网页没有任何有用信息,也没必要去抓取原始网页了。
第三、了解网络请求
我们常说爬虫其实就是一堆的HTTP请求,找到待爬取的链接,不管是网页链接还是App抓包得到的API链接,然后发送一个请求包,得到一个返回包(也有HTTP长连接,或者Streaming的情况,这里不考虑),所以核心的几个要素就是:
URL;
请求方法(POST, GET);
请求包headers;
请求包内容;
返回包headers。
第四、如何突破常见的限制方式
Basic Auth
一般会有用户授权的限制,会在headers的Autheration字段里要求加入;
Referer
通常是在访问链接时,必须要带上Referer字段,服务器会进行验证,例如抓取京东的评论;
User-Agent
会要求真是的设备,如果不加会用编程语言包里自有User-Agent,可以被辨别出来;
Cookie
一般在用户登录或者某些操作后,服务端会在返回包中包含Cookie信息要求浏览器设置Cookie,没有Cookie会很容易被辨别出来是伪造请求;
也有本地通过JS,根据服务端返回的某个信息进行处理生成的加密信息,设置在Cookie里面;
Gzip
请求headers里面带了gzip,返回有时候会是gzip压缩,需要解压;
Java Script加密操作
一般都是在请求的数据包内容里面会包含一些被javascript进行加密限制的信息,例如新浪微博会进行SHA1和RSA加密,之前是两次SHA1加密,然后发送的密码和用户名都会被加密;
其他字段
因为http的headers可以自定义地段,所以第三方可能会加入了一些自定义的字段名称或者字段值,这也是需要注意的。
真实的请求过程中,其实不止上面某一种限制,可能是几种限制组合在一次,比如如果是类似RSA加密的话,可能先请求服务器得到Cookie,然后再带着Cookie去请求服务器拿到公钥,然后再用js进行加密,再发送数据到服务器。所以弄清楚这其中的原理,并且耐心分析很重要。
文章来源:百度文库
- 0.00 查看剩余0%
- 【留下美好印记】赞赏支持

热门文章
最新讲堂
- 推荐阅读
- 换一换
- Vim常用命令08-01Vim是Linux系统上最常用的文本编辑器,本文将介绍一些vim常用的命令。插入命令a 在光标后插入A 在光标所在行的行尾后插入i 在光标前插入I 在光标所在行的行首前插入o 在光标下插入新行O 在光标上插入新行gi 进入到上一次插入模式的位置<ESC> 退出插入模式定位命令:set number 设置显示行号:set nonumber 取消行号gg 到第一行G 到最后一行nG 跳到第n行:n 跳到第n行$ 移至行尾0 移至行首删除命令x 删除光标所在处的字符nx 删除光标所在处后n个字符dd 删除光标所在行ndd 删除光标在内的n行dG 删除光标所在行到文件末尾的内容D 删除光标...
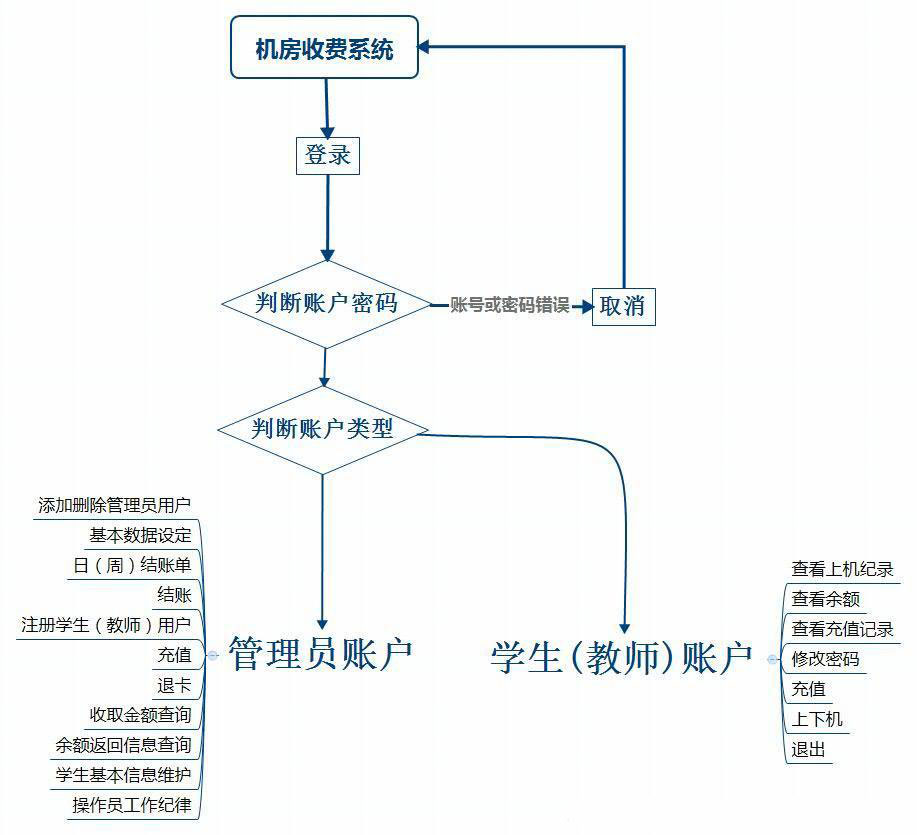
- 软件工程之概要设计说明书——软件测试圈04-291引言1.1编写目的软件设计结构的具体任务是将一个复杂系统按功能划分,建立模块的层次结构及调用关系,确定模块间的接口接人机界面等。数据库结构设计包括特征描述,确定数据库的的结构特性,以及数据库的设计。此概要设计说明书是为了说明整个系统的体系结构,以及需求用例的各个功能点在结构中的体现,为系统的详细设计人员进行详细设计师的输入参考文档。1.2背景说明:待开发软件系统的名称:机房收费系统;列出此项目的任务提出者:米新江教授。开发者:杨银平用户以及将运行该软件的计算站(中心):廊坊师范学院机房电脑以及学生或教师个人笔记本电脑。1.3定义列出本文件中用到的专门术语的定义和外文首字母组词的原词组。1.4...
- 关于接口测试的总结——软件测试全05-191、接口测试:是测试系统组件间接口的一种测试。主要用于检测外部系统于系统之间以及系统内部各个子系统之间的交互点。重点测试的时数据的交换,传递和控制管理过程,以及系统间的相互逻辑依赖关系等等,这要求对业务逻辑有一定程度上的理解,对数据流向有较好的定位。2、接口测试的分类:系统与系统之间的调用(如分享时,微信会提供接口给“跑向珠峰”);上层服务对下层服务的调用;服务之间的调用(如添加一条数据时,会先调用数据查询的服务,查询改数据是否是重复数据)。不同类型的接口测试方法可能不一致,但总体来说,不管是哪种类型,被测接口即为服务方,测试手段为客户方,接口测试的目的就是:通过我们的测试手段,去验证满足其声...
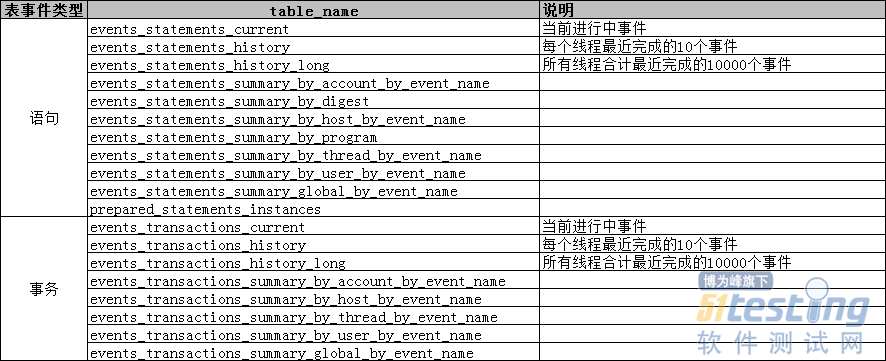
- 1.背景说明 对于使用关系型数据库的系统而言,在系统投产上线后,及时发现程序运行中的慢SQL语句,能有效降低系统运行风险;对于分布式应用系统来说,在系统日常运行中,为避免因数据库长事务导致主备切换风险,实现对数据库长事务的监控,也是必不可少的。本文以MySQL数据库为例,概述通过数据库自带功能特性performance_schema实现对慢SQL和长事务的监控方法。 2.performance_schema特性介绍 (1)performance_schema 是运行在较低级别的用于监控MySQL Server运行过程中的资源消耗、资源等待等情况的一个功能特性,可以高效便捷实...
-
- 想查看小程序的请求,使用wireshark捣鼓了半天还是无法解析微信小程序的HTTPS协议,于是使用Fiddler试试。Tools --> Options重启 Fiddler点击右边的 Filter 选项卡。然后点击 Actions --> Run Filterset Now接着点开PC微信小程序,就能看到请求列表。双击右边某一行即可展开详细信息显示请求的时间在左侧的列表区域头部任意栏上鼠标右键,选择 Customize Columns,然后Add,就会多出一列时间。需要注意的是,Fiddler 如果异常退出的话,会导致浏...

-


:廊坊师范学院机房电脑以及学生或教师个人笔记本电脑。1.3定义列出本文件中用到的专门术语的定义和外文首字母组词的原词组。1.4...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=117036&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=117036&pic=http://quan.51testing.com/ueditor/php/upload/image/20210429/1619662053698730.jpg){kind=link}
performance_schema 是运行在较低级别的用于监控MySQL Server运行过程中的资源消耗、资源等待等情况的一个功能特性,可以高效便捷实...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=147280&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=147280&pic=http://quan.51testing.com/ueditor/php/upload/image/20241008/1728377631987804.png){kind=link}
{kind=link}
- 关于我们 联系我们 版权声明 广告服务 站长统计
- 建议使用IE 11.0以上浏览器,800×600以上分辨率,法律顾问:上海兰迪律师事务所 项棋律师
- 版权所有 上海博为峰软件技术股份有限公司 Copyright©51testing.com 2003-2024, 沪ICP备05003035号
- 投诉及意见反馈:webmaster@51testing.com; 业务联系:service@51testing.com021-64471599-8017

- 51testing软件测试圈微信