 1
1 3
3


- 【原创】Python2 和 Python3 中默认编码的差异
最近在使用 Python3.4 做一些脚本实现,发现对于编码的处理上和 Python2.6 有很大的不同,就此机会把相关知识做个梳理,方便需要的时候查阅。
先说下概念和差异:
脚本字符编码:就是解释器解释脚本文件时使用的编码格式,可以通过
# -\*- coding: utf-8 -\*-显式指定
解释器字符编码:解释器内部逻辑过程中对 str 类型进行处理时使用的编码格式
Python2 中默认把脚步文件使用 ASCII 来处理(历史原因请 Google)
Python2 中字符串除了 str 还有 Unicode,可以用 decode 和 encode 相互转换
Python3 中默认把脚步文件使用 UTF-8 来处理(终于默认就支持中文了,赞)
Python3 中文本字符和二进制分别使用 str 和 bytes 进行区分,也是使用 decode 和 encode 进行相互转换
关于默认脚本字符编码,因为对脚步文件处理的默认编码格式变了,所以很多针对内容的处理,都发生了变化,比如下面这个脚本。
import sys
print(sys.getdefaultencoding())
print('中文')
使用 Python3.4 解释器运行结果如下:
> python34 test.py
utf-8
中文
使用 Python2.6 解释器运行结果如下:
> python26 test.py
File "test.py", line 4
SyntaxError: Non-ASCII character '\xe4' in file test.py on line 4, but no encoding declared; see http://www.python.org/peps/pep-0263.html for details
使用 Python2.6 报错就是因为第一条说的「Python2 中默认把脚步文件使用 ASCII 来处理」,但是脚步文件包含了中文,ascii 又没有覆盖中文,所以报错。如果我们把脚步稍作修改:
# -*- coding: utf-8 -*-
import sys
print(sys.getdefaultencoding())
print('中文')
增加了脚本字符编码的说明,再次使用 Python2.6 解释器运行结果为:
> python26 test.py
ascii
涓枃
因为明确指定了脚步文件编码格式为 utf-8,所以读取没问题,也就是说如果 Python2 脚本文件中包含了非 ASCII 字符时,一定要显式指定脚步文件编码格式,对于 Python3 因为默认的脚步文件编码格式就是 utf-8,所以没有这个问题(后面会有文章详细讨论这个问题)。
但是我们回头看下刚才的输出,结果显示为乱码。
乱码就涉及到另一个我们要说的不同点解释器字符编码,因为我们定义了 utf-8 格式读取脚步内容,但是因为 Python2.6 在 Windows 平台上,默认是使用 gbk 对字符进行 decode 输出,不信你看:
> python26
ActivePython 2.6.6.15 (ActiveState Software Inc.) based on
Python 2.6.6 (r266:84292, Aug 24 2010, 16:01:11) [MSC v.1500 32 bit (Intel)] on
win32
Type "help", "copyright", "credits" or "license" for more information.
>>> s='中文'
>>> s
'\xd6\xd0\xce\xc4'
>>> s.decode('gbk').encode('utf-8')
'\xe4\xb8\xad\xe6\x96\x87'
>>> print('\xd6\xd0\xce\xc4')
中文
>>> print('\xe4\xb8\xad\xe6\x96\x87')
涓枃
完整描述下上面乱码出现的过程:
使用指定的脚本文件编码 utf-8 格式读取了「中文」,读取到的字符串内容为 ‘\xe4\xb8\xad\xe6\x96\x87’,然后输出时 Python2.6 的解释器使用默认解释器字符编码 gbk 格式对读取内容进行 encode 输出,但是之前 utf-8 是 3 个字节长度表示一个中文,而 gbk 是用 2 个字节长度来表示中文,所以之前的 2 个中文,在输出的时候就按照 3 个中文进行编码(encode),当然就乱码了,仔细看那个乱码,就是 3 个字。
我们再用代码验证下上面说的内容:
# -*- coding: utf-8 -*-
import sys
print(sys.getdefaultencoding())
print('中文')
print('\xe4\xb8\xad\xe6\x96\x87')
print('\xe4\xb8\xad\xe6\x96\x87'.decode('gbk', 'ignore'))
print('\xd6\xd0\xce\xc4'.decode('gbk').encode('utf-8'))
print('中文'.decode('utf-8'))
print('\xe4\xb8\xad\xe6\x96\x87'.decode('utf-8'))
print('\xd6\xd0\xce\xc4')
print('\xd6\xd0\xce\xc4'.decode('gbk'))
看看输出结果:
> python26 test.py
ascii
涓枃
涓枃
涓枃
涓枃
中文
中文
中文
中文
很明显 gbk 格式解码的十六进制字符正常输出为中文了,显式使用 utf-8 对 utf-8 格式的十六进制字符进行 decode 也输出正常了。
同理,还可以看到另外 2 个现象:
把 py 文件用 utf-8 格式存储,并且包含「中文」字样时,如果使用 gbk 格式打开,也是看到「中文」显示的乱码和上面程序输出的一致;
如果把 py 文件使用 gbk 格式存储,这时候print('中文')也显示正常了;
乱码的终极原因就是:对同一个字符串的 encode 和 decode 编码格式不一致。
上面说的这个问题,如果文件存储和脚本文件编码都使用 utf-8 时,使用 Python3.4 是没有问题的,因为 Python3 默认的解释器字符编码是 utf-8 了,默认就可以处理中文了。
总结下结论:
- Python2 脚步文件尽量使用 gbk 格式存储;同理 Python3 脚步文件尽量使用 utf-8 格式存储;
- Python2 脚步如果带有中文字符时,请务必在脚本开头声明能支持中文的脚本文件编码;
- Python2 中对同一个字符串的 encode 和 decode 编码格式请保持一致;
说明:本次所有测试脚本文件均保存为 utf-8 格式
本文首发于公众号「sylan215」,十年测试老兵的原创干货,关注我,涨姿势!
- 0.00 查看剩余0%
- 【留下美好印记】赞赏支持

热门文章
最新讲堂
- 推荐阅读
- 换一换
- 1、大数据入库测试背景 在大数据时代,数据已经成为企业的重要资产。为了确保数据的准确性和可靠性,数据入库测试成为了不可或缺的一环。大数据入库测试是在确保数据质量得前提下进行的,它包括了对数据的验证、处理以及存储的一系列检查工作。本文主要聚焦源系统测试部门收到开发人员提供的数据文件后,进行数据一致性测试过程中的简化操作。这里的数据一致性是指上传到大数据平台中的数据与从外部写入前的数据保持一致,即写入数据与读出数据始终是一致的。数据一致性能够表明大数据平台可保证数据的完整性,不会导致数据丢失或数据错误。 2、大数据平台入库测试重点 在大数据平台入库测试中,测试人员收到开发人员给的数据之后...
-
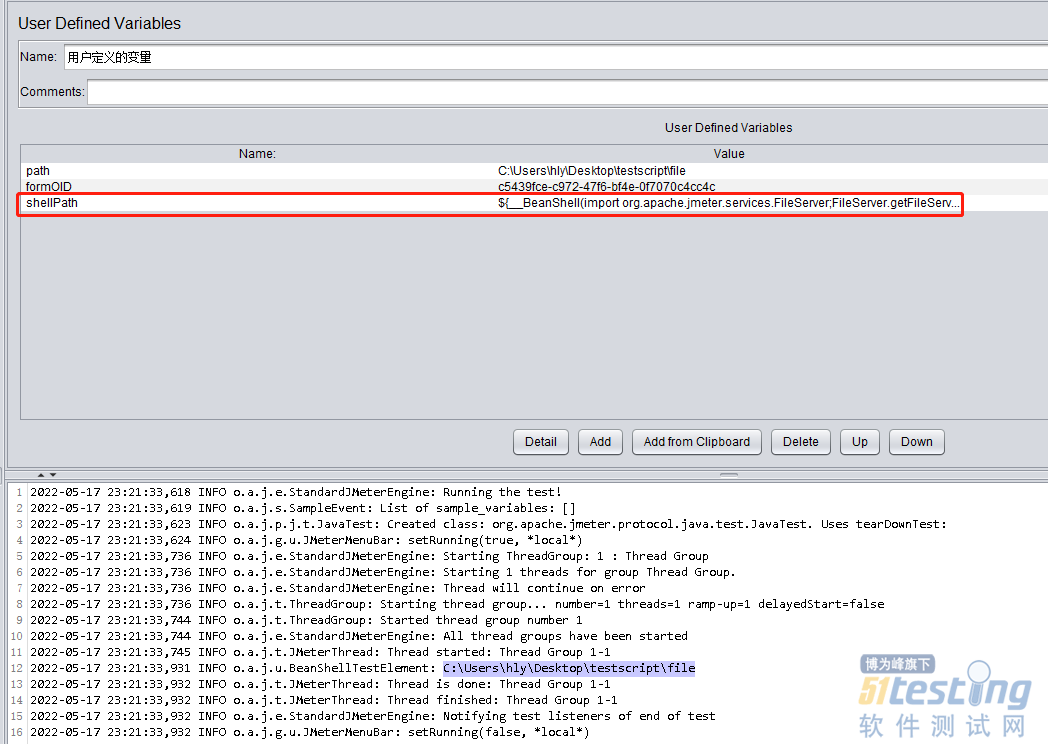
- 平时学习、工作过程中,编写的一些JMeter脚本,相信大多数都遇到过这个问题。那就是:如果换一台电脑运行,文件路径不一样,会导致运行失败。 前不久,自己就真真切切遇到过一回,A同学写了个脚本用于压测,需要其他测试同学协助下,结果部分人员没有提前调试代码,导致运行的时候报错。 主要的原因就是,A同学写的脚本不能通用,以自己本机的路径来编写的,而其他同学的文件路径不一样,导致报错。 后面我实在看不下去了,把脚本改动了下,压测顺利结束。那么这个问题是否有解决的办法呢,自然是有的,而且很简单,我们来看详细。 获取文件目录 用户定义变量 我们先来看第一种方式,直接使用beanshell函...
-
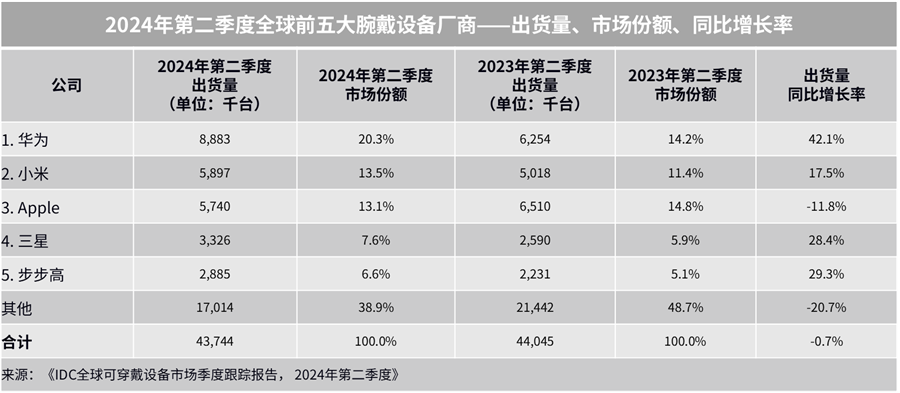
- 根据国际数据公司(IDC)最新发布的《全球可穿戴设备市场季度跟踪报告》,2024 年第二季度全球腕戴设备市场出货 4,374 万台,同比下滑 0.7%;中国腕戴设备市场出货量为 1,555 万台,同比增长 10.9%,发展速度明显超过全球市场。 · 腕戴设备市场包含智能手表和手环产品。其中: · 智能手表市场 2024 年第二季度全球出货量 3,475 万台,同比下降 3.2%;而中国智能手表市场出货量 1,114 万台,同比增长 18.7%。 手环市场 2024 年第二季度全球出货量 899 万台,同比增长 10.6%;中国手环市场出货量 441 万台,同比下降 4.8%...
-
- 数据管理的基本准则——软件测试圈07-04什么是数据管理? 女士们,先生们,欢迎来到数据管理的世界——数字球美女,商业机器背后的驱动力。简而言之,数据管理是收集、保护和利用数据的做法,这些策略安全、高效且具有成本效益。想象一下,有一个数字图书管理员,但不是严厉的喝斥,而是让你毫不费力地访问数据。无论你的组织规模如何,这个魔法都会创造奇迹。 数据管理的组成部分 数据管理不单单是几个字符,它是一个由多个组件组成的合奏,演奏着一首美丽的交响乐。首先,我们有数据管理指挥家设定节奏,定义规则,并确保数据管理工作在法律允许范围内。接下来是数据质量,这是一个精致的女高音,确保数据是准确的,有关联的,最重要的是可用的。 接着是数据整合,我...
- 软件测试的类型-其他类型的测试(2)08-01浏览器兼容性测试这是兼容性测试的子类型(如下所述),由测试团队执行。浏览器兼容性测试 针对 Web 应用程序执行,并确保软件可以在不同浏览器和操作系统的组合下运行。这种类型的测试还验证 Web 应用程序是否在所有浏览器的所有版本上运行。向后兼容性测试这是一种测试,用于验证新开发的软件或更新的软件是否适用于旧版本的环境。向后兼容性测试检查新版本的软件是否与旧版本软件创建的文件格式正常工作。它还适用于由该软件的旧版本创建的数据表、数据文件和数据结构。如果更新了任何软件,那么它应该可以在该软件的先前版本之上运行良好。黑盒测试此类测试不考虑内部系统设计。测试基于需求和功能。可以在此处找到有关...




{kind=link}
{kind=link}
最新发布的《全球可穿戴设备市场季度跟踪报告》,2024 年第二季度全球腕戴设备市场出货 4,374 万台,同比下滑 0.7%;中国腕戴设备市场出货量为 1,555 万台,同比增长 10.9%,发展速度明显超过全球市场。 · 腕戴设备市场包含智能手表和手环产品。其中: · 智能手表市场 2024 年第二季度全球出货量 3,475 万台,同比下降 3.2%;而中国智能手表市场出货量 1,114 万台,同比增长 18.7%。 手环市场 2024 年第二季度全球出货量 899 万台,同比增长 10.6%;中国手环市场出货量 441 万台,同比下降 4.8%...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=147208&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=147208&pic=http://quan.51testing.com/ueditor/php/upload/image/20240905/1725503000651453.png){kind=link}
- 关于我们 联系我们 版权声明 广告服务 站长统计
- 建议使用IE 11.0以上浏览器,800×600以上分辨率,法律顾问:上海兰迪律师事务所 项棋律师
- 版权所有 上海博为峰软件技术股份有限公司 Copyright©51testing.com 2003-2024, 沪ICP备05003035号
- 投诉及意见反馈:webmaster@51testing.com; 业务联系:service@51testing.com021-64471599-8017

- 51testing软件测试圈微信