 0
0 0
0


- 这么香的DBSCAN算法你确定不用?——软件测试圈
机器学习中各式各样的聚类算法层出不穷,包括层次聚类、系统聚类、K中心聚类、DBSCAN聚类等等。DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一个比较有代表性的基于密度的聚类算法,它最大的优点是能够把具有足够高密度的区域划分为簇,并在具有噪声的空间中发现任意形状的聚类,因而被广泛应用。
01
传统DBSCAN聚类算法采用穷举搜索进行数据的划分,通过在聚类过程中多次遍历待划分数据得到划分结果。这种算法称为蛮力算法,时间复杂度达到了O(n2),数据量较少时可以在较短时间内完成数据划分。

02
Kd-树是K-dimension tree的缩写,是对数据点在k维空间划分的一种数据结构,主要应用于多维空间关键数据的搜索。本质上说,Kd-树就是一种平衡二叉树。所以它的增加、删除、查询时间复杂度都是O(logn)。
首先必须搞清楚的是,kd-树是一种空间划分树,说白了,就是把整个空间划分为特定的几个部分,然后在特定空间的部分内进行相关搜索操作。想像一个三维空间,kd-树按照一定的划分规则把这个三维空间划分了多个空间,如下图所示:

03
为了解决传统DBSCAN聚类算法的低效率问题,我们将Kd-树数据结构与该算法相结合,在进行聚类之前,先对待聚类数据创建Kd-树,使用空间搜索算法更高效地进行数据划分。整个数据划分流程图如下图示:

04
通过流程图我们可以知道,Kd-树DBSCAN聚类算法会首先对待聚类数据创建kd-树,然后通过空间搜索算法检查数据中每点的r邻域来搜索簇。如果点p的r邻域包含的点多于MinPts,则创建一个以p为核心对象的新簇。通过迭代的聚集从这些核心对象直接密度可达的对象来达到数据划分的目的。当没有新的数据点可以添加到任何簇时,算法结束。
05
Kd-树创建伪代码:
kdtree (list of points pointList, int depth)
{
// Select axis based on depth so that axis cycles through all valid values
var int axis := depth mod k;
// Sort point list and choose median as pivot element
select median by axis from pointList;
// Create node and construct subtrees
var tree_node node;
node.location := median;
node.leftChild := kdtree(points in pointList before median, depth+1);
node.rightChild := kdtree(points in pointList after median, depth+1);
return node;
}DBSCAN聚类算法伪代码:
DBSCAN(D, eps, MinPts) C = 0 //类别标示 for each unvisited point P in dataset D //遍历 mark P as visited //已经访问 NeighborPts = regionQuery(P, eps) //计算这个点的邻域 if sizeof(NeighborPts) < MinPts //不能作为核心点 mark P as NOISE //标记为噪音数据 else //作为核心点,根据该点创建一个类别 C = next cluster expandCluster(P, NeighborPts, C, eps, MinPts) //根据该核心店扩展类别 expandCluster(P, NeighborPts, C, eps, MinPts) add P to cluster C //扩展类别,核心店先加入 for each point P' in NeighborPts //然后针对核心店邻域内的点,如果该点没有被访问, if P' is not visited mark P' as visited //进行访问 NeighborPts' = regionQuery(P', eps) //如果该点为核心点,则扩充该类别 if sizeof(NeighborPts') >= MinPts NeighborPts = NeighborPts joined with NeighborPts' if P' is not yet member of any cluster //如果邻域内点不是核心点,并且无类别,比如噪音数据,则加入此类别 add P' to cluster C regionQuery(P, eps) //计算邻域 return all points within P's eps-neighborhood
06
所以,各位机器学习、深度学习大佬们,不要再拘泥于传统DBSCAN聚类算法进行图像处理、数据分析啦,对于一个高分辨率图像,数以千百万级的像素点进行数据划分时,对于O(n2)的时间复杂度来说,传统算法带来的时间开销是相当大的。为何不将数据结构Kd-树与其加以融合,在完全相同的聚类效果面前,花费时间更少的算法它不香吗?哈哈~
作者:樊松松
来源:http://www.51testing.com/html/58/n-4479058.html

- 0.00 查看剩余0%
- 【留下美好印记】赞赏支持

热门文章
最新讲堂
- 推荐阅读
- 换一换
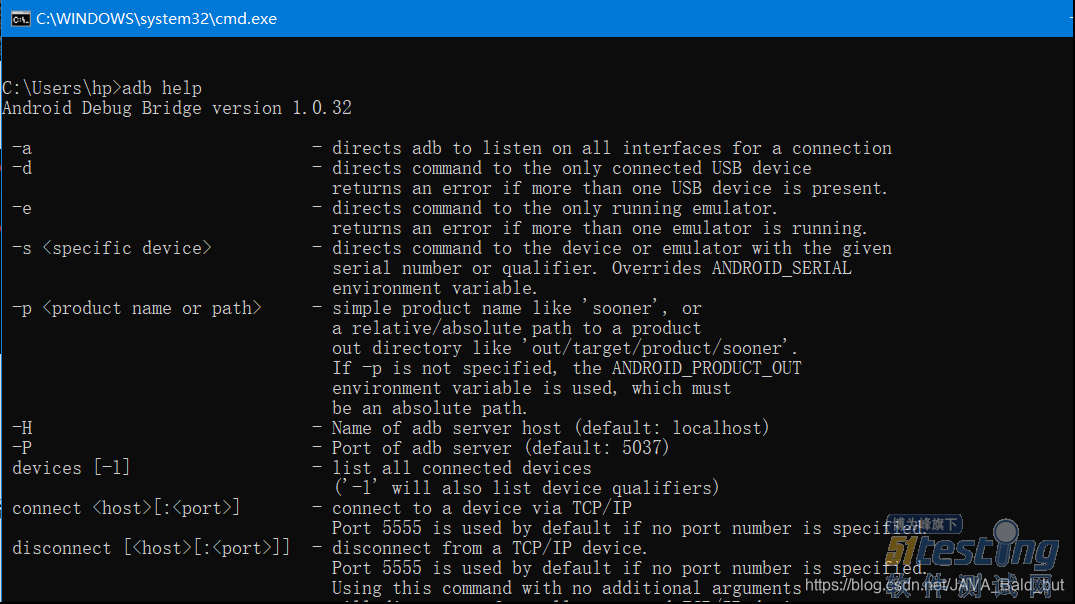
- 什么是monkey测试? 以下是官方说法: 我所认为的monkey测试:指像猴子一样,不知道程序的任何用户交互方面的知识,就对界面进行无目的、乱点乱按的操作; 我想要的monkey测试:不用熟悉业务逻辑,通过界面随机测试,发现浅层的交互问题、前端逻辑问题。 Monkey测试的优点有哪些? 1. 自动化:Monkey 测试是自动化的,无需手动操作,可以节省测试人员的时间和精力。 2. 随机性:Monkey 测试的随机性可以发现一些普通的测试方法可能遗漏的问题。 3. 广泛性:Monkey 测试可以覆盖应用程序的大部分功能,包括一些边缘情况。 4. 压力测试:Monk...
-
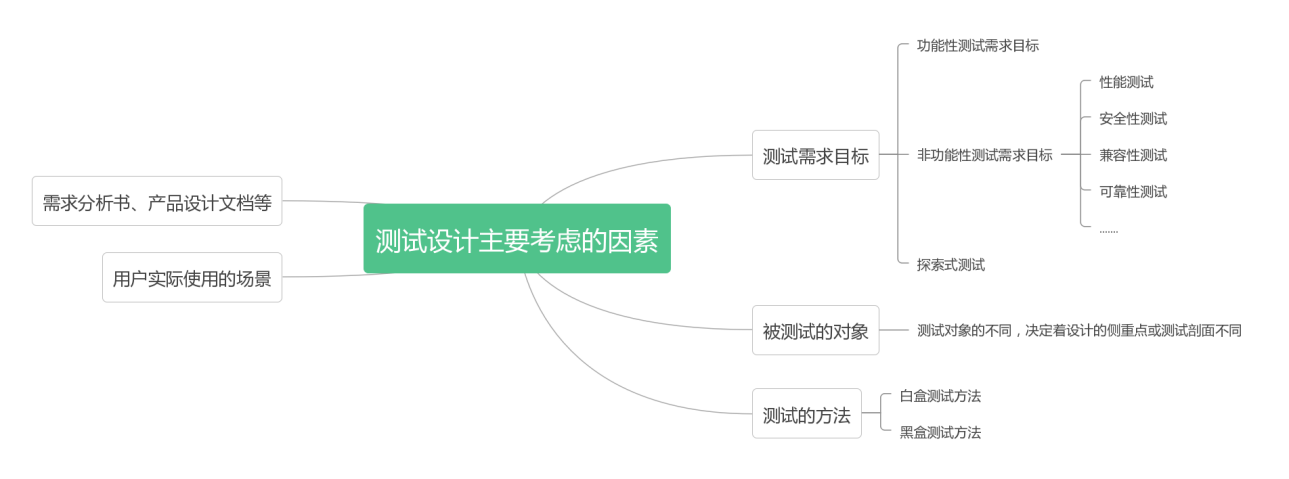
- 一、正确认识测试设计 测试设计是从特定的测试依据中得到用例,用于实现特定测试覆盖的方法。上面中的测试依据指的是有关测试的信息,比如项目背景、业务需求、领域知识、团队、进度、预算、风险等等,这些因素在经过测试分析后就是特定的测试依据,它们影响着测试设计与执行。测试设计是测试整个过程的总纲,通常是测试人员的测试思路的体现。在测试界中,有着测试设计是测试的灵魂,也是测试人员的必修课之说。 二、测试设计的原则及要考虑的因素 在测试过程中,测试人员不可能穷举所有的测试场景或组合,因此在设计测试用例时,要学会抓住测试的要点或关键点,做合理的取舍,这些要点或关键点需要进行充分分析与设计,以达到理想...
-
- 测试工具推荐,高效好用01-24Fiddler:网络抓包工具Fiddler在测试中一般用于篡改接口请求或接口返回数据以测试前后端业务场景或对异常功能的兼容.它能监控进出设备的http协议请求,并且支持重新编辑请求与返回,从而测试前端页面对不同结果的反应。官网下载地址:https://www.telerik.com/fiddler2.Apifox:接口测试工具Apifox作为本土软件,在接口测试方面表现不亚于postman,它提供了完善的 API 场景测试(流程测试)功能,保证接口数据的正确性。另外具备可视化的断言、提取变量、数据库(SQL)操作等功能。除此之外还支持自定义前置/后置脚本,自动校验数据正确性。同时,也能进行测...
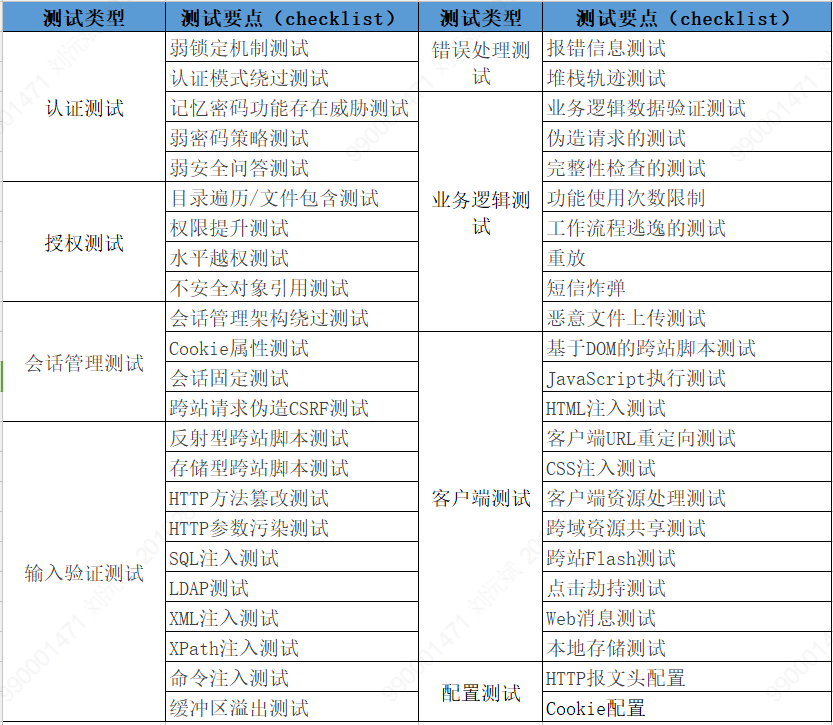
- 缘起 众所周知,系统测试是需要编写测试用例的,它是保证测试执行正确性、有效性的基础。但是,大家可能很难想象神秘的黑客在挖掘漏洞的时候会提前编写测试用例,然后按照用例去执行。因为他的漏洞挖掘思路是存在脑海中,并且不断的根据实际情况进行调整的。 当然,关于黑客单打独斗挖掘漏洞的这种想象,显然已不大符合当前安全界的实际情况。从网络及信息安全的攻击角度来说,恶意攻击分子已经逐渐形成了目标精准、分工明确、技术先进的网络黑色产业链条,相应的从安全保护和防御角度来说,国家加大了对网络攻击等犯罪行为的打击力度,企业也逐渐加大了网络安全投入。 那么,当安全测试成为企业安全建设中的一个重要环节,安全测试...
-
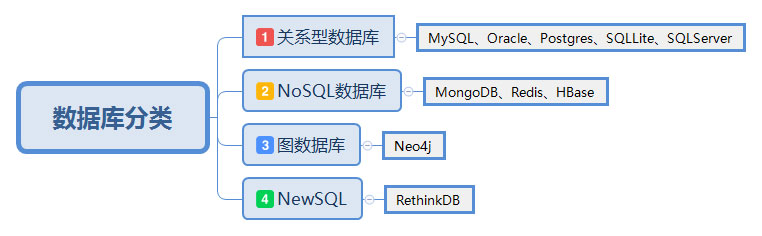
- 软件测试之MySQL数据库必知必会,面试必备!02-18一、前言1.1 数据库概念及分类首先,我们经常说的MySQL是一个数据库管理系统,而非数据库。数据库是组织、存储和管理数据的仓库,存储数据的容器。 而数据库管理系统是操纵和管理数据库的大型软件,建立、使用和维护数据库。 数据表是真正的数据存储单元,其他对象的基础。 三者之间的关系为:一个数据库管理系统维护了多个数据库,一个数据库包含若干数据表。关于数据库的分类,可能有很多种分类。一般来说,我们用到最多的就是关系型数据库和NoSQL数据库。 而其中关系型数据库又是应用最为广泛的。1.2 SQL语句概念及分类SQL:一种结构化查询语句,用于访问和操作数据库的标准计算机语言。 通常用途为操作数据库对...



{kind=link}
{kind=link}
{kind=link}
{kind=link}
- 关于我们 联系我们 版权声明 广告服务 站长统计
- 建议使用IE 11.0以上浏览器,800×600以上分辨率,法律顾问:上海兰迪律师事务所 项棋律师
- 版权所有 上海博为峰软件技术股份有限公司 Copyright©51testing.com 2003-2024, 沪ICP备05003035号
- 投诉及意见反馈:webmaster@51testing.com; 业务联系:service@51testing.com021-64471599-8017

- 51testing软件测试圈微信