 1
1 1
1


- 快手测试开发岗面试题——软件测试圈
代码题:
**旋转数组:这个在美团一面的时候也遇到过**
假设按照升序排序的数组在预先未知的某个点上进行了旋转。
( 例如,数组 [0,1,2,4,5,6,7] 可能变为 [4,5,6,7,0,1,2] )。请找出其中最小的元素。注意数组中可能存在重复的元素。
int findMin(vector<int>& nums) {
int left = 0, right = nums.size()-1, mid = 0;
while(left < right){
mid = (left + right) >> 1;
if(nums[mid] > nums[right])
left = mid + 1;
else if(nums[mid] < nums[left])
right = mid;
//处理当反转点位于连续重复数字之间时的情况
else
right -= 1;
}
return nums[left];
}假设数组中不存在重复元素
def findMin(self, nums): target = nums[0] n = len(nums) if n == 1: return target for i in range(1,n): if nums[i] < target: return nums[i] return target
python装饰器
本质是函数,用来装饰其他函数,为其他函数添加附加功能
@语法只是将函数传入装饰器函数
装饰器允许传入参数
函数就是变量;
高阶函数;
把一个函数当作实参传给另外一个函数,在不修改被装饰函数源代码情况下为其添加功能;
返回值中包含函数名, 不修改函数的调用方式。
嵌套函数。
高阶函数+嵌套函数==》装饰器。
python多线程
多线程与多进程的区别
多线程可以共享全局变量,多进程不能;
多线程中,所有子线程的进程号相同,多进程中,不同的子进程进程号不同;
线程共享内存空间;进程的内存是独立的;
同一个进程的线程之间可以直接交流;两个进程想通信,必须通过一个中间代理来实现;
创建新线程很简单; 创建新进程需要对其父进程进行一次克隆;
一个线程可以控制和操作同一进程里的其他线程;但是进程只能操作子进程。
多线程的优点
多线程技术使程序的响应速度更快 ,因为用户界面可以在进行其它工作的同时一直处于活动状态;
当前没有进行处理的任务时可以将处理器时间让给其它任务;
占用大量处理时间的任务可以定期将处理器时间让给其它任务;
可以随时停止任务;
可以分别设置各个任务的优先级以优化性能。
多线程缺点
如果有大量的线程,会影响性能,因为操作系统需要在它们之间切换;
更多的线程需要更多的内存空间;
线程中止需要考虑对程序运行的影响;
通常块模型数据是在多个线程间共享的,需要防止线程死锁情况的发生。
什么时候用多进程什么时候用多线程
需要频繁创建销毁的优先用线程
需要进行大量计算的优先使用线程:大量计算,当然就是要耗费很多CPU,切换频繁了,这种情况下线程是最合适的。这种原则最常见的是图像处理、算法处理
可能要扩展到多机分布的用进程,多核分布的用线程
用到多线程的主要是需要处理大量的IO操作时或处理的情况需要花大量的时间等等,比如:读写文件、视频图像的采集、处理、显示、保存等;具体的
耗时或大量占用处理器的任务阻塞用户界面操作;
各个任务必须等待外部资源 (如远程文件或 Internet连接)。
Kmeans的过程
问这个算法估计是因为我的项目中提到了
主要思想
先随意给定初始的类别中心,然后做聚类,通过迭代,不断调整这些类别中心,直到得到最好的聚类中心为止。
其算法步骤如下:
从集合(x1, x2, …, xn)中随机取k个元素,作为k个类别的各自的中心;
聚类。分别计算集合中每一个元素到k个类别中心的距离,将这些元素分别划归到距离最小的那一个类别中去,这个过程其实是一个重新聚类的过程;
更新类别中心。根据前面聚类的结果,重新计算每一个类别的中心,计算方法是取当前类别中所有元素,然后计算这些元素在每一个维度的平均值。每一个类别中心都重新计算一遍后,就得到了一个新的类别中心组 ;
重复第2,3步,直到聚类结果不再发生变化,这样得到的类别中心,基本上就是我们最后想要找的类别中心。
优缺点
优点:简单,容易理解,运算速度快
缺点:
只能应用于连续型的数据,并且一定要在聚类前需要手工指定要分成几类。
K-Means的初始类别中心是随机选择的,初始类别中心对整个分类结果和计算时间有很大的影响。初始类别中心不好,可能会使算法陷入局部最小值,得到一个次优的分类结果,而得不到全局最优解,另外,初始类别中心不好,也会增加迭代的次数,从而增加分类所用的时间。
对孤立点敏感。如果总体样本集合中存在噪声点,或者孤立点,那么,它必然会影响到最后的结果合理的确定K值和K个初始类簇中心点对于聚类效果的好坏有很大的影响。
如何选择初始类簇中心点 选择批次距离尽可能远的K个点 首先随机选择一个点作为第一个初始类簇中心点,然后选择距离该点最远的那个点作为第二个初始 类簇中心点,然后再选择距离前两个点的最近距离最大的点作为第三个初始类簇的中心点,以此类推,直至选出K个初始类簇中心点
K值确定
法1:(轮廓系数)在实际应用中,由于Kmean一般作为数据预处理,或者用于辅助分聚类贴标签。所以k一般不会设置很大。可以通过枚举,令k从2到一个固定值如10,在每个k值上重复运行数次kmeans(避免局部最优解),并计算当前k的平均轮廓系数,最后选取轮廓系数最大的值对应的k作为最终的集群数目。
pytorch
这个也是因为项目中用过所以才问的
什么是Pytorch,为什么选择Pytroch?
一个基于Python的科学计算包, 设计目的有两点:
numpy在GPUs实现上的替代品
具有高度灵活性和速度的深度学习研究平台
PyTorch 是一个建立在 Torch 库之上的 Python 包,旨在加速深度学习应用。
PyTorch 提供一种类似 NumPy 的抽象方法来表征张量(或多维数组),它可以利用 GPU 来加速训练
PyTorch - 张量
张量是多维数组。类似于numpy的ndarrays,另外,张量也可以在GPU上使用。PyTorch支持各种类型的张量。
import torch
python第三方的库有哪些
这个在百度面试中也遇到过
NumPy、
matplotlib(绘制数据图的库)、
Scapy(Scapy是一个Python程序,使用户能够发送,嗅探和剖析并伪造网络数据包。此功能允许构建可以探测,扫描或攻击网络的工具)、
scrapy(爬虫的库)
神经网络中的dropout
指在深度学习网络的训练过程中,对于神经网络单元,按照一定的概率将其暂时从网络中丢弃。注意是暂时,对于随机梯度下降来说, 由于是随机丢弃,故而每一个mini-batch都在训练不同的网络
作者:葳蕤_wish
原文链接:https://blog.csdn.net/weixin_37846736/article/details/106351684
- 0.00 查看剩余0%
- 【留下美好印记】赞赏支持

热门文章
最新讲堂
- 推荐阅读
- 换一换
- 测试课程免费送,点击下方链接填写测试行业调查问卷,提交后即刻获得!链接:http://vote.51testing.com/ 软件测试行业供需现状 随着敏捷、DevOps等开发模式的引入以及大数据治理与应用、人工智能机器学习与深度学习的应用的发展、软件交付周期逐渐缩短、技术复杂度不断提升对测试人员质量保障与效率提升等方面提出了越来越高的要求。因此,对人员的要求也是在不断提高的,一方面响应基础功能需求的手工测试人员基本饱和,另一方面懂测试的测试开发面试达标者比例过低。 软件测试行业的发展现状 通过之前对近几年《软件测试行业现状报告》的解读,以及结合对当下软件测试左移与右移思考,总结了...
-
- T-Box功能自动化测试方案——软件测试圈03-03背景T-Box是实现汽车车联网的一个关键环节,从起初单纯的实现车辆信息采集,已发展到具有车辆信息监测及信息交互(V2X)、车辆远程控制、安全监测和报警、远程诊断、边缘计算等多种离线和在线的应用功能的载体。为保障T-Box功能的正常运转,对其进行功能测试就尤为重要。T-Box作为“边缘节点”,与车内控制器通过传统总线或车载以太网进行信息交互,与车外TSP(Telematics Service Platform)通过蜂窝基站无线技术进行信息交互。从测试实现的角度,针对T-Box功能测试而言,由于自动化测试所需的“Input仿真”与“Output监测”的闭环存在一定难度,故基本通过手动或半自动化的传...

- Appnium--APP自动化测试工具08-04读者提问:APP 自动化测试工具有推荐的吗 ?阿常回答:有,Appium。官网地址:https://appium.ioGithub地址:https://github.com/appium/appium (开源社区)阿常碎碎念:Appium 是一个开源的、跨平台的自动化测试工具,可用于 APP 的自动化测试。Appium 支持 iOS 、Android 及 Firefox OS 平台。Appium 使用 WebDriver 的 json wire 协议,来驱动 iOS 系统的 UIAutomation 库、Android 系统的 UIAutomator 框架。它允许测试人员在...
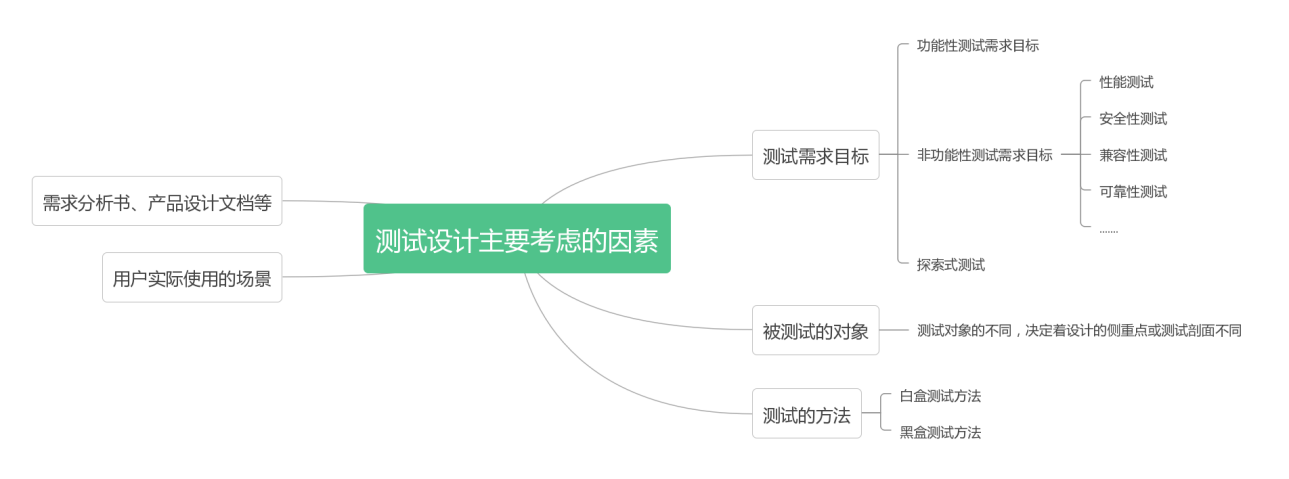
- 一、正确认识测试设计 测试设计是从特定的测试依据中得到用例,用于实现特定测试覆盖的方法。上面中的测试依据指的是有关测试的信息,比如项目背景、业务需求、领域知识、团队、进度、预算、风险等等,这些因素在经过测试分析后就是特定的测试依据,它们影响着测试设计与执行。测试设计是测试整个过程的总纲,通常是测试人员的测试思路的体现。在测试界中,有着测试设计是测试的灵魂,也是测试人员的必修课之说。 二、测试设计的原则及要考虑的因素 在测试过程中,测试人员不可能穷举所有的测试场景或组合,因此在设计测试用例时,要学会抓住测试的要点或关键点,做合理的取舍,这些要点或关键点需要进行充分分析与设计,以达到理想...
-
- 【原创】我推荐的简历格式08-13自从写了几篇简历相关的文章,不少同学都找我帮忙修改简历。大部分同学发给我之前都看过系列文章,需要修改的地方就很少了,但是也有没看完所有文章就直接丢给我简历的,建议把之前写过的都看看哈。今天我按照简历从上到下的顺序,逐一提供推荐的格式,并简单说明下原因,希望大家能保持频调一致,理解简历的真正目的。一、个人信息简历开头是个人信息,这个大家都没有异议的吧?但是个人信息应该包含哪些内容,每个人理解都不一样,我的建议是:1、要包含:姓名、性别、学历、工作年限、电话、邮箱地址;2、不包含:照片(对自己特自信的除外)、毕业学校(特知名的除外)、专业(特自豪的除外);原因:咱们是技术岗,一切以技术优先;学校和...



{kind=link}
、车辆远程控制、安全监测和报警、远程诊断、边缘计算等多种离线和在线的应用功能的载体。为保障T-Box功能的正常运转,对其进行功能测试就尤为重要。T-Box作为“边缘节点”,与车内控制器通过传统总线或车载以太网进行信息交互,与车外TSP(Telematics Service Platform)通过蜂窝基站无线技术进行信息交互。从测试实现的角度,针对T-Box功能测试而言,由于自动化测试所需的“Input仿真”与“Output监测”的闭环存在一定难度,故基本通过手动或半自动化的传...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=116873&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=116873&pic=http://quan.51testing.com/ueditor/php/upload/image/20210303/1614735173708448.png){kind=link}
{kind=link}
- 关于我们 联系我们 版权声明 广告服务 站长统计
- 建议使用IE 11.0以上浏览器,800×600以上分辨率,法律顾问:上海兰迪律师事务所 项棋律师
- 版权所有 上海博为峰软件技术股份有限公司 Copyright©51testing.com 2003-2024, 沪ICP备05003035号
- 投诉及意见反馈:webmaster@51testing.com; 业务联系:service@51testing.com021-64471599-8017

- 51testing软件测试圈微信