 13
13 15
15


- python UI自动化测试常见面试题——软件测试圈
一、Selenium2+python自动化36-判断元素存在
1、捕获异常
from selenium import webdriver import unittest class Test1(unittest.TestCase): #一、准备浏览器驱动、网站地址 #setUp在每个测试函数运行前运行,注意大小写;self不能省略 def setUp(self): self.driver=webdriver.Chrome() self.baseurl="https://www.baidu.com" #二、打开浏览器,发送请求 函数名必须以test开头 def test_01(self): browser=self.driver browser.get(self.baseurl) #四、调用方法,判断元素是否存在 flag=Test1.isElementExist(self,“input”) if flag: print(“该元素存在”) else: print(“该元素不存在”) #三、判断元素是否存在的方法 def isElementExist(self): flag=True browser=self.driver try: browser.find_element_by_css_selector(element) return flag except: flag=False return flag #五、运行所有以test开头的测试方法 if __name__=="__main__": unittest.main()
第二种:find_elements方法
#除第三步,其他步骤同上 def isElementExist(self): flag=True browser=self.driver ele=browser.find_elements_by_css_selector(element) iflen(ele)==0: flag=False return flag if len(ele)==1: return flag else: flag=False return flag
二、elenium中hidden或者是display = none的元素是否可以定位到?
答:能定位到,只是不能操作,想点击的话,可以用js去掉dispalay=none的属性
如果面试官想问的是定位后操作隐藏元素的话,本质上说这个问题就是毫无意义的,web自动化的目的是模拟人的正常行为去操作。
如果一个元素页面上都看不到了,你人工也是无法操作的是不是?人工都不能操作,那你自动化的意义又在哪呢?所以这个只是为了单纯的考察面试者处理问题的能力,没啥实用性!(面试造飞机,进去拧螺丝)
既然面试官这么问了,那就想办法回答上给个好印象吧!
首先selenium是无法操作隐藏元素的(但是能正常定位到),本身这个框架就是设计如此,如果非要去操作隐藏元素,那就用js的方法去操作,selenium提供了一个入口可以执行js脚本。
js和selenium不同,只有页面上有的元素(在dom里面的),都能正常的操作,接下来用js试试吧!
<a hidden id="baidu" href="https://www.baidu.com">访问百度</a> 这个链接是隐藏的,但是能用js点到
from selenium import webdriver
driver = webdriver.Firefox()
driver.get("http://localhost:63342/test1122/a/b.html")
# js点击hidden元素
js = 'document.getElementById("baidu").click()'
driver.execute_script(js)三、selenium中如何保证操作元素的成功率?也就是说如何保证我点击的元素一定是可以点击的?
首先通过封装find方法,实现wait_for_element_ispresent(WebDriverWait)
在对页面进行click之前,先滚动到该元素(通过Js封装),避免在页面未加载完成前或是在下拉之后才能显示。
不同方式进行定位,与expected_conditions判断方法封装,循环判断页面元素出现后再操作;
开发人员规范开发习惯,如给页面元素加上唯一的name,id等。
四、如何提高selenium脚本的执行速度?
优化测试用例。设置等待时间的时候,少用sleep,尽量不用implicitly_wait,多用显式等待方法;
减少不必要的操作步骤。如经过三四步才能打开要测试的页面的话,可以直接通过网址来打开;
中断页面加载。如果加载的内容不影响我们测试,就设置超时时间,中断页面加载;
使用Selenium grid,通过testNG实现并发执行。 在编写测试用例的时候,实现松耦合,然后再服务器允许的情况下,尽量设置多线程实现并发运行。
五、用例在运行过程中经常会出现不稳定的情况,也就是说这次可以通过,下次就没办法通过了,如何去提升用例的稳定性?
在经常检测失败的元素前尽量加上显式等待时间,等要操作的元素出现之后再执行下面的操作;
多线程的时候,减少测试用例耦合度,因为多线程的执行顺序是不受控制的;
多用 try 捕捉,处理异常;
尽量使用测试专用环境,避免其他类型的测试同时进行,对数据造成干扰。
六、如何设计高质量自动化脚本
使用四层结构实现业务逻辑、脚本、数据分离。
使用PO设计模式,将一个页面用到的元素和操作步骤封装在一个页面类中。如果一个元素定位发生了改变,我们只用修改这个页面的元素属性
对于页面类的方法,我们尽量从客户的正向逻辑去分析,方法中是一个独立场景,例如:登录到退出,而且不要想着把所有的步骤都封装在一个方法中。
测试用例设计中,减少测试用例之间的耦合度。
七、你的自动化用例的执行策略是什么?
自动化测试用例是用来监控的。集成到jenkins,创建定时任务定时执行;
有些用例在产品上线前必须回归。jenkins上将任务绑定到开发的build任务上,触发执行;
有些用例不需要经常执行。jenkins创建一个任务,需要执行的时候人工构建即可。
八、什么是持续集成
频繁的将代码集成到主干,持续性的进行项目的构架,以便能能够快速发现错误,防止分支大幅度偏离主干
九、自动化测试的时候是不是需要连接数据库做数据校验?
UI自动化不需要
接口测试会需要
十、Selenium有几种定位方式?你最偏爱哪一种,为什么?
与name有关的有三种:name、class_name、tag_name
与link相关的有两种:link_text、partitial_link_text
与id有关:id
全能选手:xpath、css_selector
如果存在id,我一定使用Id,因为简单方便,定位最快。其次是Xpath,因为很多情况下html标签的属性不够规范,无法唯一定位。Xpath是通过相对位置定位
如果没有,那么CSS定位器应该被优先考虑,因为在大多数现代浏览器中,它们的评估速度比XPath更快。
十一、如何去定位页面上动态加载的元素?
首先触发动态事件,然后再定位。如果是动态菜单,则需要层级定位。——JS实现(对动态事件封装)
十二、如何去定位属性动态变化的元素?
先去找该元素不变的属性,要是都变,那就找不变的父元素,用层级定位(以不变应万变)
属性动态变化也就是指该元素没有固定的属性值,可以通过:
JS实现,
通过相对位置来定位,比如xpath的轴,paren/following-sibling/percent-sibling
http://www.cnblogs.com/zhaozhan/archive/2009/09/10/1564332.html
点击链接以后,selenium是否会自动等待该页面加载完毕?
不会的。所以有的时候,当selenium并未加载完一个页面时再请求页面资源,则会误报不存在此元素。所以首先我们应该考虑判断,selenium是否加载完此页面。其次再通过函数查找该元素。
十三、webdriver client的原理是什么?
在selenium启动以后,driver充当了服务器的角色,跟client和浏览器通信,client根据webdriver协议发送请求给driver。driver解析请求,并在浏览器上执行相应的操作,并把执行结果返回给client.
webdriver的协议是什么?
WebDrive协议本身是http协议,数据传输使用json
启动浏览器的时候用到的是哪个webdriver协议?
-http
十四、什么是page object设计模式?
通俗来讲,把每个页面当成一个页面对象,页面层写定位元素方法和页面操作方法;
用例层从页面层调用操作方法,写成用例;
可以做到定位元素与脚本的分离。
page object设置模式中,是否需要在page里定位的方法中加上断言?
不需要,page页只做元素抓取和操作方法
page object设计模式中,如何实现页面的跳转?
初始化driver参数,Page类传driver参数
十五、怎样去选择一个下拉框中的value=xx的option?
select类里面提供的方法:select_by_value(“xxx”)
xpath的语法也可以定位到
十六、什么是断言和验证?
断言(assert):测试将会在检查失败时停止,并不运行后续的检查
优点:可以直截了当的看到检查是否通过
缺点:检查失败后,后续检查不会执行,无法收集那些检查结果状态
验证(vertify):将不会终止测试
缺点:你必须做更多的工作来检查测试结果:查看日志——>耗时多,所以更偏向于断言
十七、你觉得自动化测试最大的缺陷是什么?
不稳定
-可靠性不强
-不易维护
-成本与收益
十八、什么是分层测试?
数据层;
接口层;
UI层。
十九、webdriver可以用来做接口测试吗?
不可以,webdriver是专门做web的UI自动化参数
二十、get和post 的区别?
GET请求:请求的数据会附加在URL之后,以?分割URL和传输数据,多个参数用&连接。
POST请求:POST请求会把请求的数据放置在HTTP请求包的包体中。
传输数据的大小
使用GET请求时,传输数据会受到URL长度的限制。
对于POST,理论上是不会受限制的
安全性。POST的安全性比GET的高
二十一、三种等待
强制等待
time.sleep(10):如果设置10秒,即使页面已经加载出来了,也不执行操作,必须够10秒才能执行下面的操作
隐形等待
driver.implicitly_wait(30):设置最长的等待时间,在这个时间内加载完成,则执行下一步操作,整个driver的会话期内,设置一次即可,全局可用,应用度上不灵活
显性等待
明确等到某个条件满足后,再去执行下一步操作,程序每隔xx秒看一眼,如果条件成立了,则执行下一步,否则继续等待,直到超过设置最长时间,然后抛出TimeoutException
WebDriverWait()类,显性等待类,
用法:WebDriverWait(driver,等待时间,轮询周期).until()/until_not(判断条件)
先确定元素的定位表达式;
调用WebDriverWait()类设置等待总时长,轮询周期,并调用until()、until_not()方法;
WebDriverWait(driver,等待时间,轮询周期).until()/until_not(判断条件);
使用ecpected_conditions对应的方法来生成判断条件。
EC.类名(定位方式,定位表达式)
例:等待百度登陆的弹框出现,再去操作弹出框
#显性等待需要引入三个库
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://www.baidu.com/')
driver.maximize_window()
driver.find_element_by_xpath('//div[@id="u1"]//a[@name="tj_login"]').click()
id="TANGRAM__PSP_11__footerULoginBtn"
#显性等待判断
WebDriverWait(driver,10).until(EC.visibility_of_element_located((By.ID,id)))
driver.find_element_by_id('TANGRAM__PSP_11__footerULoginBtn').click()
driver.quit()二十二、三种切换操作
作者:萌萌哒小宝宝
原文链接:https://blog.csdn.net/qq_38889350/article/details/114677430
- 0.00 查看剩余0%
- 【留下美好印记】赞赏支持

热门文章
最新讲堂
- 推荐阅读
- 换一换
- 手工测试小白也能做的UI自动化(Python版)03-11手动测试做久了,总会想要尝试接触些新技术,UI自动化就是一个非常容易尝试的入门砖。小白也能做,相信自己放手去试吧。一、为什么需要做UI自动化1.想一想,为什么需要做UI自动化可以从解决问题的角度出发,想一下在工作中,哪些工作重复性非常高?最最常见的重复性工作,那就是:功能回归测试啦。现在市面上的大小公司都在推敏捷开发,几乎都是2周/3周发一次版本。即2周/3周跑一次回归测试,而且Android和iOS都需要跑一次,即便分在个人头上的回归内容很少,其实也占据了大家大量时间。当然,并不是说UI自动化只能在回归测试阶段发光发热,在测试的任何阶段都可以尝试跑UI测试脚本,可以根据公司需要调整运行阶段、...
- IT之家12月9日消息,美国联邦贸易委员会(FTC)周四起诉科技巨头微软,要求其停止对动视暴雪750亿美元的收购,指称这项交易可能会损害高性能游戏机和订阅服务的竞争。 据《华尔街日报》报道,动视暴雪首席执行官BobbyKotick表示,微软收购该游戏开发商的交易将继续进行,尽管FTC计划阻止这项交易。Kotick认为FTC的指控与事实不符,相信微软会赢得这场挑战。 IT之家了解到,这将是微软公司历史上规模最大的一笔收购交易,同时也是视频游戏行业最大的一笔交易。FTC反垄断局局长霍利·维多瓦(HollyVedova)在新闻稿中表示:“微软已经证明,其有能力、有意愿停止向游戏行业的竞争对手...

-
- Cypress 小试牛刀-测试用例(三)08-12前面 2 篇我们知道了如何安装、进行页面元素交互,现在我们开始编写一个测试用例Cypress 提供了基于 Mocha 的语法,基本功能模块describe() 声明一个测试用例集,可包含多个 it()测试用例,也可以在嵌套测试套件 context()it() 声明一个测试用例,一个测试用例集至少有一个测试用例before() 在一个测试用例集中,只执行一次,在所有测试用例之前执行beforeEach() 在一个测试用例集中,每个测试用例前执行一次afterEach() 在一个测试用例集中,每个测试用例后执行一次after() 在一个测试用例集中,只执行一次,在所有测试用例之后执行上述 4 个方...
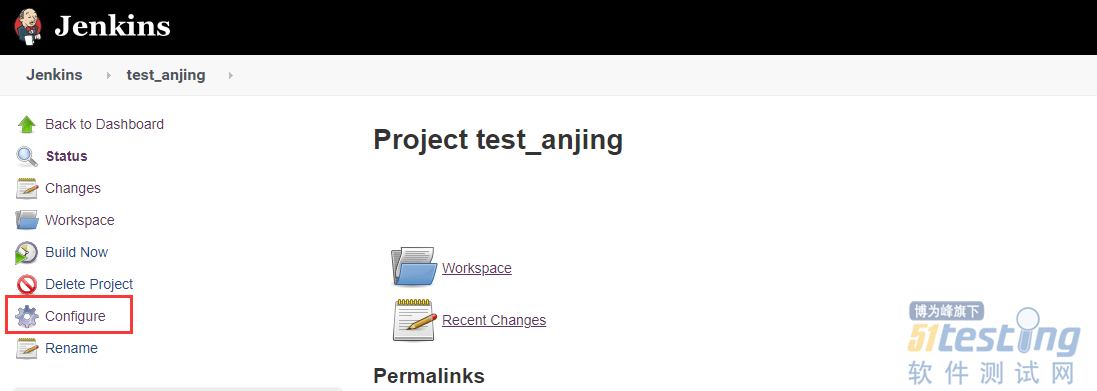
- 前言 我们在做自动化时,当自动化测试用例编写完成后,都会想着将其自动执行程序,或者说通过定时的形式进行执行我们的自动化测试程序,这样才能真正意义上实现自动化测试。哪么大家知道都有哪些方法可以帮助我们实现这个功能吗?接下来小编就简单介绍下集中如何定时执行我们的自动化测试用例程序。 Jenkins 说到定时任务,肯定有人想到jenkins,没错,jenkins是一款持续集成的工具,其中里面就有一个小功能构建定时器,可以很好的帮助我们实现这个功能。 使用方法 1.通过进入到对应的测试项目内中,然后点击configure(配置)进入其页面中。 2.配置页面中的Build Trigger...
-
- 面试如何正确谈薪?——软件测试圈03-26金三银四马上来了,又是一波离职高峰,很多小伙伴已经开始投身跳槽的准备中了。大家选择跳槽无非是想增加自己的工资收入,所以面试过程中的谈薪环节就显得尤为重要,谈的好与不好,未来整个的薪资水平都可能受影响。那面试中,当问到“你的期望薪资是多少?“应该如何回答呢?作为一名软件测试资深面试官,站在求职者角度,从以下3个方面聊一聊:了解市场薪资行情清楚薪酬结构面试如何谈薪1、了解市场薪资水平案例: 小柠,工作2年,上家薪资是8000,跳槽后9500,跟身边朋友和前同事相比,个人很满意。 结果入职后发现,比自己晚入职技能也不如自己的新同事,薪资却过万,顿时心里不舒服了。一般来说,跳槽涨薪可达10%-30%,...


周四起诉科技巨头微软,要求其停止对动视暴雪750亿美元的收购,指称这项交易可能会损害高性能游戏机和订阅服务的竞争。 据《华尔街日报》报道,动视暴雪首席执行官BobbyKotick表示,微软收购该游戏开发商的交易将继续进行,尽管FTC计划阻止这项交易。Kotick认为FTC的指控与事实不符,相信微软会赢得这场挑战。 IT之家了解到,这将是微软公司历史上规模最大的一笔收购交易,同时也是视频游戏行业最大的一笔交易。FTC反垄断局局长霍利·维多瓦(HollyVedova)在新闻稿中表示:“微软已经证明,其有能力、有意愿停止向游戏行业的竞争对手...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=145676&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=145676&pic=http://quan.51testing.com/ueditor/php/upload/image/20221209/1670548605390966.jpg){kind=link}
》&前面 2 篇我们知道了如何安装、进行页面元素交互,现在我们开始编写一个测试用例Cypress 提供了基于 Mocha 的语法,基本功能模块describe() 声明一个测试用例集,可包含多个 it()测试用例,也可以在嵌套测试套件 context()it() 声明一个测试用例,一个测试用例集至少有一个测试用例before() 在一个测试用例集中,只执行一次,在所有测试用例之前执行beforeEach() 在一个测试用例集中,每个测试用例前执行一次afterEach() 在一个测试用例集中,每个测试用例后执行一次after() 在一个测试用例集中,只执行一次,在所有测试用例之后执行上述 4 个方...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=693&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=693&pic=http://quan.51testing.com/ueditor/php/upload/image/20200812/1597202085881151.jpg){kind=link}
进入其页面中。 2.配置页面中的Build Trigger...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=146418&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=146418&pic=http://quan.51testing.com/ueditor/php/upload/image/20230815/1692069961147602.png){kind=link}
- 关于我们 联系我们 版权声明 广告服务 站长统计
- 建议使用IE 11.0以上浏览器,800×600以上分辨率,法律顾问:上海兰迪律师事务所 项棋律师
- 版权所有 上海博为峰软件技术股份有限公司 Copyright©51testing.com 2003-2024, 沪ICP备05003035号
- 投诉及意见反馈:webmaster@51testing.com; 业务联系:service@51testing.com021-64471599-8017

- 51testing软件测试圈微信