 12
12 13
13


- 30行代码实现图片爬虫实践——软件测试圈
一个小案例,实现爬取网站里面的图片,包括源码及实现思路。
一.还原手工操作
所谓爬取页面图片,正常人手动操作可以分为两步:
1.打开页面
2.选中图片下载到指定文件夹
用代码实现的话可以节省掉每次下载图片的操作,运行代码实现批量下载。
二 .设计代码实现
步骤一 导入相关库操作
import urllib #导入urllib包 import urllib.request#导入urllib包里的request方法 import re #导入re正则库
步骤二 定义解析页面 load_page()
这个函数实现打开传入的路径并将页面数据读取出来,实现代码,包括发送请求,打开页面,获取数据。
代码实现:
def load_page(url): request=urllib.request.Request(url)#发送url请求 response=urllib.request.urlopen(request)#打开url网址 data=response.read()#读取页面数据 return data#返回页面数据
步骤三 定义get_image()函数
首先利用正则表达式匹配图片路径并存到数组中。
其次遍历数组实现图片下载操作。
代码实现:
def get_image(html):
regx=r'http://[\S]*jpg' #定义正则匹配公式
pattern=re.compile(regx)#构造匹配模式,速度更快
get_image=re.findall(pattern,repr(html))#repr()将内容转化为字符串形式,findall列表形式展示正则表达式匹配的结果
num=1 #定义变量控制循环
for img in get_image: #定义变量遍历数组
image=load_page(img)#将图片路径传入加载函数
with open('F:\\photo\\%s.jpg'%num,'wb') as fb: #以只读方式打开图片并命名
fb.write(image) #写入内容
print('正在下载第%s张图片'%num)
num=num+1 #变量递增
print("下载完成")步骤四 函数调用
#调用函数 url='http://p.weather.com.cn/2019/10/3248439.shtml' #传入url路径 html=load_page(url)#加载页面 get_image(html)#图片下载
关键单词释义
如果第一次接触爬虫代码,相信有几个单词大家很陌生,为了方便记忆我把他们归类到一起加深印象,你也可以拿出一张白纸试着努力回忆着。
1.爬虫协议库ulrlib、urllib.request
2.正则匹配库rb
3.发送请求方法request()
4.打开页面方法urlopen()
5.读取数据方法read()
6.正则表达式-所有图片【\S】*.jpg
7.匹配模式定义compile()
8.查找匹配findall()
9.循环遍历语句 for a in b
10.打开文件 并命名 with open()... as fb
11.写到... write*()
12.输出语句 print()
到现在为止可以把我上面的代码在pycharm中打开尝试着运行起来吧!
最后,有2个报错信息汇总供参考:

1. module 'urllib' has no attribute 'requset'
定位到当行语句,发现request 单词拼写错误。
2. 没有报错,但是图片没有下载成功

重新检查代码,发现正则表达式写的有错误,记住是大写的S修改完之后看效果。

作者:桃子
来源:51Testing软件测试网原创
- 0.00 查看剩余0%
- 【留下美好印记】赞赏支持

热门文章
最新讲堂
- 推荐阅读
- 换一换
- 继微软、OpenAI、谷歌等厂商后,甲骨文加入了开发 AI 编程助理的阵营,该公司最近推出了名为 Oracle Code Assist 的工具,旨在帮助用户开发 Java 程序。 据介绍,Oracle Code Assist 以甲骨文的云端 Oracle Cloud Infrastructure(OCI)模型为基础,旨在优化 Java、SQL 程序和 OCI 平台上的应用开发流程。甲骨文强调,相关 AI 编程助理“经过多种软件库的训练”,并通过其自家的软件微调而成,用户可以使用相关模型配合甲骨文软件实现“高效编程”。▲ 图源 甲骨文官网 IT之家注意到,目前这款编程助理可以处理代码生成...

-
- 银行系统接口交易功能测试要点08-01在测试银行系统接口交易时,除了要关注系统本身的功能之外,主要需要特别注意以下内容:一、测试一些反向的案例,比如账户类型为销户、冻结,或是账户和币种不一致等情况。另外,每个系统在程序设计时,使用的分隔符不一样,在测试输入要素时一定要测当输入内容包含系统分隔符时,系统是否正常,如:竖线(|),单引号('),空格等。二、在测试新系统的时候,可以使用数据库设计手册对照着实际的数据库字段去看,要注意主键的设置、字段类型以及字段长度。这种对照表结构的测试方法比每个字段去逐一编写案例及测试更高效。在进行关联系统接口交易测试时,要注意每个系统的相关字段长度保持一致,如A系统的表结构中,户名字段长度设置...
- 测试流程如何有效落地?——软件测试圈10-09一、为什么要制定流程?先谈谈为什么要制定流程及流程对于工作拿到好结果的重要性。首先问大家五个问题:流程是什么?因人、团队、业务类型、迭代速度、资源紧张程度而异。我觉得流程是保障团队目标达成的最佳实践。为什么要有流程?没有流程会导致团队中个体各自为战,目标不统一,进度不协调,资源配给失衡而导致交付质量下降。流程能解决什么问题?保证团队大方向一致,尽可能降低由于人员能力、认知水平、资源不足、意外情况导致的项目延期或质量下降。流程能带来什么保障?保障团队中大部分人的利益不受影响和保障工作中遇到沟通或争执时可以据理力争;保障工作过程中的最佳实践可以最大程度保留并执行。如何高大上的理解流程?风险可识别+...
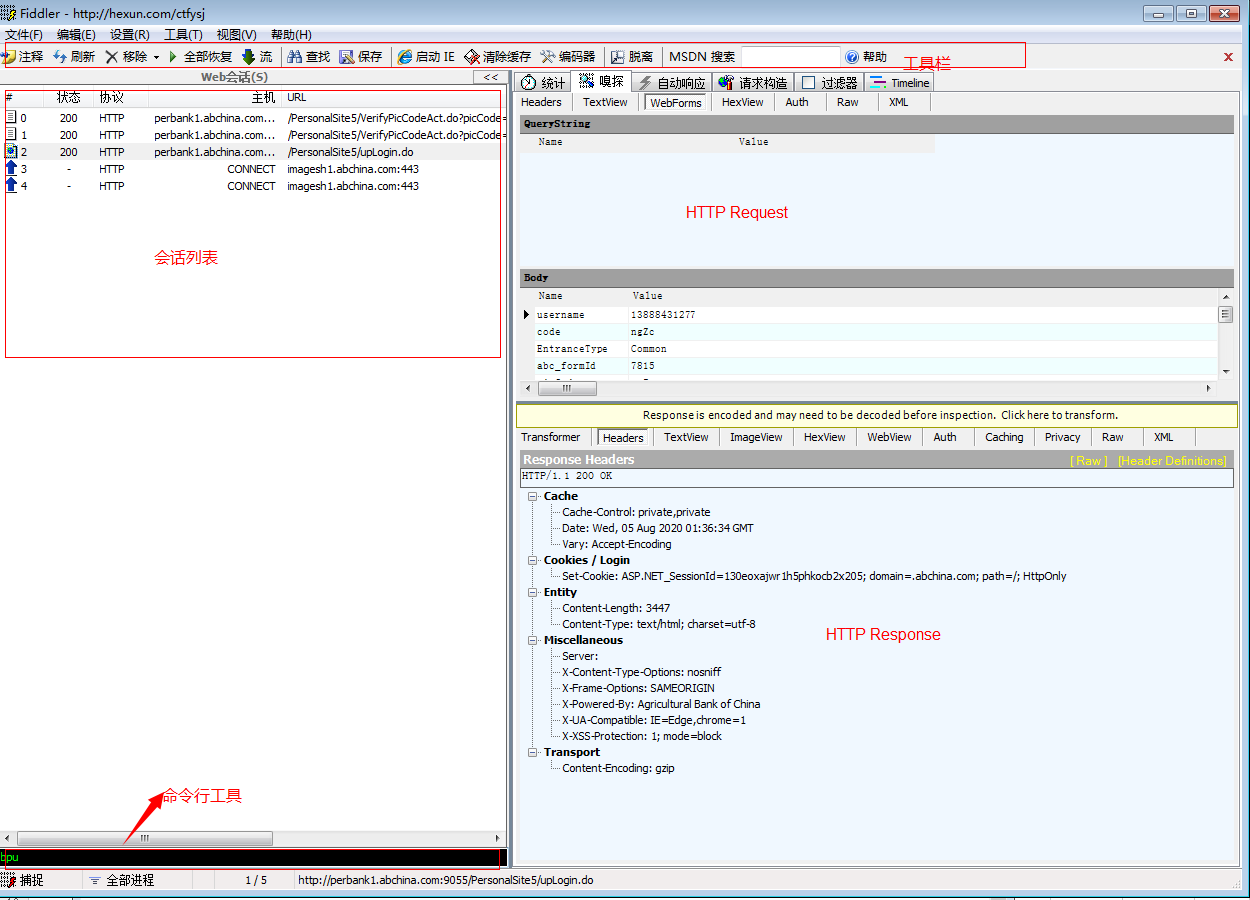
- Fiddler之日常使用简介10-23Fiddler是一款强大的抓包工具,通过改写HTTP代理,让数据经由Fiddler,借此来监控并截取到请求和返回数据。这样一来它不仅可以定位前后端问题,还能够记录客户端和服务端的所有http请求、设置断点、篡改数据等,功能非常强大。 Fiddler界面简介 Fiddler的基本界面包含:工具栏、会话列表、命令行工具、HTTP Request信息栏、HTTP Response信息栏等。 1、工具栏:快捷功能菜单,可以进行清除会话、保存会话等操作; 2、会话列表:截获的请求会话列表,每一个请求为一个会话; 3、QuickExece命令行:允许直接输入命令(如:Help、Cls、bpu)...
- 软件可靠性测试概念与应用——软件测试圈08-05一、软件可靠性测试的概念:1、软件可靠性分析方法有:失效模式影响分析法、严酷度分析法、故障树分析法、事件树分析法、潜在线路分析法等;2、可靠性测试的使用场景:在比较大的业务压力情况下进行的软件可靠性测试;3、可靠性测试过程五个步骤:确定可靠性目标、定义软件运行剖面、设计测试用例、实施可靠性测试、分析测试结果;4、可靠性预测的目的:根据软件在可靠性与测试揭示的故障情况来预测软件在正在运行时的故障和实效情况;5、可靠性测试的目的:通过受控的软件测试过程来预测软件在实际运行中的可靠性;6、可靠性测试要求:测试用例集要完全符合运行剖面的定义;7、可靠性测试条件:使用的测试用例必须满足语句覆盖;8、软件...

模型为基础,旨在优化 Java、SQL 程序和 OCI 平台上的应用开发流程。甲骨文强调,相关 AI 编程助理“经过多种软件库的训练”,并通过其自家的软件微调而成,用户可以使用相关模型配合甲骨文软件实现“高效编程”。▲ 图源 甲骨文官网 IT之家注意到,目前这款编程助理可以处理代码生成...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=146963&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=146963&pic=http://quan.51testing.com/ueditor/php/upload/image/20240513/1715572611678966.png){kind=link}
...&url=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=825&content=utf-8&sourceUrl=http://quan.51testing.com/pcQuan/pages/artDetails.html?artId=825&pic=http://quan.51testing.com/ueditor/php/upload/image/20201023/1603416015744850.png){kind=link}
- 关于我们 联系我们 版权声明 广告服务 站长统计
- 建议使用IE 11.0以上浏览器,800×600以上分辨率,法律顾问:上海兰迪律师事务所 项棋律师
- 版权所有 上海博为峰软件技术股份有限公司 Copyright©51testing.com 2003-2024, 沪ICP备05003035号
- 投诉及意见反馈:webmaster@51testing.com; 业务联系:service@51testing.com021-64471599-8017

- 51testing软件测试圈微信